强化学习如何赋能大语言模型?RLHF技术优势详解

How Reinforcement Learning Empowers Large Language Models: Advantages Beyond Supervised Fine-Tuning and a Deep Dive into RLHF
引言:从SFT到RL的范式演进
Introduction: The Paradigm Shift from SFT to RL
与监督微调(SFT)相比,强化学习能够给大语言模型带来哪些根本性的好处呢?这是一个在大型语言模型(LLM)对齐领域至关重要的问题。2023年4月,OpenAI联合创始人John Schulman在伯克利EECS会议上的报告《Reinforcement Learning from Human Feedback: Progress and Challenges》深入分享了OpenAI在基于人类反馈的强化学习(RLHF)方面的进展,并系统分析了监督学习和强化学习各自面临的独特挑战。
Compared to Supervised Fine-Tuning (SFT), what fundamental benefits can reinforcement learning bring to large language models? This is a critical question in the field of Large Language Model (LLM) alignment. In April 2023, OpenAI co-founder John Schulman, in his presentation "Reinforcement Learning from Human Feedback: Progress and Challenges" at the Berkeley EECS conference, provided an in-depth look at OpenAI's progress in Reinforcement Learning from Human Feedback (RLHF) and systematically analyzed the unique challenges faced by both supervised learning and reinforcement learning.
强化学习在大语言模型训练中的作用远不止于简单的策略优化,其核心优势可以概括为以下几个关键方面。
The role of reinforcement learning in large language model training extends far beyond simple policy optimization. Its core advantages can be summarized in the following key aspects.
强化学习相对于SFT的核心优势
Core Advantages of RL over SFT
1. 整体性反馈与表达多样性
1. Holistic Feedback and Expressive Diversity
强化学习比SFT更能考虑整体影响:SFT本质上针对单个token进行反馈和优化,其训练目标是要求模型针对给定的输入生成一个确切的、预定义的答案序列。而强化学习则是针对整个输出文本序列进行整体性反馈,并不针对特定的、孤立的token。这种从“局部”到“全局”的反馈粒度转变,使得强化学习天然更适合大语言模型的生成任务。它既可以鼓励表达的多样性(因为不同的正确表述可以获得相似的高奖励),还可以增强模型对输出中微小但语义重要变化的敏感性。自然语言具有高度的灵活性,相同的语义完全可以用多种不同的句式和词汇来表达。传统的监督学习范式很难有效支持这种“一对多”的映射学习。
Reinforcement learning considers holistic impact better than SFT: SFT essentially provides feedback and optimization at the level of individual tokens. Its training objective is to compel the model to generate a specific, predefined sequence of answers for a given input. In contrast, reinforcement learning provides holistic feedback on the entire output text sequence, without targeting specific, isolated tokens. This shift in feedback granularity from "local" to "global" makes reinforcement learning inherently more suitable for the generative tasks of large language models. It can both encourage expressive diversity (as different correct phrasings can receive similarly high rewards) and enhance the model's sensitivity to subtle yet semantically significant changes in the output. Natural language is highly flexible, and the same semantics can be expressed through a variety of different sentence structures and vocabularies. The traditional supervised learning paradigm struggles to effectively support this "one-to-many" mapping learning.
2. 缓解模型“幻觉”问题
2. Mitigating Model "Hallucination"
强化学习为缓解幻觉提供了更灵活的框架:用户与大语言模型的交互主要可分为三类输入:(a)文本型:用户提供相关文本和问题,要求模型基于所提供的上下文生成答案;(b)求知型:用户仅提出问题,模型需要根据其内在知识库提供真实、准确的回答;(c)创造型:用户提出问题或说明,让模型进行开放性的创造性输出。SFT训练方式非常容易导致模型在面对“求知型”查询时产生“幻觉”。即使在模型内部并不包含或不知道正确答案的情况下,SFT的“必须生成答案”的压力仍会促使模型编造一个看似合理但事实错误的回复。而使用强化学习方法,则可以通过精心设计奖励函数来系统地引导模型行为。例如,可以将基于可靠证据的正确回答赋予非常高的正分数,将诚实表示“不知道”或“无法回答”的答案赋予中等分数,而将事实错误的“幻觉”答案赋予非常高的负分(严厉惩罚)。通过这种奖励塑造,模型能够学会在知识边界内保持诚实,依赖内部知识选择在不确定时放弃回答,从而在根本上缓解模型幻觉问题。
Reinforcement learning provides a more flexible framework for mitigating hallucinations: User interactions with large language models can be broadly categorized into three types of inputs: (a) Text-based: The user provides relevant text and a question, requiring the model to generate an answer based on the given context. (b) Knowledge-seeking: The user poses a question alone, and the model needs to provide a truthful, accurate answer based on its internal knowledge base. (c) Creative: The user presents a problem or instruction, allowing the model to produce open-ended, creative output. The SFT training approach is particularly prone to causing models to "hallucinate" when faced with "knowledge-seeking" queries. Even when the model does not contain or know the correct answer internally, the pressure from SFT to "must generate an answer" can compel the model to fabricate a plausible-sounding but factually incorrect response. Using reinforcement learning methods, however, allows for the systematic guidance of model behavior through carefully designed reward functions. For example, correct answers based on reliable evidence can be assigned very high positive scores, honest responses like "I don't know" or "I cannot answer" can be given medium scores, and factually incorrect "hallucinated" answers can be assigned very high negative scores (severe penalties). Through this reward shaping, the model can learn to remain honest within its knowledge boundaries, relying on internal knowledge to choose to abstain from answering when uncertain, thereby addressing the model hallucination problem at its root.
3. 优化多轮对话的长期收益
3. Optimizing Long-term Gain in Multi-turn Dialogue
强化学习天然适合解决多轮对话中的奖励累积问题:多轮对话能力是大语言模型作为交互式智能体最重要的基础能力之一。判断一次多轮对话是否成功达成用户目标,必须考虑整个交互序列的整体情况,包括对话的连贯性、信息的一致性以及最终目标的达成度。这种涉及长期规划和状态依赖的序列决策问题,很难使用SFT方法通过独立的单轮样本进行有效构建。而强化学习方法的核心就是处理序列决策问题,它可以通过构建合适的奖励函数,将当前输出的好坏置于整个对话历史(状态)的背景下进行评估。例如,奖励函数可以设计为鼓励模型提出澄清性问题以消除早期歧义,或者为最终完美解决用户复杂需求的对话路径提供更高的累积奖励,从而引导模型学习具有战略眼光的对话策略。
Reinforcement learning is inherently suited for solving the credit assignment problem in multi-turn dialogue: Multi-turn dialogue capability is one of the most fundamental and important abilities of large language models as interactive agents. Determining whether a multi-turn dialogue successfully achieves the user's goal requires considering the overall context of the entire interaction sequence, including dialogue coherence, information consistency, and the degree of final goal attainment. This type of sequential decision-making problem involving long-term planning and state dependency is difficult to construct effectively using the SFT method with independent single-turn samples. In contrast, the core of reinforcement learning methods is to handle sequential decision-making problems. It can evaluate the quality of the current output within the context of the entire dialogue history (state) by constructing an appropriate reward function. For example, the reward function can be designed to encourage the model to ask clarifying questions to resolve early ambiguities or to provide higher cumulative rewards for dialogue paths that ultimately perfectly address the user's complex needs, thereby guiding the model to learn strategic dialogue policies.
正是因为强化学习具有上述这些超越SFT的独特优点,它已成为对齐和优化大语言模型行为不可或缺的关键技术。下文我们将深入介绍这一强大技术的基础原理及其在RLHF中的具体应用。
It is precisely because reinforcement learning possesses these unique advantages over SFT that it has become an indispensable key technology for aligning and optimizing the behavior of large language models. Below, we will delve into the fundamental principles of this powerful technology and its specific application in RLHF.
强化学习基础框架
Fundamental Framework of Reinforcement Learning
强化学习(Reinforcement Learning, RL)的核心是研究智能体(Agent)如何通过与复杂且不确定的环境(Environment)交互,来学习能够最大化累积奖励(Reward)的策略。其基本框架如图1所示,主要由智能体和环境两部分构成,二者处于持续的交互循环中。
The core of Reinforcement Learning (RL) is studying how an agent learns a policy that maximizes cumulative reward through interaction with a complex and uncertain environment. Its basic framework is shown in Figure 1, consisting primarily of two parts: the agent and the environment, which are in a continuous interaction loop.
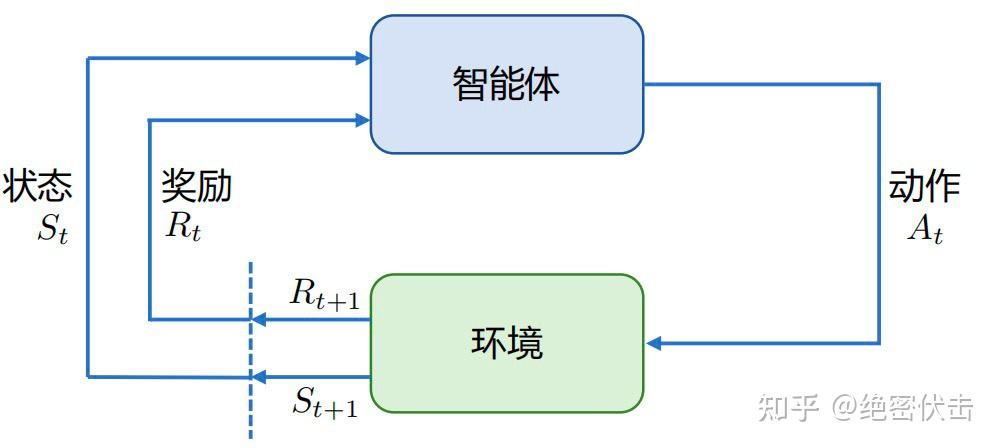
智能体在环境中感知到某个状态(State)后,会依据其内部策略输出一个动作(Action)。该动作在环境中被执行,环境随后转移到下一个状态,并给予智能体一个即时奖励信号,用以评价该动作的好坏。智能体的终极目标就是通过与环境的反复试错,学会一个能最大化长期累积奖励的策略。
After perceiving a state in the environment, the agent outputs an action based on its internal policy. This action is executed in the environment, which then transitions to a new state and provides the agent with an immediate reward signal to evaluate the quality of the action. The ultimate goal of the agent is to learn, through trial and error with the environment, a policy that maximizes long-term cumulative reward.
以图1为例,智能体与环境的单步交互过程可以形式化描述如下:
Taking Figure 1 as an example, the single-step interaction process between the agent and the environment can be formalized as follows:
- 在
t时刻,环境的状态为S_t,智能体到达此状态所获得的奖励为R_t。 - 智能体观测到
S_t与R_t,据此采取动作A_t。 - 智能体执行动作
A_t后,环境状态变为S_{t+1},同时智能体获得相应的奖励R_{t+1}。
- At time
t, the state of the environment isS_t, and the reward obtained by the agent for reaching this state isR_t.- The agent observes
S_tandR_tand takes actionA_taccordingly.- After the agent executes action
A_t, the environment state changes toS_{t+1}, and the agent receives the corresponding rewardR_{t+1}.
智能体在这个过程中不断学习,其最终目标是:找到一个最优策略,该策略能根据当前观测到的环境状态和过往经验,持续选择出能最大化未来期望奖励的动作序列。
The agent continuously learns throughout this process. Its ultimate goal is: to find an optimal policy that, based on the currently observed environment state and past experience, consistently selects the sequence of actions that maximizes expected future reward.
核心概念定义
Core Concept Definitions
- 动作空间(Action Space, A):在给定环境中,智能体所有可能采取的有效动作的集合。
- 策略(Policy, π):智能体的决策模型,它定义了在给定状态下选择动作的规则。策略可分为两类:
- 随机性策略(Stochastic Policy):表示为
π(a|s) = P(A_t = a | S_t = s)。它输入一个状态s,输出一个在所有可能动作上的概率分布。智能体根据这个分布采样得到要执行的动作。 - 确定性策略(Deterministic Policy):智能体直接选择当前概率最高的动作,即
a* = argmax_a π(a|s)。
- 随机性策略(Stochastic Policy):表示为
- 价值函数(Value Function):用于评估状态或状态-动作对长期价值的关键函数,是对未来累积奖励的预测。
- 状态价值函数 V_π(s):表示在策略
π下,从状态s开始所能获得的期望累积回报。V_π(s) = E_π[ G_t | S_t = s ] = E_π[ Σ_{k=0}^{∞} γ^k R_{t+k+1} | S_t = s ],其中s ∈ S。 - 动作价值函数 Q_π(s, a):表示在策略
π下,从状态s开始并执行动作a后所能获得的期望累积回报。Q_π(s, a) = E_π[ G_t | S_t = s, A_t = a ] = E_π[ Σ_{k=0}^{∞} γ^k R_{t+k+1} | S_t = s, A_t = a ]。 - 其中,
γ(0 ≤ γ ≤ 1)是折扣因子,用于权衡即时奖励和远期奖励的重要性;E_π[·]表示在策略π下的期望。
- 状态价值函数 V_π(s):表示在策略
- Action Space (A): The set of all valid actions that the agent can possibly take in a given environment.
- Policy (π): The decision-making model of the agent, which defines the rule for selecting an action given a state. Policies can be categorized into two types:
- Stochastic Policy: Denoted as
π(a|s) = P(A_t = a | S_t = s). It takes a statesas input and outputs a probability distribution over all possible actions. The agent samples from this distribution to determine the action to execute.- Deterministic Policy: The agent directly selects the action with the highest current probability, i.e.,
a* = argmax_a π(a|s).- Value Function: A key function for evaluating the long-term value of a state or a state-action pair, representing a prediction of future cumulative reward.
- State-Value Function V_π(s): Represents the expected cumulative return starting from state
sunder policyπ.V_π(s) = E_π[ G_t | S_t = s ] = E_π[ Σ_{k=0}^{∞} γ^k R_{t+k+1} | S_t = s ], wheres ∈ S.- Action-Value Function Q_π(s, a): Represents the expected cumulative return starting from state
s, taking actiona, and thereafter following policyπ.Q_π(s, a) = E_π[ G_t | S_t = s, A_t = a ] = E_π[ Σ_{k=0}^{∞} γ^k R_{t+k+1} | S_t = s, A_t = a ].- Here,
γ(0 ≤ γ ≤ 1) is the discount factor, used to weigh the importance of immediate versus future rewards;E_π[·]denotes the expectation under policyπ.
RLHF 技术框架:奖励模型与近端策略优化(PPO)
RLHF Technical Framework: Reward Model and Proximal Policy Optimization (PPO)
基于人类反馈的强化学习(RLHF)主要分为两个核心步骤:奖励模型训练和近端策略优化。奖励模型通过学习人类标注的偏好数据来模拟人类的评判标准,其作用是评估模型回复的有用性、无害性等综合质量。这个模型为后续的强化学习训练提供了稳定的奖励信号来源。在获得奖励模型后,便可以使用强化学习算法(如PPO)对初始语言模型进行微调,使其输出逐渐向人类偏好对齐。
Reinforcement Learning from Human Feedback (RLHF) primarily consists of two core steps: Reward Model Training and Proximal Policy Optimization. The reward model learns to simulate human judgment criteria by training on human-annotated preference data. Its role is to evaluate the comprehensive quality of model responses, such as helpfulness and harmlessness. This model provides a stable source of reward signals for the subsequent reinforcement learning training. After obtaining the reward model, reinforcement learning algorithms (like PPO) can be used to fine-tune the initial language model, gradually aligning its outputs with human preferences.
PPO算法实施流程
PPO Algorithm Implementation Process
OpenAI在大多数RLHF任务中使用的算法是近端策略优化(Proximal Policy Optimization, PPO)。PPO是对传统策略梯度方法的改进,有效解决了高方差、训练不稳定等问题,具有较好的可靠性和鲁棒性。PPO在RLHF中的流程如图2所示,涉及四个关键模型:
The algorithm used by OpenAI in most RLHF tasks is Proximal Policy Optimization (PPO). PPO is an improvement over traditional policy gradient methods, effectively addressing issues like high variance and training instability, offering good reliability and robustness. The process of PPO in RLHF is shown in Figure 2, involving four key models:
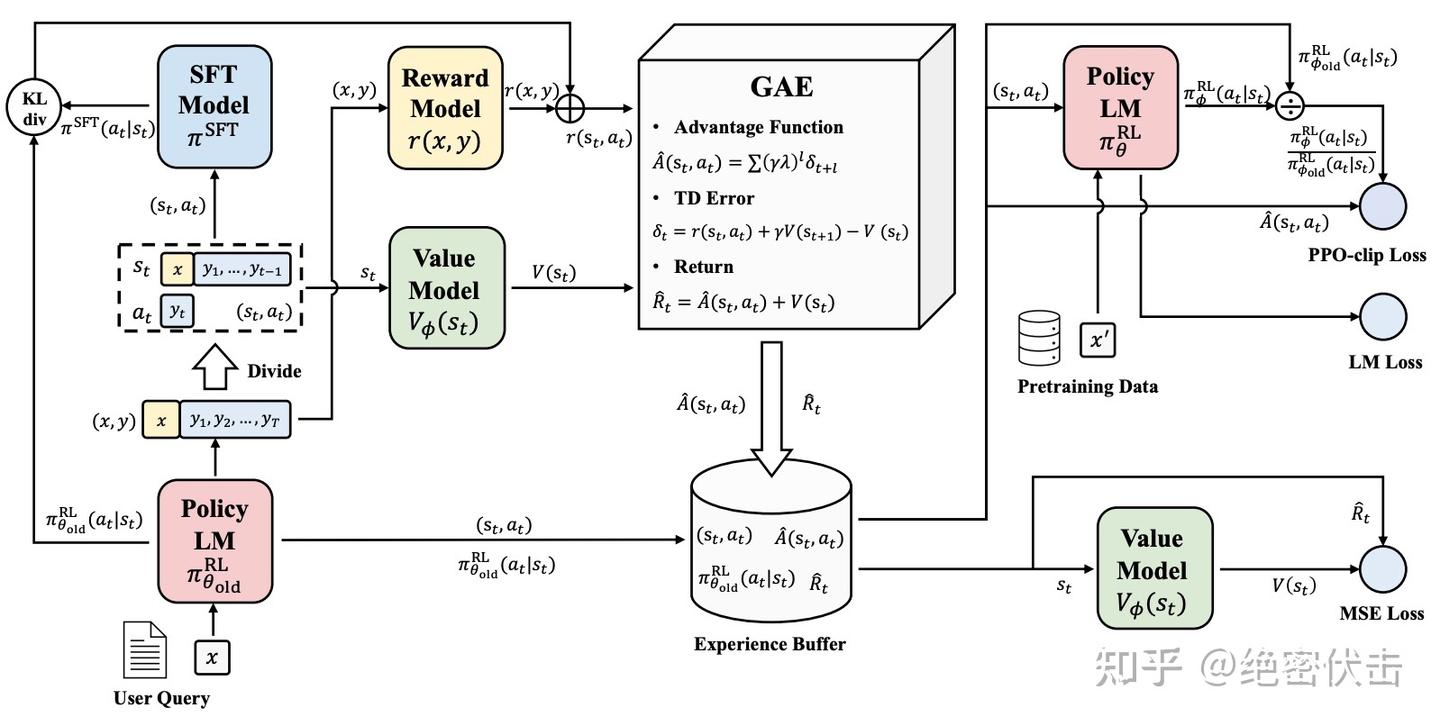
- 策略模型(Policy Model):即需要被微调的主语言模型,负责根据输入提示(Prompt)生成回复。
- 奖励模型(Reward Model):基于人类偏好训练的模型,为策略模型生成的回复给出一个标量奖励分数,评估其质量。
- 评论模型(Critic Model):一个估计状态价值函数
V(s)的模型,用于预测当前状态(对话上下文)下未来所能获得的期望累积奖励。它在训练中用于计算优势函数,帮助更准确地评估每个动作的相对好坏。 - 参考模型(Reference Model):通常是微调前的初始SFT模型的一个固定副本。它在PPO损失函数中起到约束作用,防止策略模型在优化过程中偏离原始模型太远,从而保持生成内容的流畅性和稳定性,避免退化。
- Policy Model: The main language model to be fine-tuned, responsible for generating responses based on input prompts.
常见问题(FAQ)
强化学习相比监督微调,对大语言模型最大的好处是什么?
强化学习提供整体性反馈,能鼓励表达多样性并缓解模型幻觉问题,通过奖励函数系统引导模型行为,更适合生成任务。
RLHF技术如何具体帮助减少AI的“胡说八道”?
通过设计奖励函数,对基于证据的正确回答给高分,对诚实表示“不知道”给中分,对事实错误的幻觉答案严厉惩罚,从而引导模型在知识边界内保持诚实。
从SFT转向RL训练范式,核心优势体现在哪些方面?
核心优势包括:从局部token优化转向全局序列反馈、通过奖励机制增强表达多样性、以及为缓解幻觉提供更灵活的优化框架。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。