Gemini Flash 2.0如何革新PDF解析?2026年成本效益深度分析

Gemini Flash 2.0 revolutionizes PDF parsing for RAG systems by offering unprecedented cost-effectiveness (≈6,000 pages per dollar) with near-perfect accuracy, making large-scale document ingestion economically viable for the first time.
原文翻译: Gemini Flash 2.0通过提供前所未有的成本效益(约每美元处理6000页)和近乎完美的准确性,彻底改变了RAG系统的PDF解析方式,首次使大规模文档摄取在经济上变得可行。
The Document Parsing Challenge
Chunking PDFs—converting them into neat, machine-readable text chunks—is a major headache for any RAG systems. Both open-source and proprietary solutions exist, but none have truly achieved the ideal combination of accuracy, scalability, and cost-effectiveness.
将 PDF 文件分块——即将其转换为整齐、机器可读的文本片段——对于任何 RAG 系统来说都是一个主要难题。虽然存在开源和专有解决方案,但都没有真正实现准确性、可扩展性和成本效益的理想结合。
The Shortcomings of Current Solutions
Open-Source Complexities
Existing end-to-end models struggle with non-trivial layouts found in real-world documents. Other open-source solutions usually involve orchestrating multiple specialized ML models for layout detection, table parsing, and markdown conversion. A case in point: NVIDIA’s nv-ingest requires spinning up a Kubernetes cluster with eight services and two A/H100 GPUs. This becomes incredibly cumbersome to orchestrate and performance remains suboptimal.
现有的端到端模型难以处理现实世界文档中复杂的布局。其他开源解决方案通常需要协调多个专门的 ML 模型,用于布局检测、表格解析和 Markdown 转换。一个典型的例子是:NVIDIA 的 nv-ingest 需要启动一个包含八个服务和两个 A/H100 GPU 的 Kubernetes 集群。这使得编排变得极其繁琐,且性能仍然不理想。
Proprietary Cost and Consistency Issues
Despite their cost, many proprietary solutions still struggle with complex layouts and achieving consistent accuracy. Furthermore, the expenses become astronomical when dealing with large datasets. For our needs – parsing hundreds of millions of pages – the price tag from vendors is simply unsustainable.
尽管成本高昂,许多专有解决方案在处理复杂布局和实现一致的准确性方面仍然存在困难。此外,在处理大型数据集时,费用变得极其高昂。对于我们的需求——解析数亿页文档——供应商的报价简直是不可持续的。
The LLM Promise and Pitfall
Large foundational models seem like a natural fit for this task. However, they have yet to prove more cost-effective than proprietary solutions, and their subtle inconsistencies pose significant challenges for real-world use. For instance, GPT-4o will often generate spurious cell artifacts within tables, making it challenging to use in production.
大型基础模型似乎是这项任务的天然选择。然而,它们尚未被证明比专有解决方案更具成本效益,而且其细微的不一致性给实际应用带来了重大挑战。例如,GPT-4o 经常在表格内生成虚假的单元格伪影,使其难以在生产中使用。
Enter Gemini Flash 2.0
While in my opinion the developer experience with Google still lags behind OpenAI, their cost-effectiveness is impossible to ignore. Unlike 1.5 Flash, which had subtle inconsistencies that made it difficult to rely on in production, our internal testing shows Gemini Flash 2.0 achieves near-perfect OCR accuracy while being still being incredibly cheap.
虽然在我看来,Google 的开发者体验仍然落后于 OpenAI,但其成本效益却不容忽视。与存在细微不一致性、难以在生产中依赖的 1.5 Flash 不同,我们的内部测试表明,Gemini Flash 2.0 实现了近乎完美的 OCR 准确性,同时仍然非常便宜。
A New Benchmark in Cost-Performance
The following table compares the cost-effectiveness of various solutions for PDF-to-Markdown conversion, measured in pages processed per dollar.
| Provider | Model | PDF to Markdown, Pages per Dollar |
|---|---|---|
| Gemini | 2.0 Flash | 🏆 ≈ 6,000 |
| Gemini | 2.0 Flash Lite | ≈ 12,000 (尚未测试) |
| Gemini | 1.5 Flash | ≈ 10,000 |
| AWS Textract | Commercial | ≈ 1000 |
| Gemini | 1.5 Pro | ≈ 700 |
| OpenAI | 4o-mini | ≈ 450 |
| LlamaParse | Commercial | ≈ 300 |
| OpenAI | 4o | ≈ 200 |
| Anthropic | claude-3-5-sonnet | ≈ 100 |
| Reducto | Commercial | ≈ 100 |
| Chunkr | Commercial | ≈ 100 |
所有 LLM 提供商的报价均基于其批量定价 [2]。
Does High Efficiency Compromise Accuracy?
Of all the steps in document parsing, table identification and extraction is the most challenging. Complex layouts, unconventional formatting, and inconsistent data quality make reliable extraction difficult.
在文档解析的所有步骤中,表格识别和提取是最具挑战性的。复杂的布局、非常规的格式和不一致的数据质量使得可靠的提取变得困难。
As a result, this is a great place to evaluate performance. We use a subset of Reducto’s rd-tablebench, which tests models against real-world challenges like poor scans, multiple languages, and intricate table structures—far beyond the tidy examples typical in academic benchmarks.
因此,这是评估性能的理想场景。我们使用了 Reducto 的 rd-tablebench 的一个子集,该基准测试模型应对现实世界挑战的能力,例如质量不佳的扫描件、多语言和复杂的表格结构——这远远超出了学术基准测试中常见的整洁示例。
The results are below (accuracy is measured with the Needleman-Wunsch algorithm).
| Provider | Model | Accuracy | Comment |
|---|---|---|---|
| Reducto | 0.90 ± 0.10 | ||
| Gemini | 2.0 Flash | 0.84 ± 0.16 | 近乎完美 |
| Anthropic | Sonnet | 0.84 ± 0.16 | |
| AWS Textract | 0.81 ± 0.16 | ||
| Gemini | 1.5 Pro | 0.80 ± 0.16 | |
| Gemini | 1.5 Flash | 0.77 ± 0.17 | |
| OpenAI | 4o | 0.76 ± 0.18 | 细微的数字幻觉 |
| OpenAI | 4o-mini | 0.67 ± 0.19 | 较差 |
| Gcloud | 0.65 ± 0.23 | ||
| Chunkr | 0.62 ± 0.21 |
Reducto's own model currently outperforms Gemini Flash 2.0 on this benchmark (0.90 vs 0.84). However, as we review the lower-performing examples, most discrepancies turn out to be minor structural variations that would not materially affect an LLM’s understanding of the table.
Reducto 自身的模型目前在此基准测试中优于 Gemini Flash 2.0(0.90 对 0.84)。然而,当我们审查表现较差的示例时,发现大多数差异是微小的结构变化,不会实质性地影响 LLM 对表格的理解。
Crucially, we’ve seen very few instances where specific numerical values are actually misread. This suggests that most of Gemini’s “errors” are superficial formatting choices rather than substantive inaccuracies. We attach examples of these failure cases below [1].
关键的是,我们很少看到具体数值被误读的情况。这表明 Gemini 的大多数“错误”是表面的格式选择,而非实质性的不准确。我们在下文附上了这些失败案例的示例 [1]。
Beyond table parsing, Gemini consistently delivers near-perfect accuracy across all other facets of PDF-to-markdown conversion. If you combine all this together, you’re left with an indexing pipeline that is exceedingly simple, scalable and cheap.
除了表格解析,Gemini 在 PDF 转 Markdown 转换的所有其他方面都始终提供近乎完美的准确性。如果将所有这些结合起来,你将得到一个极其简单、可扩展且廉价的索引管道。
Enhancing the Pipeline: Semantic Chunking
Markdown extraction is just the first step. For documents to be effectively used in RAG pipelines, they must be split into smaller, semantically meaningful chunks.
Markdown 提取只是第一步。要使文档能在 RAG 管道中有效使用,必须将其分割成更小的、具有语义意义的片段。
Recent studies have shown that using large language models (LLMs) for this task can outperform other strategies in terms of retrieval accuracy. This intuitively makes sense - LLMs excel at understanding context and identifying natural boundaries in text, making them well-suited for generating semantically meaningful chunks.
最近的研究表明,使用大型语言模型(LLM)执行此任务在检索准确性方面可以胜过其他策略。这直观上是合理的——LLM 擅长理解上下文和识别文本中的自然边界,使其非常适合生成具有语义意义的片段。
The problem? Cost. Until now, LLM-based chunking has been prohibitively expensive. With Gemini Flash 2.0, however, the game changes again - its pricing makes it feasible to use it to chunk documents at scale.
问题是什么?成本。直到现在,基于 LLM 的分块一直昂贵得令人望而却步。然而,随着 Gemini Flash 2.0 的出现,游戏规则再次改变——其定价使得大规模使用它来分块文档成为可能。
We can parse our 100+ million-page corpus for $5,000 with Gemini Flash 2.0, which is less than the monthly bill for several vector DB hosts.
我们可以用 Gemini Flash 2.0 以 5,000 美元的价格解析我们超过 1 亿页的语料库,这比几个向量数据库托管服务的月费还要低。
You could even imagine combining chunking with markdown extraction and based off our very limited testing, the results seem effective with no impact on extraction quality.
你甚至可以设想将分块与 Markdown 提取结合起来,根据我们非常有限的测试,结果似乎是有效的,且不影响提取质量。
CHUNKING_PROMPT = """\
OCR the following page into Markdown. Tables should be formatted as HTML.
Do not sorround your output with triple backticks.
Chunk the document into sections of roughly 250 - 1000 words. Our goal is
to identify parts of the page with same semantic theme. These chunks will
be embedded and used in a RAG pipeline.
Surround the chunks with <chunk> </chunk> html tags.
"""
The Bounding Box Dilemma
While markdown extraction and chunking solve many problems in document parsing, they introduce a critical limitation: the loss of bounding box information. This means users can no longer see where specific information resides in the original document. Instead citations end up pointing to a generic page number or isolated excerpts.
虽然 Markdown 提取和分块解决了解析文档中的许多问题,但它们引入了一个关键限制:边界框信息的丢失。这意味着用户无法再看到特定信息在原始文档中的位置。相反,引用最终指向一个通用的页码或孤立的摘录。
This creates a trust gap. Bounding boxes are essential for linking extracted information back to its exact location in the source PDF, providing users with confidence that the data was not hallucinated.
这造成了信任鸿沟。边界框对于将提取的信息链接回源 PDF 中的确切位置至关重要,它使用户确信数据不是幻觉产生的。
This is probably my biggest complaint with the overwhelming majority of chunking libraries.
这可能是我对绝大多数分块库最大的不满。

Our application displaying a citation within the context of the source document.
我们的应用程序在源文档上下文中显示引用。
The Unrealized Potential of LLMs for Spatial Understanding
But there's a promising idea here - LLMs have shown remarkable spatial understanding, (check out Simon Willis’s example of Gemini generating accurate bounding boxes for a densely packed flock of birds). You'd think it could be leveraged to precisely map text to its location within a document.
但这里有一个有前景的想法——LLM 已经展现出卓越的空间理解能力(参见 Simon Willis 关于 Gemini 为密集鸟群生成准确边界框的示例)。你会认为可以利用它来精确地将文本映射到其在文档中的位置。
This was big hope of ours. Unfortunately Gemini really seems to struggle on this, and no matter how we tried prompting it, it would generate wildly inaccurate bounding boxes, suggesting that document layout understanding is underrepresented in its training data. That said, this really seems like a temporary problem.
这是我们的一大希望。不幸的是,Gemini 在这方面似乎确实存在困难,无论我们如何尝试提示,它都会生成极不准确的边界框,这表明文档布局理解在其训练数据中代表性不足。不过,这似乎确实是一个暂时的问题。
If Google incorporates more document-specific data during training—or fine-tuning with a focus on document layouts— we could likely bridge this gap fairly easily. The potential is undeniable.
如果 Google 在训练期间纳入更多文档特定的数据——或者进行专注于文档布局的微调——我们很可能相当容易地弥合这一差距。其潜力是不可否认的。
GET_NODE_BOUNDING_BOXES_PROMPT = """\
Please provide me strict bounding boxes that encompasses the following text in the attached image? I'm trying to draw a rectangle around the text.
- Use the top-left coordinate system
- Values should be percentages of the image width and height (0 to 1)
{nodes}
"""

Ground truth - you can see 3 distinct bounding boxes enclosing different parts of the table.
真实情况——你可以看到 3 个不同的边界框包围着表格的不同部分。
** This is just an example prompt, we tried quite a few different methods here, but nothing seems to work (as of January 2025).
** 这只是一个示例提示,我们在这里尝试了多种不同的方法,但似乎都没有效果(截至 2025 年 1 月)。
Conclusion: The Path to Effortless Document Ingestion
By uniting these solutions, we’ve crafted an indexing pipeline that’s both elegant and economical at scale. We’ll be eventually be open sourcing our work on this, although I’m sure many others will implement similar libraries.
通过整合这些解决方案,我们构建了一个既优雅又经济的大规模索引管道。我们最终将开源我们在这方面的成果,尽管我相信许多其他人也会实现类似的库。
Importantly, once we solve these three challenges of parsing, chunking and bounding box detection we’ve effectively “solved” document ingestions into LLM’s (with caveats). This progress brings us tantalizingly close to a future where document parsing is not just efficient but practically effortless for any use case.
重要的是,一旦我们解决了解析、分块和边界框检测这三个挑战,我们实际上就“解决”了将文档摄取到 LLM 的问题(带有注意事项)。这一进展使我们无比接近一个未来,在这个未来中,文档解析不仅高效,而且对于任何用例来说都几乎不费吹灰之力。
Footnotes:
[1] Looking at failure cases. We compared the HTML outputs of Gemini vs Reducto vs the source PDF.
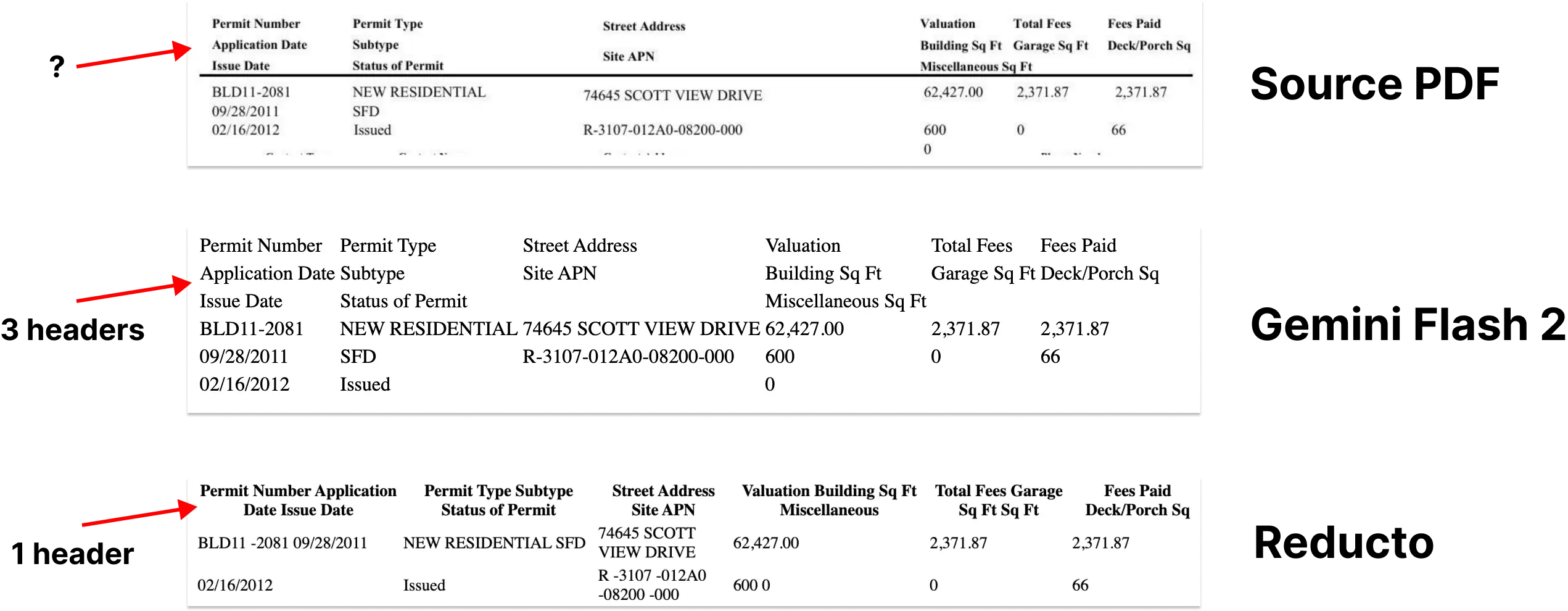
[2] I've gotten questions on this so here's how I've broken down the cost of Gemini Flash 2.0. Input Image Cost - $0.00009675 per image. Output Cost - $0.0000525 per 400 tokens. This translates to 6,379 pages per dollar. Densely packed pages may cost more, but this provides a solid estimate. For more details, check out Vertex's batch pricing page.
[2] 我收到过关于此的疑问,因此以下是我对 Gemini Flash 2.0 成本的细分。输入图像成本 - 每张图像 0.00009675 美元。输出成本 - 每 400 个令牌 0.0000525 美元。这相当于 每美元处理 6,379 页。内容密集的页面可能成本更高,但这提供了一个可靠的估算。更多详情,请查看 Vertex 的批量定价页面。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。