什么是检索增强生成(RAG)?2026年AI大模型优化指南

Retrieval-Augmented Generation (RAG) is a technique that combines information retrieval with text generation models to enhance the factual accuracy and reliability of language models for knowledge-intensive tasks, reducing hallucinations by incorporating external knowledge sources.
原文翻译: 检索增强生成(RAG)是一种将信息检索与文本生成模型相结合的技术,通过整合外部知识源来增强语言模型在知识密集型任务中的事实准确性和可靠性,从而减少幻觉问题。
引言
通用大语言模型(LLMs)经过微调后,能够胜任多种常见任务,例如情感分析和命名实体识别。这些任务通常不需要模型具备额外的背景知识。
通用大语言模型(LLMs)经过微调后,能够胜任多种常见任务,例如情感分析和命名实体识别。这些任务通常不需要模型具备额外的背景知识。
然而,面对更复杂、知识密集型的需求时,我们需要构建能够访问外部知识源的系统来增强语言模型。这种方法能显著提升模型输出与事实的一致性,生成更可靠的答案,并有效缓解“幻觉”问题。
然而,面对更复杂、知识密集型的需求时,我们需要构建能够访问外部知识源的系统来增强语言模型。这种方法能显著提升模型输出与事实的一致性,生成更可靠的答案,并有效缓解“幻觉”问题。
什么是检索增强生成 (RAG)?
为了应对上述挑战,Meta AI 的研究人员提出了一种名为 检索增强生成(Retrieval-Augmented Generation, RAG) 的方法。RAG 将信息检索组件与文本生成模型相结合,形成一个统一的框架。该框架支持微调,并能以高效的方式更新其内部知识,无需对整个模型进行重新训练。
为了应对上述挑战,Meta AI 的研究人员提出了一种名为 检索增强生成(Retrieval-Augmented Generation, RAG) 的方法。RAG 将信息检索组件与文本生成模型相结合,形成一个统一的框架。该框架支持微调,并能以高效的方式更新其内部知识,无需对整个模型进行重新训练。
RAG 的工作原理是:接收用户输入,从一个外部知识库(如维基百科)中检索出一组相关的支撑性文档,并记录文档来源。随后,这些文档作为上下文信息,与原始的用户提示词组合,一并输入给文本生成器,从而产生最终输出。
RAG 的工作原理是:接收用户输入,从一个外部知识库(如维基百科)中检索出一组相关的支撑性文档,并记录文档来源。随后,这些文档作为上下文信息,与原始的用户提示词组合,一并输入给文本生成器,从而产生最终输出。
RAG 的核心优势与工作原理
适应动态知识
RAG 使系统能够灵活适应事实随时间变化的情况。这一点至关重要,因为传统大语言模型的参数化知识是静态的,在训练完成后便固定下来。RAG 无需重新训练模型,即可让语言模型获取最新信息,从而基于检索到的证据生成可靠的输出。
RAG 使系统能够灵活适应事实随时间变化的情况。这一点至关重要,因为传统大语言模型的参数化知识是静态的,在训练完成后便固定下来。RAG 无需重新训练模型,即可让语言模型获取最新信息,从而基于检索到的证据生成可靠的输出。
技术架构
Lewis 等人在2021年提出了一种通用的 RAG 微调范式。该范式使用预训练的序列到序列(seq2seq)模型作为参数化记忆,同时使用维基百科的密集向量索引作为非参数化记忆(通过一个神经网络预训练的检索器进行访问)。
Lewis 等人在2021年提出了一种通用的 RAG 微调范式。该范式使用预训练的序列到序列(seq2seq)模型作为参数化记忆,同时使用维基百科的密集向量索引作为非参数化记忆(通过一个神经网络预训练的检索器进行访问)。
其工作流程可概括如下:
- 检索(Retrieval):针对用户查询,从大型外部知识库中检索出最相关的文档片段。
- 增强(Augmentation):将检索到的文档作为上下文,与原始查询拼接,形成一个新的、信息更丰富的提示。
- 生成(Generation):将增强后的提示输入生成模型,产生最终答案。
其工作流程可概括如下:
- 检索(Retrieval):针对用户查询,从大型外部知识库中检索出最相关的文档片段。
- 增强(Augmentation):将检索到的文档作为上下文,与原始查询拼接,形成一个新的、信息更丰富的提示。
- 生成(Generation):将增强后的提示输入生成模型,产生最终答案。
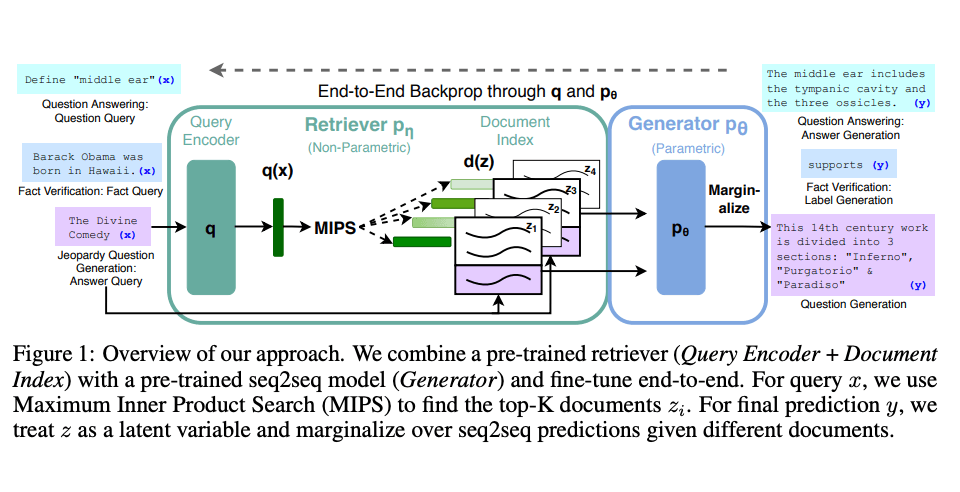
图片援引自: Lewis et el. (2021)
应用表现与影响
RAG 在多项知识密集型问答基准测试中展现了卓越的性能,包括:
- Natural Questions
- WebQuestions
- CuratedTrec
RAG 在多项知识密集型问答基准测试中展现了卓越的性能,包括:
- Natural Questions
- WebQuestions
- CuratedTrec
在 MS-MARCO 和 Jeopardy 问题集上的测试表明,RAG 生成的答案更具事实性、更具体、也更多样化。此外,在 FEVER 事实验证任务中,采用 RAG 也带来了更好的结果。
在 MS-MARCO 和 Jeopardy 问题集上的测试表明,RAG 生成的答案更具事实性、更具体、也更多样化。此外,在 FEVER 事实验证任务中,采用 RAG 也带来了更好的结果。
这些成果证明,RAG 是一种切实可行的方案,能够有效增强语言模型在知识密集型任务中的输出质量。
这些成果证明,RAG 是一种切实可行的方案,能够有效增强语言模型在知识密集型任务中的输出质量。
现代实践与工具
近年来,基于检索器的方法日益流行,常与 ChatGPT 等主流大语言模型结合使用,以提升其能力边界和事实一致性。开发者可以利用诸如 LangChain 等框架轻松构建 RAG 应用。
近年来,基于检索器的方法日益流行,常与 ChatGPT 等主流大语言模型结合使用,以提升其能力边界和事实一致性。开发者可以利用诸如 LangChain 等框架轻松构建 RAG 应用。
例如,LangChain 文档中提供了一个简单的示例,演示了如何结合检索器与大语言模型来回答问题,并引用知识来源。
例如,LangChain 文档中提供了一个简单的示例,演示了如何结合检索器与大语言模型来回答问题,并引用知识来源。
结论
检索增强生成(RAG)通过将动态信息检索与大语言模型的强大生成能力相结合,为解决大模型“幻觉”和知识滞后问题提供了强有力的范式。它不仅是学术研究的热点,也正迅速成为构建可靠、可信、知识可更新的 AI 应用的核心技术之一。
检索增强生成(RAG)通过将动态信息检索与大语言模型的强大生成能力相结合,为解决大模型“幻觉”和知识滞后问题提供了强有力的范式。它不仅是学术研究的热点,也正迅速成为构建可靠、可信、知识可更新的 AI 应用的核心技术之一。
本文内容基于并改编自 Prompt Engineering Guide,旨在提供清晰的技术概述。
常见问题(FAQ)
RAG技术如何解决大语言模型的幻觉问题?
RAG通过检索外部知识库获取最新事实证据,将检索到的文档作为上下文与用户查询结合后输入生成模型,从而基于可靠信息生成答案,显著减少模型凭空编造的情况。
RAG相比传统大语言模型有什么核心优势?
RAG的核心优势在于能动态适应知识更新,无需重新训练模型即可获取最新信息,解决了传统大语言模型参数化知识静态固化的问题,特别适合事实会随时间变化的场景。
如何在实际应用中快速搭建RAG系统?
开发者可以使用LangChain等现代框架,结合检索器与大语言模型(如ChatGPT)构建RAG应用,框架提供了从知识检索到答案生成的完整工具链,大大降低了实现门槛。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。