大型语言模型(LLM)是什么?技术原理、应用场景与未来挑战详解

AI Summary (BLUF)
Large Language Models (LLMs) are advanced AI systems trained on massive text datasets to understand, generate, and manipulate human language. They power applications like machine translation, content creation, chatbots, and sentiment analysis, but face challenges including high training costs, data biases, and ethical concerns.
原文翻译: 大型语言模型(LLMs)是基于海量文本数据训练的高级人工智能系统,用于理解、生成和处理人类语言。它们驱动着机器翻译、内容创作、聊天机器人和情感分析等应用,但也面临训练成本高、数据偏见和伦理问题等挑战。
A Comprehensive Analysis of Large Language Models (LLMs): Technology, Applications, and Challenges
大家好,我是 Luga。今天,我们将深入探讨人工智能(AI)生态中的一项核心技术——大型语言模型(Large Language Model, LLM)。
Hello everyone, I'm Luga. Today, we will delve into a core technology within the artificial intelligence (AI) ecosystem—Large Language Models (LLMs).
在过去的十年里,人工智能领域取得了令人瞩目的突破,其中自然语言处理(NLP)是一个至关重要的子领域。NLP致力于开发处理和理解人类语言文本数据的技术与方法。
Over the past decade, the field of artificial intelligence has achieved remarkable breakthroughs, with Natural Language Processing (NLP) being a crucial subfield. NLP focuses on developing technologies and methods for processing and understanding human language text data.
NLP的发展使机器能够更好地理解和处理人类语言,从而实现更智能、更自然的交互。其应用涵盖文本分类、情感分析、命名实体识别、机器翻译、问答系统等多个任务和领域。
The advancement of NLP enables machines to better understand and process human language, facilitating more intelligent and natural interactions. Its applications span numerous tasks and domains, including text classification, sentiment analysis, named entity recognition, machine translation, and question-answering systems.
NLP技术的核心在于构建能够理解和表达语言的模型。大型语言模型(LLM)是其中的一项关键技术。LLM基于深度神经网络架构,通过在海量文本语料库上进行学习,能够捕捉单词、短语和句子之间的语义与语法规律。这使得LLM能够自动生成连贯、自然的文本,显著提升了机器处理自然语言任务的能力。
The core of NLP technology lies in building models that can understand and express language. Large Language Models (LLMs) are a key technology in this area. Based on deep neural network architectures, LLMs learn from massive text corpora to capture semantic and syntactic patterns among words, phrases, and sentences. This enables LLMs to automatically generate coherent and natural text, significantly enhancing machine performance in natural language processing tasks.
随着技术的不断进步,NLP的应用范围日益广泛,已深入智能助手、智能客服、信息检索、舆情分析、自动摘要等诸多领域。然而,NLP仍然面临诸多挑战,例如处理语言歧义、提升语义理解的准确性、以及整合多语言和多模态数据等。
With continuous technological progress, the application scope of NLP is expanding widely, penetrating areas such as intelligent assistants, customer service chatbots, information retrieval, public opinion analysis, and automatic summarization. However, NLP still faces numerous challenges, including handling linguistic ambiguity, improving the accuracy of semantic understanding, and integrating multilingual and multimodal data.
什么是大型语言模型 (LLM)?
What is a Large Language Model (LLM)?
语言模型是一种统计模型,用于预测一个单词序列在文本中出现的概率。作为基于人工神经网络的重要人工智能技术,语言模型通过对大规模文本数据进行训练来理解语言并预测序列中的下一个单词。大型语言模型(LLM)则是一种拥有海量可调参数的神经网络,使其能够学习语言中复杂的模式和结构。
A language model is a statistical model used to predict the probability of a sequence of words occurring in text. As a significant AI technology based on artificial neural networks, language models are trained on large-scale text data to understand language and predict the next word in a sequence. A Large Language Model (LLM) is a type of neural network with a vast number of tunable parameters, enabling it to learn complex patterns and structures in language.
通过训练,大型语言模型能够学习单词之间的上下文关系、语法规则以及常见的短语和句子结构,从而能够根据给定的上下文生成连贯、自然的文本。
Through training, LLMs learn contextual relationships between words, grammatical rules, and common phrase and sentence structures, allowing them to generate coherent and natural text based on a given context.
LLM,也称为预训练模型,是一种利用海量数据学习语言特征的人工智能工具。经过训练后,这些模型能够生成基于语言的数据集,可用于各种语言理解和生成任务。
LLMs, also known as pre-trained models, are AI tools that learn linguistic features from massive datasets. After training, these models can generate language-based datasets applicable to various language understanding and generation tasks.
LLM的一个重要特征是能够生成类人文本输出。它们可以生成连贯、语法正确的文本,有时甚至能表现出幽默感。此外,这些模型还具备将文本从一种语言翻译成另一种语言的能力,并能根据上下文回答问题。
A key characteristic of LLMs is their ability to generate human-like text output. They can produce coherent, grammatically correct text, sometimes even exhibiting a sense of humor. Furthermore, these models possess the capability to translate text from one language to another and answer questions based on context.
LLM的训练依赖于大量的文本数据,包括互联网网页、书籍、新闻文章等。通过学习这些数据,模型能够捕捉语言中的各种模式和规律,从而提高预测下一个单词的准确性。
The training of LLMs relies on vast amounts of text data, including web pages, books, news articles, and more from the internet. By learning from this data, the models capture various patterns and regularities in language, thereby improving the accuracy of predicting the next word.
LLM的应用非常广泛,涵盖机器翻译、文本生成、自动摘要、对话系统等。例如,在机器翻译任务中,模型可以根据源语言的上下文生成目标语言的翻译结果;在对话系统中,它能根据用户输入生成相应的回复。
The applications of LLMs are extensive, covering machine translation, text generation, automatic summarization, dialogue systems, and more. For instance, in machine translation tasks, the model can generate translations in the target language based on the context of the source language; in dialogue systems, it can generate responses based on user input.

领略大型语言模型全景观
Exploring the Landscape of Large Language Models
下图展示了大型语言模型(LLM)的出现所产生的涟漪效应,这种效应在多个层面产生影响。具体而言,LLM的生态全景可以划分为六个带状区域,每个区域代表着不同的需求和机遇。
The following diagram illustrates the ripple effect generated by the emergence of Large Language Models (LLMs), impacting multiple dimensions. Specifically, the LLM ecosystem panorama can be divided into six zones, each representing different needs and opportunities.
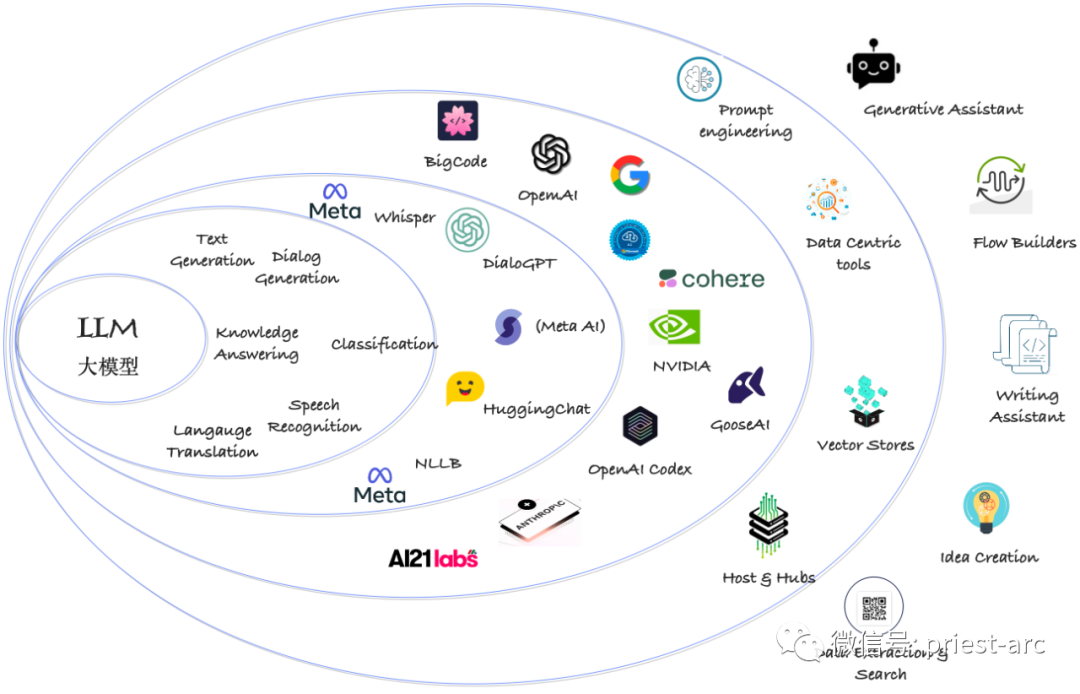
大型语言模型(LLM)全景观鸟瞰
A Bird's-Eye View of the Large Language Model (LLM) Landscape
区域 1:可用的大型语言模型
Zone 1: Available Large Language Models
考虑到LLM本质上是针对语言处理任务的模型,但在处理图像、音频等多模态数据时,引入了多模态模型或方法。这种转变催生了一个更通用的术语来描述这些模型——基础模型。
Considering that LLMs are inherently models for language processing tasks, the introduction of multimodal models or methods for handling data like images and audio has led to a more general term to describe these models—Foundation Models.
基础模型是指能够处理多种数据类型(如文本、图像、音频等)的模型。它们集成了不同的组件和技术,以便在多模态环境下进行信息融合与处理。这些基础模型可以同时处理不同模态的输入,并生成相应的输出结果。
Foundation Models refer to models capable of processing multiple types of data (e.g., text, images, audio). They integrate different components and technologies to enable information fusion and processing in multimodal environments. These foundation models can handle inputs from different modalities simultaneously and generate corresponding outputs.
除了多模态模型,大型商业供应商还提供了众多更专注于特定任务的模型。这些模型针对特定的应用场景和任务进行了优化和训练,以提供更高的性能和更准确的结果。例如,针对图像分类、语音识别、自然语言理解等任务,均有专门的商用模型。
In addition to multimodal models, major commercial vendors offer numerous models more specialized for specific tasks. These models are optimized and trained for particular application scenarios and tasks to deliver higher performance and more accurate results. For example, specialized commercial models exist for tasks like image classification, speech recognition, and natural language understanding.
此外,还存在一系列开源模型可供使用。开源模型由研究人员和开发者共享,这些模型经过训练并在特定任务上展现了良好的性能。它们可以作为起点或基础,为开发者提供快速启动的平台,同时也促进了模型研究与知识共享。
Furthermore, a range of open-source models is available for use. Open-source models are shared by researchers and developers, having been trained and demonstrating good performance on specific tasks. They can serve as a starting point or foundation, providing developers with a platform for rapid initiation and also promoting model research and knowledge sharing.
区域 2:常见的应用场景
Zone 2: Common Application Scenarios
模型接受特定任务的训练,以提供更专注、高效的解决方案。LLM的最新发展采用了一种方法,即将多种能力结合,允许模型使用不同的提示技术来激发出卓越的性能。
Models are trained for specific tasks to provide more focused and efficient solutions. Recent developments in LLMs adopt an approach that combines various capabilities, allowing models to use different prompting techniques to elicit remarkable performance.
LLM在文本生成任务方面表现出色,包括总结、重写、关键词提取等。这些模型能够生成准确、连贯的文本,以满足多样化需求。
LLMs excel at text generation tasks, including summarization, rewriting, keyword extraction, and more. These models can generate accurate and coherent text to meet diverse needs.
文本分析在当前变得越来越重要,而将文本嵌入模型对于实现这些任务至关重要。嵌入技术能够将文本转换为向量表示,从而提供更好的语义理解和语境感知能力。
Text analysis is becoming increasingly important, and embedding text into models is crucial for accomplishing these tasks. Embedding techniques convert text into vector representations, thereby providing better semantic understanding and contextual awareness.
此外,语音识别(ASR)也是LLM的关注领域之一,它是将音频语音转换为文本的过程。准确性是评估任何ASR过程的重要指标,通常使用词错误率(WER)来衡量。ASR技术为LLM的训练和使用提供了大量记录的语言数据,使得文本转换与分析更为便捷高效。
Additionally, Automatic Speech Recognition (ASR) is another area of focus for LLMs, involving the conversion of audio speech into text. Accuracy is a key metric for evaluating any ASR process, typically measured using Word Error Rate (WER). ASR technology provides a wealth of recorded language data for LLM training and usage, making text conversion and analysis more convenient and efficient.
区域 3:具体基础设施
Zone 3: Specific Infrastructure
此区域列出了一些特定用途的模型。实现可分为通用的强大LLM和基于LLM的数字/个人助理,如ChatGPT、HuggingChat和Cohere Coral。这些特定用途的模型为各行各业提供了定制化解决方案,使得语言处理等应用更加高效和精确。
This zone lists some models for specific purposes. Implementations can be divided into general-purpose, powerful LLMs and LLM-based digital/personal assistants, such as ChatGPT, HuggingChat, and Cohere Coral. These purpose-specific models provide customized solutions for various industries, making applications like language processing more efficient and precise.
区域 4:模型分类与供应商
Zone 4: Model Classification and Vendors
此区域列出了最著名的大型语言模型供应商。大多数LLM拥有内置的知识和功能,包括人类语言翻译、代码解释与编写、通过提示工程进行对话和上下文管理的能力。供应商提供的LLM能够满足不同用户的需求,从跨语言沟通到代码编写,从对话系统到上下文管理,为用户提供了强大的语言处理和智能化服务。
This zone lists the most prominent Large Language Model vendors. Most LLMs possess built-in knowledge and capabilities, including human language translation, code interpretation and writing, and the ability for dialogue and context management through prompt engineering. The LLMs provided by vendors cater to diverse user needs, offering powerful language processing and intelligent services ranging from cross-language communication to code writing, and from dialogue systems to context management.
区域 5:基础工具/平台
Zone 5: Foundational Tools/Platforms
此区域提出的概念是以数据为中心的工具,这些工具专注于使LLM的使用变得可重复且具有高价值。这意味着关注点在于如何有效利用数据来提升LLM的性能和应用价值。
The concept proposed in this zone is data-centric tools that focus on making the use of LLMs repeatable and high-value. This means the emphasis is on how to effectively leverage data to enhance the performance and application value of LLMs.
区域 6:终端用户应用
Zone 6: End-User Applications
此区域涌现了大量专注于流程构建、创意生成、内容创作和写作辅助的应用程序。这些产品致力于提供优质的用户体验,并在LLM和用户之间增加不同程度的价值。通过这些应用程序,用户能够更好地利用LLM的潜力,实现更加出色和有影响力的工作与创作。
This zone has seen the emergence of a large number of applications focused on workflow construction, creative generation, content creation, and writing assistance. These products are dedicated to providing a high-quality user experience and adding varying degrees of value between LLMs and users. Through these applications, users can better harness the potential of LLMs to achieve more outstanding and impactful work and creations.
大型语言模型是如何工作的?
How Do Large Language Models Work?
LLM通过一种称为无监督学习的技术进行工作。在无监督学习中,模型在大量未标记的数据上进行训练,没有特定的标签或目标。其目标是学习数据的基本结构,并生成与原始数据结构相似的新数据。
LLMs operate using a technique called unsupervised learning. In unsupervised learning, the model is trained on a large amount of unlabeled data without specific labels or targets. Its goal is to learn the underlying structure of the data and generate new data similar to the original data's structure.
对于LLM而言,训练数据通常是大规模的文本语料库。模型学习文本数据中的模式,并利用这些模式生成新的文本。训练过程涉及优化模型参数,以尽可能减少生成的文本与语料库中实际文本之间的差异。
For LLMs, the training data is typically a large-scale text corpus. The model learns patterns within the text data and uses these patterns to generate new text. The training process involves optimizing model parameters to minimize the difference between the generated text and the actual text in the corpus.
一旦模型训练完成,就可以用于生成新的文本。为此,模型被赋予一个起始单词序列,并根据训练语料库中学习到的单词概率分布来生成序列中的下一个单词。这个过程不断重复,直到生成所需长度的文本。
Once the model is trained, it can be used to generate new text. To do this, the model is given a starting sequence of words and generates the next word in the sequence based on the learned probability distribution of words from the training corpus. This process repeats until text of the desired length is generated.
这里,我们简要了解一下LLM的工作原理机制,具体可参考如下示意图:
Here, we briefly examine the working mechanism of LLMs, as illustrated in the following diagram:
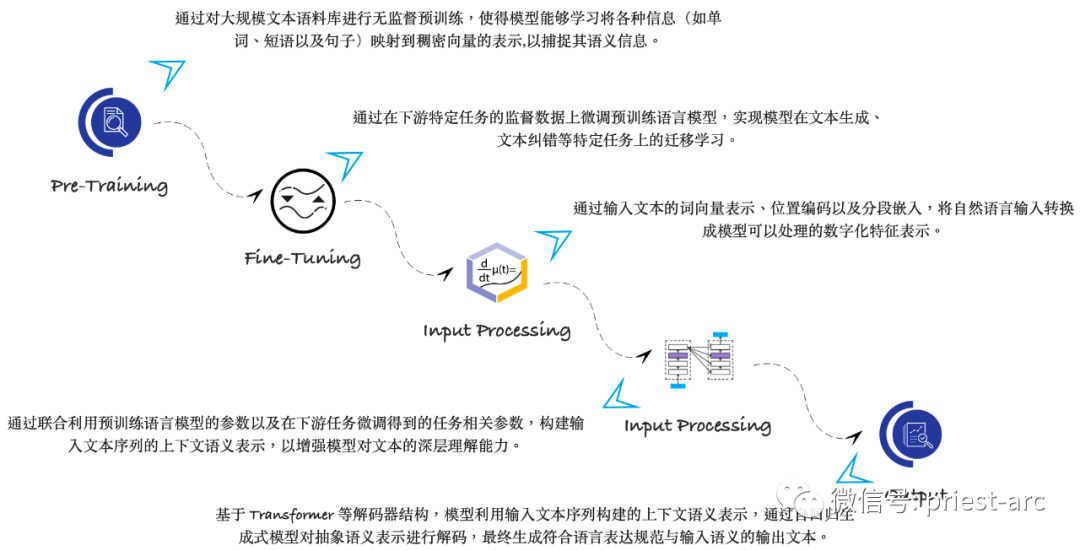
了解LLM的工作原理,以及了解可用的不同类型的语言模型是很重要的。最常见的语言模型类型包括循环神经网络(RNN)、卷积神经网络(CNN)和长短期记忆网络(LSTM)。这些模型通常在大型数据集(如Penn Treebank)上进行训练,并可用于生成基于语言的数据集。
Understanding how LLMs work and the different types of available language models is important. The most common types of language models include Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and Long Short-Term Memory networks (LSTMs). These models are typically trained on large datasets (like the Penn Treebank) and can be used to generate language-based datasets.
接下来,让我们深入了解一些领先的LLM、它们的创建者以及它们所训练的参数数量。这些模型代表了人工智能领域最前沿的技术发展。具体可参考如下示意图:
Next, let's delve into some leading LLMs, their creators, and the number of parameters they were trained on. These models represent the cutting-edge technological developments in the field of artificial intelligence. Please refer to the following diagram:
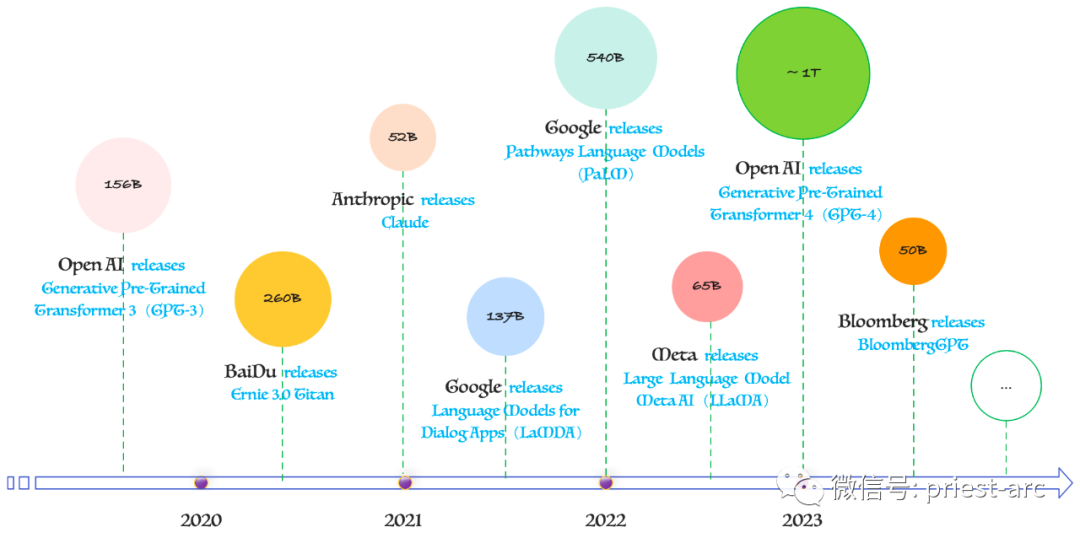
资料来源:Roundhill Investments
Source: Roundhill Investments
基于上述模型参数图,我们可以看到,现在有许多备受欢迎的LLM。为了更清晰地对比,我们将其核心信息整理如下表:
Based on the model parameter chart above, we can see there are many popular LLMs today. To provide a clearer comparison, we have organized their core information into the following table:
| 模型名称 | 开发机构/公司 | 参数量级 | 主要特点/应用 |
|---|---|---|---|
| ChatGPT (GPT系列) | OpenAI | 千亿级 (推测) | 基于生成预训练Transformer,强大的对话与文本生成能力。 |
| LaMDA / PaLM | 千亿级 | 专注于对话应用(LaMDA)与通用语言任务(PaLM),展现出色的语言理解与生成。 | |
| Claude | Anthropic (获Google投资) | 千亿级 | 强调安全性、可控性与有用性,致力于构建可靠的AI助手。 |
| Ernie 3.0 Titan | 百度 | 千亿级 | 为文心一言(ErnieBot)聊天机器人提供支持,具备强大的中文理解与生成能力。 |
| SenseNova | 商汤科技 (SenseTime) | 千亿级 | 为商量(SenseChat)聊天机器人及其他服务提供支持,是多模态大模型。 |
| BloombergGPT | Bloomberg | 五百亿级 | 金融领域专用模型,使用大量金融文本数据训练,用于金融NLP任务。 |
| Bing AI (GPT模型) | 微软 | 千
常见问题(FAQ)大型语言模型(LLM)到底是什么?大型语言模型是基于海量文本数据训练的高级AI系统,通过深度神经网络学习语言规律,能够理解、生成和处理人类语言,是自然语言处理的核心技术。 LLM在实际中有哪些常见应用场景?LLM广泛应用于机器翻译、内容创作、智能客服聊天机器人、情感分析、自动摘要、问答系统等领域,显著提升了机器处理自然语言任务的能力。 目前大型语言模型面临哪些主要挑战?主要挑战包括高昂的训练成本、训练数据中可能存在的偏见问题、伦理安全风险,以及处理语言歧义、提升语义理解准确性等技术难题。 版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。 文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。 若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。 |