大语言模型如何作为文档补全引擎工作?GitHub Copilot提示工程实践详解

AI Summary (BLUF)
This article explores how large language models (LLMs) function as document completion engines and demonstrates how to build practical applications by mapping between user and document domains, using GitHub Copilot's prompt engineering pipeline as a detailed case study.
原文翻译: 本文探讨了大型语言模型(LLM)如何作为文档完成引擎工作,并通过在用户领域和文档领域之间建立映射来构建实际应用,以GitHub Copilot的提示工程流程作为详细案例研究。
早在2011年,Marc Andreessen 在一篇博客文章中警告说:“软件正在吞噬世界”。十多年后的今天,我们正见证一种新型技术的崛起,它以更强大的“胃口”吞噬着世界:生成式人工智能(AI)。这种创新的AI包含一类独特的大语言模型(LLM),它们源于十年来突破性的研究,能够在某些任务上超越人类。而且,你不需要拥有机器学习博士学位就能使用LLM进行构建——开发者们已经能够通过基本的HTTP请求和自然语言提示来构建基于LLM的软件。
In a blog post authored back in 2011, Marc Andreessen warned that, “Software is eating the world.” Over a decade later, we are witnessing the emergence of a new type of technology that’s consuming the world with even greater voracity: generative artificial intelligence (AI). This innovative AI includes a unique class of large language models (LLM), derived from a decade of groundbreaking research, that are capable of out-performing humans at certain tasks. And you don’t have to have a PhD in machine learning to build with LLMs—developers are already building software with LLMs with basic HTTP requests and natural language prompts.
在本文中,我们将讲述GitHub在LLM方面的工作,以帮助其他开发者学习如何最好地利用这项技术。本文主要包括两个部分:第一部分将高层次地描述LLM的工作原理以及如何构建基于LLM的应用程序。第二部分将深入探讨一个重要的基于LLM的应用程序示例:GitHub Copilot代码补全。
In this article, we’ll tell the story of GitHub’s work with LLMs to help other developers learn how to best make use of this technology. This post consists of two main sections: the first will describe at a high level how LLMs function and how to build LLM-based applications. The second will dig into an important example of an LLM-based application: GitHub Copilot code completions.
其他人已经从外部视角出色地梳理了我们的工作。现在,我们很高兴能分享一些导致GitHub Copilot持续成功的思考过程。
Others have done an impressive job of cataloging our work from the outside. Now, we’re excited to share some of the thought processes that have led to the ongoing success of GitHub Copilot.
让我们开始吧。
Let’s jump in.
关于提示工程,你需要知道的一切(不超过1600个令牌)
当你在手机上敲打短信时,屏幕中央键盘上方是不是有一个按钮,点击它可以接受建议的下一个词?这基本上就是LLM在做的事情——只不过规模更大。
You know when you’re tapping out a text message on your phone, and in the middle of the screen just above the keypad, there’s a button you can click to accept a suggested next word? That’s pretty much what an LLM is doing—but at scale.
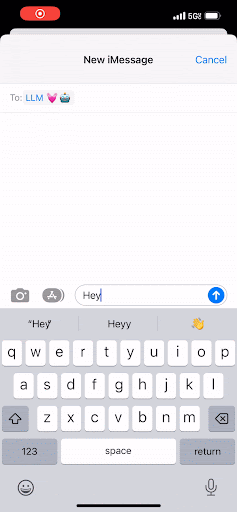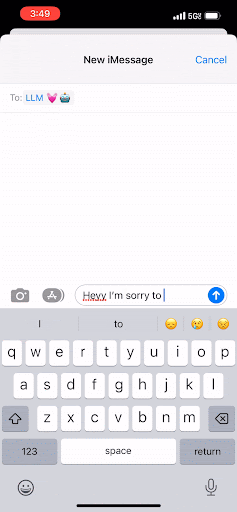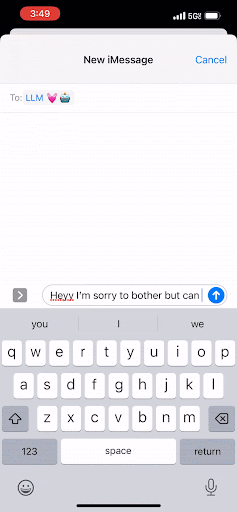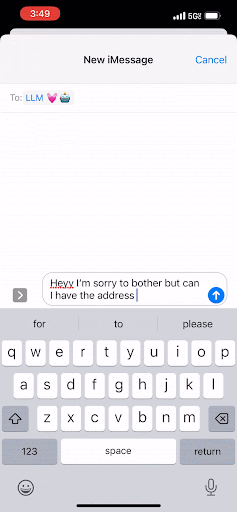
与手机上的文本不同,LLM致力于预测下一个最佳的字母组,这些字母组被称为“令牌”。就像你可以不断点击那个中间按钮来完成短信一样,LLM通过预测下一个词来完成文档。它会一遍又一遍地这样做,只有在达到令牌的最大阈值或遇到表示“停止!这是文档结尾”的特殊令牌时才会停止。
Instead of text on your phone, an LLM works to predict the next best group of letters, which are called “tokens.” And in the same way that you can keep tapping that middle button to complete your text message, the LLM completes a document by predicting the next word. It will continue to do that over and over, and it will only stop once it has reached a maximum threshold of tokens or once it has encountered a special token that signals “Stop! This is the end of the document.”
不过,有一个重要的区别。你手机上的语言模型相当简单——它基本上是说:“仅基于最后输入的两个词,最可能的下一个词是什么?”相比之下,LLM产生的输出更接近于:“基于公共领域已知存在的每个文档的全部内容,你的文档中最可能的下一个令牌是什么?”通过在庞大的数据集上训练如此庞大、架构良好的模型,LLM几乎可以表现出常识,例如理解放在桌子上的玻璃球可能会滚落并摔碎。
There’s an important difference, though. The language model in your phone is pretty simple—it’s basically saying, “Based only upon the last two words entered, what is the most likely next word?” In contrast, an LLM produces an output that’s more akin to being “based upon the full content of every document ever known to exist in the public domain, what is the most likely next token in your document?” By training such a large, well-architected model on an enormous dataset, an LLM can almost appear to have common sense such as understanding that a glass ball sitting on a table might roll off and shatter.

但要注意:LLM有时也会自信地产生不真实或不正确的信息,这通常被称为“幻觉”或“虚构”。LLM还可能表现出学会了它们最初并未被训练执行的任务。历史上,自然语言模型是为一次性任务创建的,比如对推文进行情感分类、从电子邮件中提取业务实体或识别相似文档,但现在你可以要求像ChatGPT这样的AI工具执行它从未被训练过的任务。
But be warned: LLMs will also sometimes confidently produce information that isn’t real or true, which are typically called “hallucinations” or “fabulations.” LLMs can also appear to learn how to do things they weren’t initially trained to do. Historically, natural language models have been created for one-off tasks, like classifying the sentiment of a tweet, extracting the business entities from an email, or identifying similar documents, but now you can ask AI tools like ChatGPT to perform a task that it was never trained to do.
使用LLM构建应用程序
文档补全引擎与如今每天涌现的惊人LLM应用相去甚远,这些应用涵盖了从对话搜索、写作助手、自动化IT支持到代码补全工具(如GitHub Copilot)的广泛范围。但是,所有这些工具怎么可能都来自一个本质上是文档补全工具的东西呢?秘诀在于,任何使用LLM的应用程序实际上都是在两个领域之间进行映射:用户领域和文档领域。
A document completion engine is a far cry from the amazing proliferation of LLM applications that are springing up every day, running the gamut from conversational search, writing assistants, automated IT support, and code completion tools, like GitHub Copilot. But how is it possible that all of these tools can come from what is effectively a document completion tool? The secret is any application that uses an LLM is actually mapping between two domains: the user domain and the document domain.
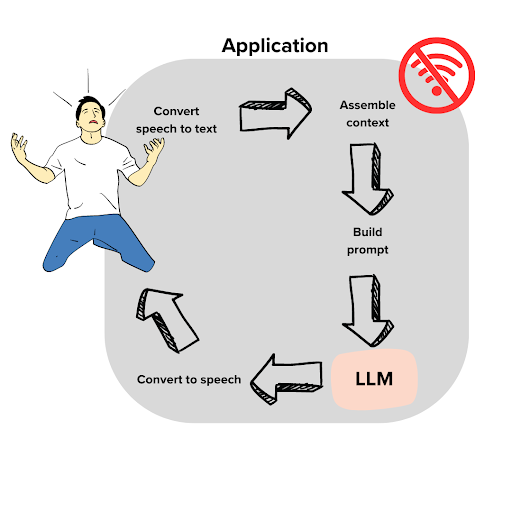
左边是用户。他叫Dave,遇到了一个问题。今天是他盛大的世界杯观赛派对,但Wi-Fi断了。如果不尽快修好,他将在未来几年成为朋友们的笑柄。Dave打电话给他的互联网提供商,接通了一个自动助手。唉!但想象一下,我们正在将自动助手实现为一个LLM应用程序。我们能帮助他吗?
On the left is the user. His name is Dave, and he has a problem. It’s the day of his big World Cup watch party, and the Wi-Fi is out. If they don’t get it fixed soon, he’ll be the butt of his friends’ jokes for years. Dave calls his internet provider and gets an automated assistant. Ugh! But imagine that we are implementing the automated assistant as an LLM application. Can we help him?
这里的关键是找出如何从用户领域转换到文档领域。一方面,我们需要将用户的语音转录成文本。自动支持代理一说完“请说明您的有线电视相关紧急情况的性质”,Dave就脱口而出:
The key here is to figure out how to convert from user domain into document domain. For one thing, we will need to transcribe the user’s speech into text. As soon as the automated support agent says “Please state the nature of your cable-related emergency,” Dave blurts out:
哦,太糟糕了!今天是世界杯决赛。我的电视本来连着Wi-Fi,但我撞到了柜台,Wi-Fi盒子掉下来摔坏了!现在,我们看不了比赛了。
Oh it’s awful! It’s the World Cup finals. My TV was connected to my Wi-Fi, but I bumped the counter and the Wi-Fi box fell off and broke! Now, we can’t watch the game.
此时,我们有了文本,但用处不大。你可能会想象这是故事的一部分并继续下去,“我想,我会打电话给我哥哥,看看我们能不能去他那里看比赛。”一个没有上下文的LLM同样会创建Dave故事的延续。所以,让我们给LLM一些上下文,并确定这是什么类型的文档:
At this point, we have text, but it’s not of much use. Maybe you would imagine that this was part of a story and continue it, “I guess, I’ll call up my brother and see if we can watch the game with him.” An LLM with no context will similarly create the continuation of Dave’s story. So, let’s give the LLM some context and establish what type of document this is:
### ISP IT Support Transcript:
The following is a recorded conversation between an ISP customer, Dave Anderson, and Julia Jones, IT support expert. This transcript serves as an example of the excellent support provided by Comcrash to its customers.
*Dave: Oh it's awful! This is the big game day. My TV was connected to my Wi-Fi, but I bumped the counter and the Wi-Fi box fell off and broke! Now we can't watch the game.
*Julia:
现在,如果你在地上发现了这份伪文档,你会如何完成它?基于额外的上下文,你会看到Julia是一名IT支持专家,而且显然是一位非常优秀的专家。你会期望接下来的话是帮助Dave解决问题的明智建议。Julia不存在,这不是一次被记录的对话,这些都不重要——重要的是这些额外的词语为补全内容提供了更多上下文。LLM做的正是完全相同的事情。在阅读了这份部分文档后,它会尽力以有帮助的方式完成Julia的对话。
Now, if you found this pseudo document on the ground, how would you complete it? Based on the extra context, you would see that Julia is an IT support expert, and apparently a really good one. You would expect the next words to be sage advice to help Dave with his problem. It doesn’t matter that Julia doesn’t exist, and this wasn’t a recorded conversation—what matters is that these extra words offer more context for what a completion might look like. An LLM does the same exact thing. After reading this partial document, it will do its best to complete Julia’s dialogue in a helpful manner.
但我们还可以做更多来为LLM创建最佳文档。LLM对有线电视故障排除了解不多。(好吧,它读过网上发布的每一本手册和IT文档,但请先听我说)。让我们假设它在这个特定领域的知识有所欠缺。我们可以做的一件事是搜索可能帮助Dave的额外内容,并将其放入文档中。假设我们有一个投诉搜索引擎,可以找到过去在类似情况下有帮助的文档。现在,我们所要做的就是将这些信息自然地编织到我们的伪文档中。
But there’s more we can do to make the best document for the LLM. The LLM doesn’t know a whole lot about cable TV troubleshooting. (Well, it has read every manual and IT document ever published online, but stay with me here). Let’s assume that its knowledge is lacking in this particular domain. One thing we can do is search for extra content that might help Dave and place it into the document. Let’s assume that we have a complaints search engine that allows us to find documentation that has been helpful in similar situations in the past. Now, all we have to do is weave this information into our pseudo document in a natural place.
继续上面的内容:
Continuing from above:
*Julia:(rifles around in her briefcase and pulls out the perfect documentation for Dave's request)
Common internet connectivity problems ...
<...here we insert 1 page of text that comes from search results against our customer support history database...>
(After reading the document, Julia makes the following recommendation)
*Julia:
现在,给定这整个文本主体,LLM被设定为利用植入的文档,并且在“一个有帮助的IT专家”的上下文中,模型将生成一个回复。这个回复考虑了文档以及Dave的具体请求。
Now, given this full body of text, the LLM is conditioned to make use of the implanted documentation, and in the context of “a helpful IT expert,” the model will generate a response. This reply takes into account the documentation as well as Dave’s specific request.
最后一步是从文档领域转移到用户的问题领域。对于这个例子,这意味着将文本转换为语音。由于这本质上是一个聊天应用程序,我们将在用户和文档领域之间来回几次,每次都会使对话记录变得更长。
The last step is to move from the document domain into the user’s problem domain. For this example, that means just converting text to voice. And since this is effectively a chat application, we would go back and forth several times between the user and the document domain, making the transcript longer each time.
这个例子的核心就是提示工程。在例子中,我们设计了一个具有足够上下文的提示,让AI产生最佳可能的输出,在这种情况下就是为Dave提供有用的信息以恢复他的Wi-Fi。在下一节中,我们将看看我们GitHub如何为GitHub Copilot完善我们的提示工程技术。
This, at the core of the example, is prompt engineering. In the example, we crafted a prompt with enough context for the AI to produce the best possible output, which in this case was providing Dave with helpful information to get his Wi-Fi up and running again. In the next section, we’ll take a look at how we at GitHub have refined our prompt engineering techniques for GitHub Copilot.
提示工程的艺术与科学
在用户领域和文档领域之间进行转换是提示工程的领域——由于我们从事GitHub Copilot工作已超过两年,我们开始在这个过程中识别出一些模式。
Converting between the user domain and document domain is the realm of prompt engineering—and since we’ve been working on GitHub Copilot for over two years, we’ve started to identify some patterns in the process.
这些模式帮助我们形式化了一个流程,我们认为这是一个适用的模板,可以帮助其他人更好地为自己的应用程序进行提示工程。现在,我们将通过分析GitHub Copilot(我们的AI结对程序员)的上下文来演示这个流程是如何工作的。
These patterns have helped us formalize a pipeline, and we think it is an applicable template to help others better approach prompt engineering for their own applications. Now, we’ll demonstrate how this pipeline works by examining it in the context of GitHub Copilot, our AI pair programmer.
GitHub Copilot 的提示工程流程
从一开始,GitHub Copilot的LLM就建立在OpenAI的AI模型之上,这些模型一直在不断改进。但不变的是对提示工程核心问题的回答:模型试图完成的是哪种文档?
From the very beginning, GitHub Copilot’s LLMs have been built on AI models from OpenAI that have continued to get better and better. But what hasn’t changed is the answer to the central question of prompt engineering: what kind of document is the model trying to complete?
我们使用的OpenAI模型已经过训练,可以完成GitHub上的代码文件。忽略一些并不真正改变提示工程游戏规则的过滤和分层步骤,这个分布基本上就是数据收集时根据对main分支的最新提交所得到的单个文件内容的分布。
The OpenAI models we use have been trained to complete code files on GitHub. Ignoring some filtering and stratification steps that don’t really change the prompt engineering game, this distribution is pretty much that of individual file contents according to the most recent commit to main at data collection time.
LLM解决的文档补全问题是关于代码的,而GitHub Copilot的任务完全是关于补全代码。但两者非常不同。
The document completion problem the LLM solves is about code, and GitHub Copilot’s task is all about completing code. But the two are very different.
以下是一些例子:
Here are some examples:
- 提交到main分支的大多数文件都是完成的。首先,它们通常可以编译。大多数时候用户正在输入时,代码由于不完整而无法编译,这些不完整将在推送提交之前被修复。
- 用户甚至可能按层次顺序编写代码,先写方法签名,再写方法体,而不是逐行或以混合风格编写。
- 编写代码意味着跳转。特别是,人们的编辑通常需要他们跳转到文档上方并在那里进行更改,例如,向函数添加参数。严格来说,如果Codex建议使用一个尚未导入的函数,无论这看起来多么合理,都是一个错误。但作为GitHub Copilot的建议,这将是有用的。
- Most files committed to main are finished. For one, they usually compile. Most of the time the user is typing, the code does not compile because of incompletions that will be fixed before a commit is pushed.
- The user might even write their code in hierarchical order, method signatures first, then bodies rather than line by line or in a mixed style.
- Writing code means jumping around. In particular, people’s edits often require them to jump up in the document and make a change there, for example, adding a parameter to a function. Strictly speaking, if Codex suggests using a function that has not been imported yet, no matter how much sense it might make, that’s a mistake. But as a GitHub Copilot suggestion, it would be useful.
问题在于,仅仅基于光标前的文本预测最可能的延续来生成GitHub Copilot建议,将是浪费机会。因为它忽略了极其丰富的上下文。我们可以利用这些上下文来指导建议,比如元数据、光标下方的代码、导入的内容、仓库的其余部分或问题,从而为AI助手创建一个强大的提示。
The issue is that merely predicting the most likely continuation based on the text in front of the cursor to make a GitHub Copilot suggestion would be a wasted opportunity. That’s because it ignores an incredible wealth of context. We can use that context to guide the suggestion, like metadata, the code below the cursor, the content of imports, the rest of
常见问题(FAQ)
什么是提示工程?为什么它对LLM应用很重要?
提示工程是通过设计自然语言指令来引导大语言模型生成所需输出的技术。它是构建LLM应用的核心,决定了模型能否准确理解任务并产生有效响应。
GitHub Copilot是如何使用提示工程实现代码补全的?
GitHub Copilot将代码补全视为文档完成任务,通过精心设计的提示在用户编程意图和代码文档之间建立映射,使LLM能够预测并生成最相关的代码片段。
如何基于LLM构建实用的应用程序?
构建LLM应用的关键在于理解模型作为文档完成引擎的工作原理,并通过提示工程在用户领域和文档领域之间建立有效映射,GitHub Copilot的流程为此提供了详细案例。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。