大语言模型如何工作?训练与推理核心技术全解析

AI Summary (BLUF)
This article provides a comprehensive technical overview of Large Language Models (LLMs), explaining the two core processes of model training (compressing internet text into parameters) and model inference (generating text from those parameters). It details the computational requirements, costs, and mechanisms behind models like Llama2 70B and ChatGPT, while also acknowledging the current limitations in fully understanding their internal workings.
原文翻译: 本文全面概述了大语言模型(LLM)的技术原理,解释了模型训练(将互联网文本压缩为参数)和模型推理(根据参数生成文本)这两个核心过程。文章详细介绍了Llama2 70B和ChatGPT等模型背后的计算需求、成本和工作机制,同时也承认了目前对其内部工作原理理解的局限性。
Demystifying Large Language Models: A Complete Technical Breakdown from Training to Inference
一、前言:理解大模型的两个核心阶段
Introduction: The Two Core Phases of Understanding LLMs
在很多关于大模型的讨论中,我们经常听到“模型推理”和“模型训练”这两个专业术语。本文将从这两个核心概念出发,深入解析大语言模型(LLM)的本质及其工作原理。
In many discussions about large models, we often hear the professional terms "model inference" and "model training." This article will start from these two core concepts to deeply analyze the essence and working principles of Large Language Models (LLMs).
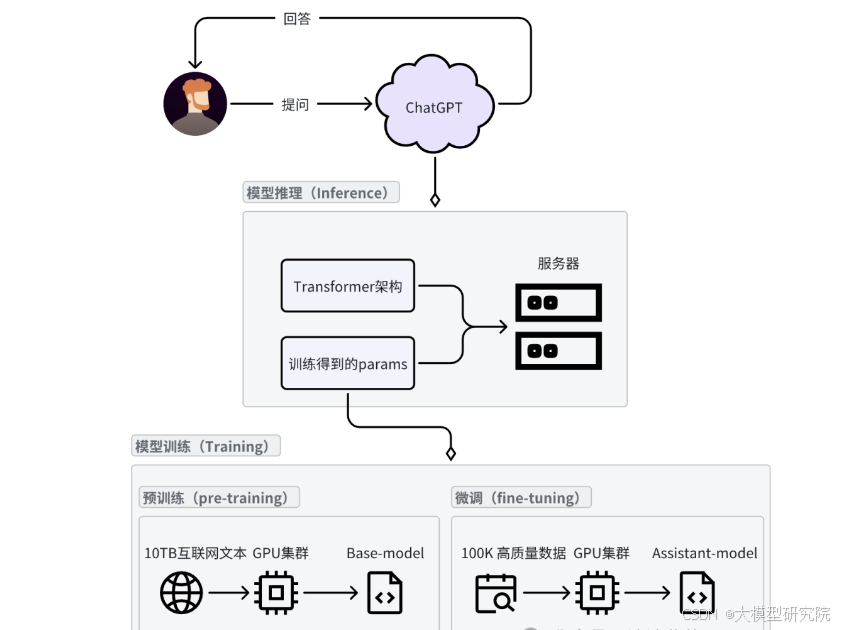
我们日常与ChatGPT等AI助手对话的过程,本质上就是模型推理的过程。这个过程消耗的GPU和服务器资源由用户并发量决定,通常远小于模型训练阶段的需求。模型推理就是在服务器上运行Transformer架构,并加载训练得到的海量参数。模型的规模通常由其参数数量决定,例如DeepSeek-R1的671B版本,就是指该模型拥有6710亿个参数。
Our daily interactions with AI assistants like ChatGPT are essentially the process of model inference. The GPU and server resources consumed by this process are determined by user concurrency and are typically much lower than the requirements of the model training phase. Model inference involves running the Transformer architecture on servers and loading the massive parameters obtained from training. The scale of a model is usually determined by its number of parameters. For example, the DeepSeek-R1 671B version indicates that the model possesses 671 billion parameters.
获取这些模型参数是整个流程的关键,主要分为两个阶段:预训练与微调。 预训练阶段将互联网上的海量文本数据输入到强大的GPU集群中进行“炼丹”,最终得到一个基础模型。然而,这个阶段得到的基础模型并不具备对话能力,它只是将互联网语料库的知识压缩存储在自己的参数中。微调阶段则通过提供高质量的一问一答格式数据,由人工专家标注,将基础模型训练成能够进行智能对话的助手。
Acquiring these model parameters is the key to the entire process, primarily divided into two stages: pre-training and fine-tuning. The pre-training stage involves feeding massive amounts of text data from the internet into powerful GPU clusters for "training," ultimately yielding a base model. However, the base model obtained at this stage does not possess conversational abilities; it merely compresses and stores the knowledge from the internet corpus within its parameters. The fine-tuning stage then transforms this base model into an intelligent conversational assistant by providing high-quality question-and-answer format data, annotated by human experts.
由此,一个像ChatGPT这样功能强大的大语言模型便诞生了!
Thus, a powerful large language model like ChatGPT is born!
二、LLM推理:模型如何运行
LLM Inference: How Models Run
以Meta AI发布的Llama2 70B模型为例,这是一个拥有700亿参数的大语言模型。Llama2系列包括了70亿、130亿、340亿和700亿参数等多个版本,其中700亿是规模最大的一个。
Taking the Llama2 70B model released by Meta AI as an example, this is a large language model with 70 billion parameters. The Llama2 series includes several versions with 7B, 13B, 34B, and 70B parameters, with the 70B version being the largest in scale.
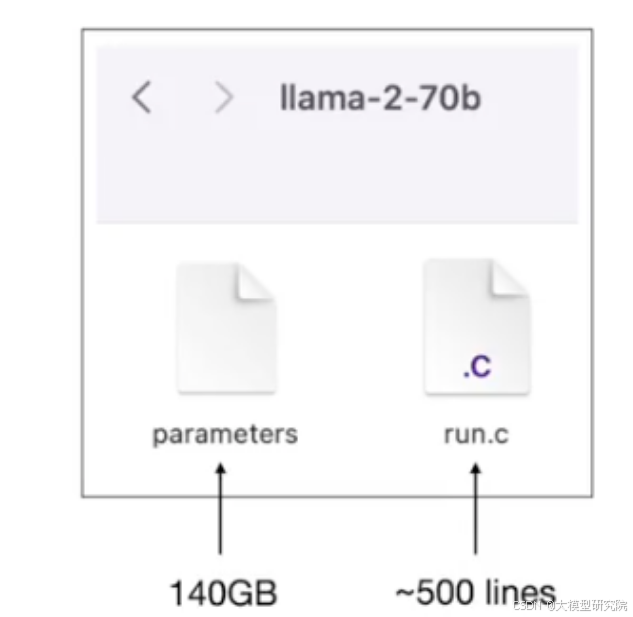
从技术实现角度看,Llama2 70B模型本质上可以简化为您计算机上的两个文件:
- 参数文件:存储神经网络所有权重参数的文件。对于这个700亿参数的模型,假设每个参数使用float16类型(占2字节),那么该文件大小约为140GB。
- 运行文件:包含运行神经网络架构代码的文件。这段代码可以用C、Python等任何语言编写,例如,一个约500行的C程序就足以加载参数并执行模型的前向传播。
From a technical implementation perspective, the Llama2 70B model can essentially be simplified to two files on your computer:
- Parameter File: A file storing all the weight parameters of the neural network. For this 70B parameter model, assuming each parameter uses the float16 type (occupying 2 bytes), the file size is approximately 140GB.
- Run File: A file containing the code to run the neural network architecture. This code can be written in any language like C, Python, etc. For instance, a C program of about 500 lines is sufficient to load the parameters and execute the model's forward propagation.
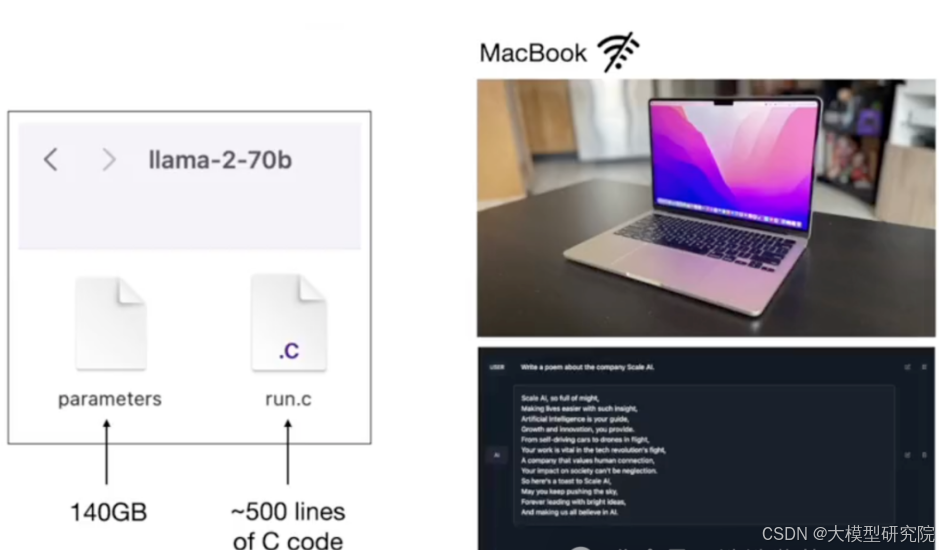
您只需要这两个文件和一个如MacBook的计算机,就拥有了一个完整的、可离线运行的大模型工具包。无需连接互联网,编译运行文件后,即可得到一个可执行文件,加载参数并与模型交互,例如让它创作一首诗歌。
You only need these two files and a computer like a MacBook to have a complete, offline-capable large model toolkit. Without an internet connection, after compiling the run file, you obtain an executable that loads the parameters and interacts with the model, for example, asking it to compose a poem.
那么,核心问题来了:这些关键的模型参数从何而来?运行文件的架构和算法是公开的,但赋予模型“智能”的正是这些通过复杂过程获得的参数。
So, the core question arises: where do these crucial model parameters come from? The architecture and algorithm of the run file are public, but what gives the model its "intelligence" are precisely these parameters obtained through a complex process.
三、LLM训练:参数的获取与“知识压缩”
LLM Training: Parameter Acquisition and "Knowledge Compression"
获取模型参数的过程,即模型训练,远比之前描述的模型推理复杂得多。模型推理只是在本地运行已训练好的模型,而模型训练是一个计算量极其庞大的过程。简而言之,模型训练可以理解为对海量互联网文本信息的一种有损压缩。
The process of acquiring model parameters, i.e., model training, is far more complex than the previously described model inference. Model inference merely runs the already-trained model locally, whereas model training is an immensely computationally intensive process. In simple terms, model training can be understood as a form of lossy compression of massive amounts of internet text information.
以开源的Llama2 70B为例,其训练方式是公开的。主要步骤包括:
- 数据收集:从互联网爬取约10TB的文本数据。
- 计算资源:配置一个由大约6000个高性能GPU组成的集群。
- 训练过程:在GPU集群上运行约12天,耗资约200万美元,最终“压缩”得到模型参数文件。
Taking the open-source Llama2 70B as an example, its training method is public. The main steps include:
- Data Collection: Scraping approximately 10TB of text data from the internet.
- Computational Resources: Configuring a cluster consisting of about 6000 high-performance GPUs.
- Training Process: Running on the GPU cluster for about 12 days, costing approximately $2 million, ultimately "compressing" to obtain the model parameter file.

这种“压缩”与ZIP等无损压缩不同,它是一种有损压缩。模型并非完整记忆原文,而是学习文本中的统计规律与知识脉络。对于ChatGPT、Claude等顶尖模型,其训练数据和计算成本可能是上述数字的十倍甚至更多,这解释了为何其训练成本高达数千万乃至数亿美元。
This "compression" differs from lossless compression like ZIP; it is a form of lossy compression. The model does not memorize the original text verbatim but learns the statistical patterns and knowledge structure within the text. For top-tier models like ChatGPT and Claude, their training data and computational costs might be ten times or even more than the figures mentioned above, explaining why their training costs can reach tens of millions or even hundreds of millions of dollars.
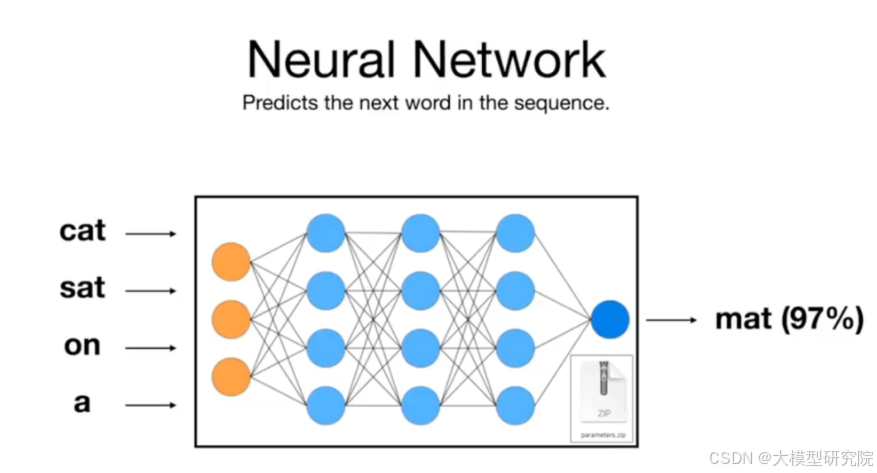
那么,神经网络在训练中具体学习什么任务呢?其核心目标是预测文本序列中的下一个词(Next Token Prediction)。 例如,给定输入“cat sat on a”,模型需要预测下一个高概率的词,如“mat”。从数学上看,预测能力的提升与数据压缩效率紧密相关。因此,通过优化模型在数十亿甚至数万亿个此类预测任务上的表现,它被迫在其参数中编码了大量关于语言结构和世界知识的信息。
So, what specific task does the neural network learn during training? Its core objective is to predict the next token in a text sequence (Next Token Prediction). For example, given the input "cat sat on a", the model needs to predict the next high-probability token, such as "mat". Mathematically, the improvement in prediction capability is closely related to data compression efficiency. Therefore, by optimizing the model's performance on billions or even trillions of such prediction tasks, it is forced to encode a vast amount of information about linguistic structure and world knowledge within its parameters.
四、LLM的“梦境”:推理时的内容生成
LLM "Dreams": Content Generation During Inference
当我们运行训练好的模型进行推理时,过程非常简单:模型根据当前输入预测下一个词,我们采样选择该词,将其追加到输入中,再预测下一个词,如此循环。这个过程就像让模型在其训练数据所构成的“知识海洋”中“梦游”。
When we run a trained model for inference, the process is straightforward: the model predicts the next token based on the current input, we sample and select that token, append it to the input, predict the next token, and repeat. This process is like letting the model "sleepwalk" through the "ocean of knowledge" formed by its training data.
由于模型是基于网页内容训练的,它可以自由地生成类似其训练数据分布的新内容。例如,它可能会生成:
- 类似Java代码的“梦境”
- 模仿亚马逊产品描述的“梦境”
- 类似维基百科文章的“梦境”
Since the model is trained on web content, it can freely generate new content that resembles the distribution of its training data. For example, it might generate:
- "Dreams" resembling Java code
- "Dreams" imitating Amazon product descriptions
- "Dreams" similar to Wikipedia articles

以产品描述为例,模型可能会生成标题、作者、ISBN号等元素,但这些信息很可能是它根据学习到的模式“幻觉”出来的,例如那个ISBN号几乎肯定不存在。它只是在模仿“ISBN:”后面通常跟随的数字格式。另一方面,对于“黑鼻鲑鱼”这种真实存在的鱼,模型生成的描述可能大致正确,因为它从训练数据中整合了相关知识,而非直接复制某段原文。
Taking a product description as an example, the model might generate elements like a title, author, ISBN, etc., but this information is likely "hallucinated" based on learned patterns. For instance, that ISBN number almost certainly does not exist. It is merely imitating the numerical format that typically follows "ISBN:". On the other hand, for a real fish like the "blacknose dace", the description generated by the model might be roughly correct because it has integrated relevant knowledge from its training data, rather than directly copying a specific original passage.
因此,模型生成的内容是“记忆”(训练数据的压缩整合)与“创造”(基于模式的生成)的混合体。我们无法精确区分其中哪些部分是绝对真实的,哪些是“幻觉”。这种能力使LLM能够生成多样化的文本,但也意味着其输出需要谨慎的验证与核查。
Therefore, the content generated by the model is a mixture of "memory" (compressed integration of training data) and "creation" (pattern-based generation). We cannot precisely distinguish which parts are absolutely factual and which are "hallucinations." This capability enables LLMs to generate diverse text, but it also means their outputs require careful verification and scrutiny.
五、工作原理探秘:我们真的理解Transformer吗?
How Do They Work? Do We Truly Understand Transformers?
Transformer架构的数学运算流程是清晰且完全可追溯的,下图展示了其核心结构。
The mathematical operation flow of the Transformer architecture is clear and fully traceable. The diagram below shows its core structure.
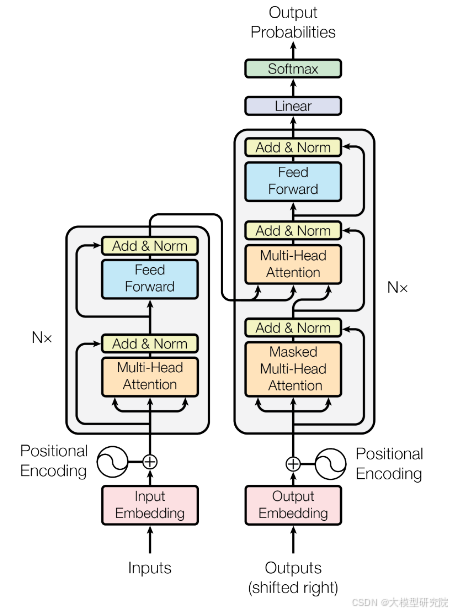
然而,真正的挑战在于:虽然我们知道如何通过梯度下降等算法优化这千亿参数,使其在“下一个词预测”任务上表现得更好,但我们并不完全理解这些参数具体是如何协同工作来编码和运用知识的。LLM建立了一个奇特、不完美且有些“怪异”的知识库。
However, the real challenge lies in this: although we know how to optimize these hundreds of billions of parameters using algorithms like gradient descent to perform better on the "next token prediction" task, we do not fully understand how these parameters specifically work together to encode and utilize knowledge. LLMs establish a peculiar, imperfect, and somewhat "weird" knowledge base.
一个著名的例子是“逆转诅咒”。你可以询问GPT-4“汤姆·克鲁斯的母亲是谁?”,它会正确回答“玛丽·李·菲弗”。但如果你问“玛丽·菲弗的儿子是谁?”,它可能回答不知道。这种知识似乎是单向存储的,并非像传统数据库那样可以任意角度查询。这揭示了模型内部知识表征的局限性。
A famous example is the "reversal curse." You can ask GPT-4 "Who is Tom Cruise's mother?" and it will correctly answer "Mary Lee Pfeiffer." But if you ask "Who is Mary Pfeiffer's son?" it might say it doesn't know. This knowledge seems to be stored unidirectionally, not queryable from any angle like a traditional database. This reveals the limitations of the model's internal knowledge representation.
归根结底,当前的大语言模型更像是基于大规模经验优化产生的“黑箱”产物,与我们能够完全理解其每个部件工作原理的工程产品(如汽车)不同。尽管“可解释性AI”领域正致力于解读神经网络,但我们目前主要仍通过输入输出行为来评估和理解它们。
Ultimately, current large language models are more like "black box" products arising from large-scale empirical optimization, different from engineering products like cars where we understand the working principle of every component. Although the field of "Explainable AI (XAI)" is dedicated to interpreting neural networks, we currently primarily evaluate and understand them through their input-output behavior.
六、总结:构建大模型的全景图
Summary: The Panorama of Building Large Models
构建像ChatGPT这样的大模型主要包含两个成本差异巨大的阶段:
Building a large model like ChatGPT primarily involves two stages with vastly different costs:
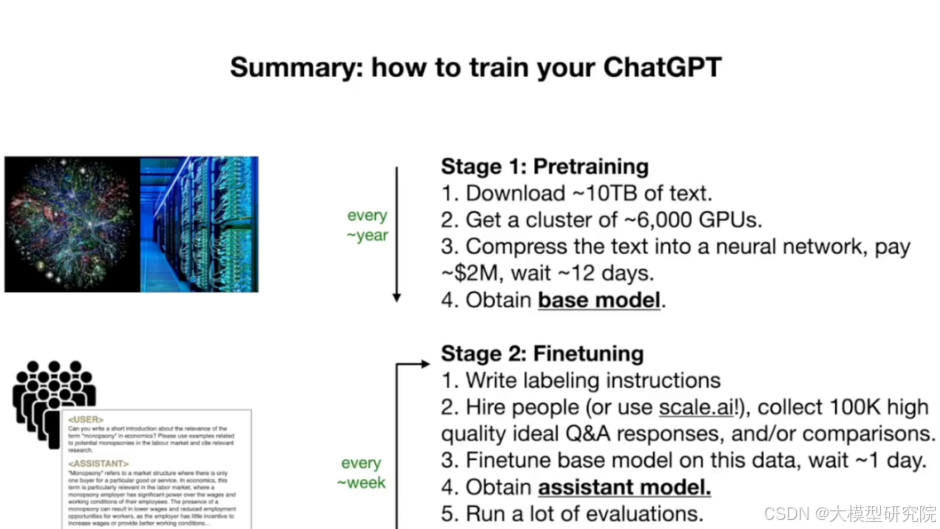
- 预训练:从互联网收集海量文本,使用昂贵的GPU集群(成本可达数百万美元)进行训练,得到“基础模型”。此过程计算量极大,成本高昂,公司通常每年或每几个月进行一次。
- 微调:基于高质量的人工标注问答数据(例如10万个样本),对基础模型进行指令调优,使其成为有用的助手。此阶段成本相对较低,可能只需数天即可完成,因此公司可以更频繁地进行(每周甚至每天)。
- Pre-training: Collect massive text from the internet and train it using expensive GPU clusters (costing up to millions of dollars) to obtain a "base model." This process is computationally intensive and costly, typically undertaken by companies once a year or every few months.
- Fine-tuning: Perform instruction tuning on the base model using high-quality human-annotated Q&A data (e.g., 100,000 samples) to turn it into a useful assistant. This stage is relatively low-cost, potentially completed in just a few days, allowing companies to iterate more frequently (weekly or even daily).
此外,还有一个可选的第三阶段——基于人类反馈的强化学习,通过让模型学习人类对回答的偏好排序,来进一步提升回答质量和安全性。
Furthermore, there is an optional third stage—Reinforcement Learning from Human Feedback (RLHF)—which further improves answer quality and safety by having the model learn human preferences for ranking responses.
Meta发布的Llama 2系列就区分了“基础模型”和“聊天助手模型”。前者是预训练的产物,后者是微调后的结果。开源基础模型允许社区在其之上进行自己的微调创新。
The Llama 2 series released by Meta distinguishes between the "base model" and the "chat assistant model." The former is the product of pre-training, the latter the result of fine-tuning. Open-source base models allow the community to innovate with their own fine-tuning on top of them.
(编者注:原文后续部分包含具体的学习路线与资料推广。作为技术博客的核心解析部分,本文聚焦于对LLM训练与推理机制的技术性阐述。关于学习路径,建议读者参考官方文档、权威课程及开源项目。)
(Editor's Note: The subsequent part of the original text contained a specific learning roadmap and promotional material for resources. As the core analytical part of a technical blog, this article focuses on the technical explanation of LLM training and inference mechanisms. For learning paths, readers are advised to refer to official documentation, authoritative courses, and open-source projects.)
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。