OpenViking如何解决AI Agent长期记忆难题?2026年开源方案解析

OpenViking is an open-source context database that provides a lightweight, efficient, and low-cost long-term memory solution for AI Agents like OpenClaw, addressing core pain points such as low task completion rates, fragmented memory, high token costs, and cross-scenario collaboration difficulties.
原文翻译: OpenViking是一个开源上下文数据库,为OpenClaw等AI Agent提供轻量、高效、低成本的长期记忆解决方案,解决了任务完成率低、记忆碎片化、Token成本高和跨场景协作困难等核心痛点。
项目仓库|github.com/volcengine/OpenViking
引言:AI Agent 的“记忆”挑战
随着 AI Agent 技术的快速发展,像 OpenClaw 这样的框架赋予了智能体“感知”和“操作”现实世界的能力,极大地拓展了自动化任务的边界。然而,一个普遍且关键的瓶颈也随之凸显:长期记忆的缺失。智能体在长周期、多步骤的任务中,常常“遗忘”关键的上下文信息,这不仅削弱了其自主性,也限制了其在复杂场景下的实际应用价值。本文将深入探讨这一挑战,并介绍开源项目 OpenViking 如何作为 OpenClaw 的“外挂记忆体”,提供一套高效、低成本的长程记忆解决方案。
With the rapid advancement of AI Agent technology, frameworks like OpenClaw have empowered agents with the ability to “perceive” and “operate” in the real world, significantly expanding the boundaries of automated tasks. However, a widespread and critical bottleneck has also emerged: the lack of long-term memory. Agents often “forget” crucial contextual information during long-cycle, multi-step tasks, which not only undermines their autonomy but also limits their practical value in complex scenarios. This article delves into this challenge and introduces the open-source project OpenViking, which serves as an “external memory module” for OpenClaw, providing an efficient, low-cost long-term memory solution.
OpenClaw 的长程记忆困局
OpenClaw 近期在开发者社区中备受瞩目。它赋予了 Agent “看见”和“操作”的能力,开启了自动化复杂任务的想象空间。但随着交互加深,一个普遍的“上下文管理困境”也随之浮现:Agent 常常遗忘之前交代过的信息。正如一些开发者在深入体验后指出的,尽管 OpenClaw 备受赞誉,但在长期使用中,“它完全忘记了我给它的 API 密钥”。这种不稳定的“记忆”不仅影响了 Agent 的自主性,也暴露了当前 AI Agent 在长周期任务中管理海量、动态上下文的普遍难题。
OpenClaw has recently garnered significant attention in the developer community. It empowers agents with the ability to “see” and “operate,” opening up possibilities for automating complex tasks. However, as interactions deepen, a common “context management dilemma” emerges: the agent often forgets previously provided information. As some developers noted after in-depth experience, despite OpenClaw’s acclaim, during prolonged use, “it completely forgot the API key I gave it.” This unstable “memory” not only affects the agent’s autonomy but also highlights the widespread challenge current AI Agents face in managing massive, dynamic contexts over long-term tasks.
根据社区的真实反馈和我们的深入测试,OpenClaw 原生的 memory-core 模块在处理长程任务时,存在几个核心痛点:
Based on real community feedback and our in-depth testing, OpenClaw’s native memory-core module exhibits several core pain points when handling long-term tasks:
- 任务完成率偏低: 单次对话随着对话轮次增加,原生记忆机制难以有效支撑复杂的上下文依赖,导致记忆出错,回复结果不尽如人意。
Low Task Completion Rate: As the number of dialogue turns increases in a single conversation, the native memory mechanism struggles to effectively support complex contextual dependencies, leading to memory errors and unsatisfactory responses.
- 记忆碎片化,检索低效: 随着使用时间增加,记忆信息记录杂乱,且是平铺式检索,在需要时难以高效、精准地检索到关键上下文。
Fragmented Memory, Inefficient Retrieval: Over time, memory records become disorganized. Coupled with flat retrieval methods, it becomes difficult to efficiently and accurately retrieve key context when needed.
- Token 成本激增: 为了维持记忆,原生模式需要将大量历史信息塞入上下文窗口,这直接导致输入 Token 数量爆炸式增长,使用成本居高不下。
Skyrocketing Token Costs: To maintain memory, the native mode requires cramming large amounts of historical information into the context window, leading directly to an explosive increase in input token count and persistently high usage costs.
- 跨场景协作困难: 在多会话、跨场景的协作任务中,Agent 间的记忆孤岛问题尤为突出,关键信息无法流转,导致协作失败。
Difficulty in Cross-Scenario Collaboration: In collaborative tasks involving multiple sessions and scenarios, the memory silo problem between agents is particularly acute. Key information cannot flow, leading to collaboration failure.
这些问题共同构成了长程 Agent 落地的一道高墙。
These issues collectively form a significant barrier to the practical implementation of long-term agents.
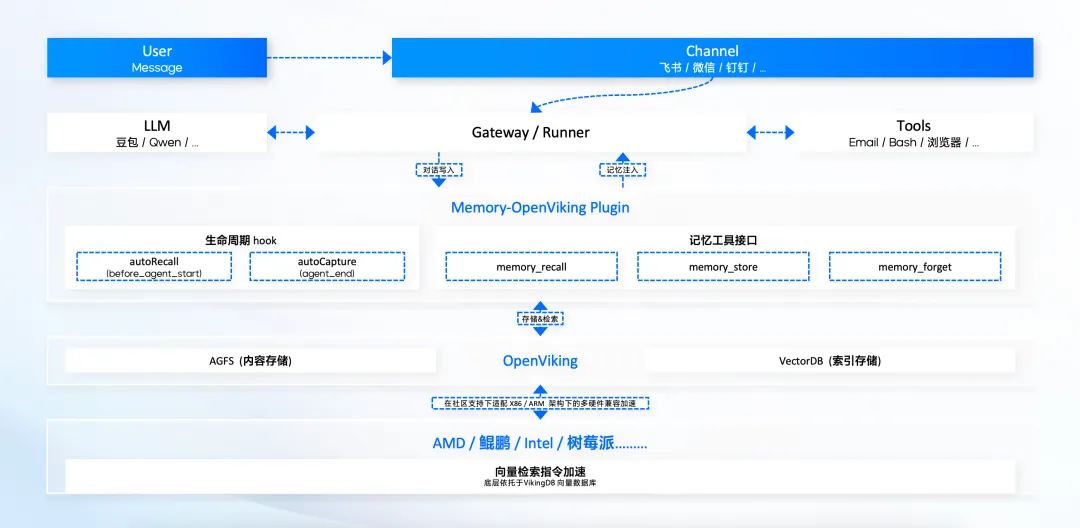
OpenViking:文件系统式的上下文数据库方案
作为发布仅一个月就斩获 4.5k Github Star 的开源项目,OpenViking 已然成为社区热议的全新品类——面向 AI Agent 的上下文数据库。其核心价值正是为解决上下文工程中长期记忆的核心痛点而生。它并非要取代 OpenClaw,而是作为其强大的“外挂记忆体”,提供跨应用、跨平台、跨智能体的通用记忆和上下文能力。
As an open-source project that garnered 4.5k GitHub Stars within just one month of release, OpenViking has quickly become a hotly discussed new category in the community—a context database for AI Agents. Its core value lies in addressing the fundamental pain points of long-term memory in context engineering. It is not intended to replace OpenClaw but to serve as a powerful “external memory module,” providing universal memory and context capabilities across applications, platforms, and agents.
OpenViking 的核心价值在于:
The core value of OpenViking lies in:
- “虚拟文件系统”范式: 创新地以文件系统的方式来组织和管理 Agent 的上下文,无论是记忆、资源还是技能,皆可结构化存储,告别碎片化,让用户可视化管理 Agent 记忆。
“Virtual File System” Paradigm: It innovatively organizes and manages an agent’s context using a file system approach. Memories, resources, and skills can all be stored in a structured manner, eliminating fragmentation and enabling users to visually manage agent memory.
- 轻量高效,成本极低: 通过分层上下文供给和高效的检索机制,仅在必要时加载信息,从根本上解决了输入 Token 消耗巨大的问题。
Lightweight, Efficient, Extremely Low Cost: Through layered context provisioning and efficient retrieval mechanisms, information is loaded only when necessary, fundamentally solving the problem of massive input token consumption.
- 插件化无缝集成: 作为 OpenViking Plugin,它可以轻松接入 OpenClaw,开发者无需对框架核心代码进行任何改造,即可享受强大的长程记忆能力。
Seamless Plugin Integration: As the OpenViking Plugin, it can be easily integrated into OpenClaw. Developers can enjoy powerful long-term memory capabilities without modifying any of the framework’s core code.
简而言之,OpenViking 为 OpenClaw 提供了一个轻量、高效且低成本的“长程记忆解决方案”。
In short, OpenViking provides OpenClaw with a lightweight, efficient, and low-cost “long-term memory solution.”
效果与成本的双重飞跃:量化评估
为了量化 OpenViking 带来的提升,我们在严格控制的实验环境下,用公开评测集进行了一场全面的对比测试。
To quantify the improvement brought by OpenViking, we conducted a comprehensive comparative test under strictly controlled experimental conditions using a public evaluation dataset.
实验环境设置:
Experimental Environment Setup:
- 测试集:LoCoMo10 (https://github.com/snap-research/locomo),专注于长程对话理解与记忆,我们移除了其中无真值的 category5,共计 1540 条有效测试用例。
Test Set: LoCoMo10 (https://github.com/snap-research/locomo), focused on long-context dialogue understanding and memory. We removed category5 which lacks ground truth, resulting in 1540 valid test cases.
- 实验组: 为帮助用户找到最佳记忆方案,我们设立了四组对照实验,涵盖了不同的记忆方案组合,包括是否启用 OpenClaw 原生的 memory-core。
Experimental Groups: To help users find the optimal memory solution, we established four control groups covering different memory scheme combinations, including whether to enable OpenClaw’s native memory-core.
- 版本信息: OpenViking 0.1.18,测试模型为 seed-2.0-code。
Version Information: OpenViking 0.1.18, tested with the seed-2.0-code model.
- 评测脚本: 采用开源评测脚本 ZaynJarvis/openclaw-eval (https://github.com/ZaynJarvis/openclaw-eval/tree/main) 保证结果的公正性。
Evaluation Script: Used the open-source evaluation script ZaynJarvis/openclaw-eval (https://github.com/ZaynJarvis/openclaw-eval/tree/main) to ensure the fairness of results.
实验数据对比:
Experimental Data Comparison:
(Note: As the original content did not provide the specific data table, this section is summarized based on the following conclusions.)
实验结论:
Experimental Conclusions:
数据结果清晰地展示了 OpenViking 在效果和成本上的双重、压倒性优势。
The data results clearly demonstrate OpenViking’s dual, overwhelming advantages in both effectiveness and cost.
- 当开启原生记忆时(与 +memory-core 组合): 相较于原生 OpenClaw,任务完成率提升 43%,而输入 token 成本剧降 91%。
When native memory is enabled (combined with +memory-core): Compared to native OpenClaw, the task completion rate increased by 43%, while the input token cost plummeted by 91%.
- 当关闭原生记忆时(与 -memory-core 组合): 相较于原生 OpenClaw,任务完成率大幅提升 49%,输入 token 成本则降低了 83%。
When native memory is disabled (combined with -memory-core): Compared to native OpenClaw, the task completion rate significantly increased by 49%, and the input token cost was reduced by 83%.
无论是否保留原生记忆,集成 OpenViking 都能为 OpenClaw 带来巨大的性能飞跃和成本节约。推荐大家保持原生开启使用,此时实际只会使用 OpenViking,memory-core 是关闭的,但 OpenClaw 原生的一些优化策略会让成本更低,效果几乎无影响。
Regardless of whether native memory is retained, integrating OpenViking brings tremendous performance leaps and cost savings to OpenClaw. It is recommended to keep the native setting enabled. In this configuration, only OpenViking is actually used (memory-core is off), but some of OpenClaw’s native optimization strategies result in even lower costs with almost no impact on effectiveness.
从“健忘”到“过目不忘”:场景化优势解析
我们模拟真实用户在使用 OpenClaw 的过程中,集成 OpenViking 前后的效果对比,帮助大家感知 OpenViking 的优势和价值。
We simulate the comparison before and after integrating OpenViking for real users of OpenClaw to help illustrate the advantages and value of OpenViking.
优势一:日常 Skill 使用经验沉淀为记忆,提升任务效率
Advantage 1: Precipitating Daily Skill Usage Experience into Memory, Improving Task Efficiency
场景: 销售小王日常会用通过 OpenClaw 调用销售数据库的检索 Skill 查询全国销售结果,用来分析产品数据。
Scenario: Salesperson Xiao Wang regularly uses OpenClaw to call a sales database retrieval Skill to query national sales results for product data analysis.
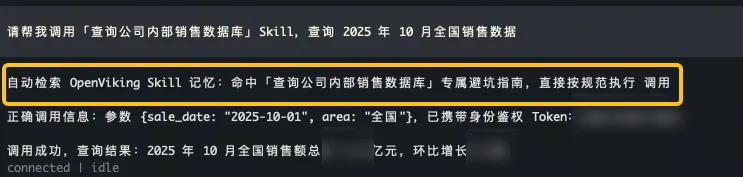
- 原生 OpenClaw 反复犯错: OpenClaw 在调用“查询公司内部销售数据库”的 Skill 时,每次都会犯同样的错误(如参数格式不对、缺少鉴权信息等),需要经过多次报错、试错才能勉强完成任务。而每次开启新对话,它都会把以前犯过的错再犯一遍。
Native OpenClaw Repeats Mistakes: When calling the “Query Internal Sales Database” Skill, OpenClaw makes the same mistakes every time (e.g., incorrect parameter format, missing authentication information). It requires multiple error reports and trial-and-error to barely complete the task. Each time a new conversation is started, it repeats the same mistakes.
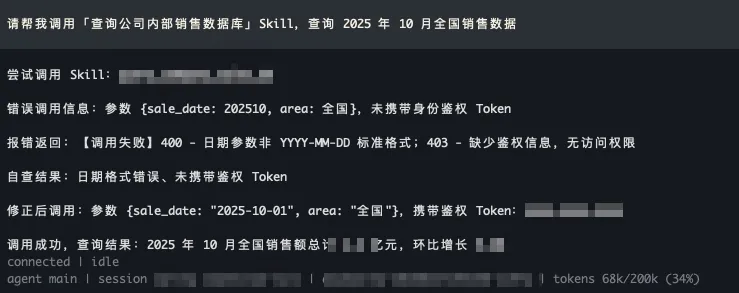
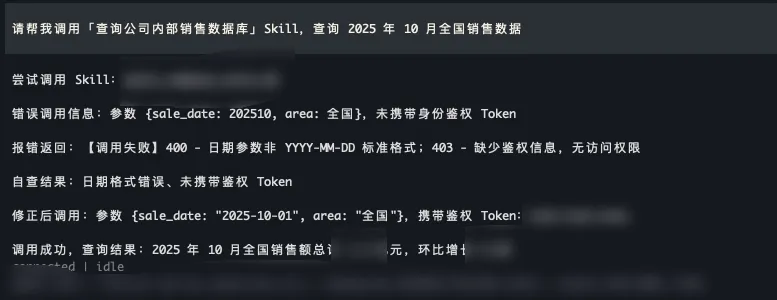
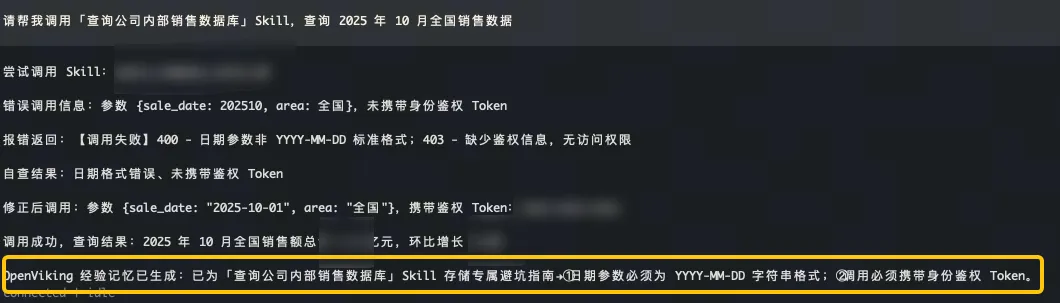
- 结合 OpenViking 越用越熟练: OpenViking 为 OpenClaw 引入了针对特定资源的经验记忆机制。当 OpenClaw 第一次成功使用某个 Skill 或克服某个工具的“坑”之后,OpenViking 会自动总结出“避坑指南”(如:该 API 时间参数必须是 ISO 格式),并将其作为该 Skill 的专属上下文记忆存储起来。下次调用时,OpenClaw 会自动检索并加载这份“经验记忆”,指导自己避开雷区,实现一次性精准调用,大幅降低了推理成本和工具报错率。
OpenClaw with OpenViking Becomes More Proficient with Use: OpenViking introduces an experience memory mechanism for specific resources to OpenClaw. After OpenClaw successfully uses a Skill for the first time or overcomes a tool’s “pitfall,” OpenViking automatically summarizes a “troubleshooting guide” (e.g., the time parameter for this API must be in ISO format) and stores it as dedicated contextual memory for that Skill. On the next call, OpenClaw automatically retrieves and loads this “experience memory,” guiding itself to avoid pitfalls and achieve accurate one-shot invocation, significantly reducing reasoning costs and tool error rates.
优势二:长程对话下的核心信息不丢失,保持记忆稳定
Advantage 2: Core Information Retention in Long Conversations, Maintaining Stable Memory
场景: 小杨会为 OpenClaw 定义工作目标,和 OpenClaw 进行各类主题的长周期对话后,让其围绕目标进行总结。
Scenario: Xiao Yang defines work objectives for OpenClaw. After engaging in long-cycle conversations on various topics with OpenClaw, he asks it to summarize based on those objectives.
- 原生 OpenClaw 金鱼记忆: 小杨在进行各种主题超过一百轮对话后,OpenClaw 开始遗忘最初设置的工作目标,导致回答不够聚焦,无法产生价值。
Native OpenClaw’s Goldfish Memory: After Xiao Yang engages in over a hundred rounds of conversation on various topics, OpenClaw begins to forget the initially set work objectives, leading to unfocused answers that fail to deliver value.

- 结合 OpenViking 越用越懂你: OpenClaw 能够始终记住对话的核心上下文。即使在百轮对话后,依然能准确调用最初设定的目标,并结合过程中的新信息进行推理,准确写出了我们在开头希望它明确的核心指标,表现出优异的“记忆一致性”。
OpenClaw with OpenViking Understands You Better Over Time: OpenClaw can consistently remember the core context of the conversation. Even after a hundred rounds of dialogue, it can still accurately recall the initially set objectives and reason by combining new information from the process. It accurately writes the core metrics we wanted it to clarify at the beginning, demonstrating excellent “memory consistency.”

![With OpenViking: Syncing
常见问题(FAQ)
OpenViking如何解决AI Agent的长期记忆问题?
OpenViking作为开源上下文数据库,为OpenClaw等AI Agent提供轻量高效的长期记忆解决方案,通过文件系统式架构解决记忆碎片化、Token成本高等核心痛点。
OpenViking相比原生记忆模块有哪些优势?
OpenViking能提升任务完成率,避免记忆碎片化,显著降低Token成本,并支持跨场景协作,解决了原生memory-core在长程任务中的多个痛点。
OpenViking如何帮助AI Agent实现跨场景协作?
OpenViking作为通用记忆体,打破Agent间的记忆孤岛,让关键信息在不同会话和场景间流转,解决了跨场景协作困难的问题。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。