ATLAS自适应学习推测系统如何实现4倍大语言模型推理加速?

AI Summary (BLUF)
Together AI introduces ATLAS, an adaptive-learning speculator system that dynamically improves LLM inference performance at runtime, achieving up to 4x faster decoding speeds without manual tuning.
原文翻译: Together AI推出ATLAS自适应学习推测系统,该系统在运行时动态提升大语言模型推理性能,无需手动调优即可实现高达4倍的解码加速。
ATLAS: The Adaptive-Learning Speculator System, Powered by Together Turbo's Latest Research, Delivers Up to 4x Faster LLM Inference
引言:追求极致的推理性能
Introduction: The Pursuit of Peak Inference Performance
在 Together AI,作为一家 AI 原生云服务商,我们对性能有着极致的追求。让大语言模型更快、更便宜、更高效并非一个单一技巧就能解决的问题——它需要在多个维度上进行优化。这正是我们 Together Turbo 套件背后的核心理念,它汇集了我们在算法、架构和模型配方方面的研究成果。我们很高兴推出 自适应学习推测系统,这是首个无需任何手动调优即可实现自动性能提升的推测解码器。
At Together AI, the AI Native Cloud, we are obsessed with performance. Making large language models faster, cheaper, and more efficient is not a one-trick problem—it requires optimization across multiple axes. This is the philosophy behind Together Turbo, our suite of inference innovations that draws from research in algorithms, architectures, and modeling recipes. We are excited to introduce the AdapTive-LeArning Speculator System (ATLAS), the first speculator of its kind that delivers automatic performance improvements without any manual tuning.
ATLAS 提供了一种全新的推测解码方式——一种在运行时动态改进的方式——并且它能与我们其他的 Turbo 技术(如专有的 Together Turbo Speculator 或 Custom Speculators)无缝集成。但为什么要创建一个自适应学习的推测系统呢?
ATLAS offers a new way of doing speculative decoding—one that dynamically improves at runtime—and it fits seamlessly alongside our other Turbo techniques like the proprietary Together Turbo Speculator or Custom Speculators. But why create an adaptive-learning speculator system?
标准的推测器是为通用工作负载训练的。自定义推测器是针对您的特定数据进行训练的,但仅限于某个特定时间点的数据快照。然而,随着工作负载的演变(代码库增长、流量模式变化、请求分布改变),即使是高度定制的推测器也可能落后。相比之下,ATLAS 会随着使用情况自动进化,从历史模式和实时流量中学习,持续地与目标模型的行为实时对齐。这意味着您使用我们的推理服务越多,ATLAS 的性能就越好!
Standard speculators are trained for general workloads. Custom speculators are trained on your specific data, but only for a specific snapshot in time. However, as the workload evolves (codebase grows, traffic patterns shift, request distributions change), even highly customized speculators can fall behind. In contrast, ATLAS evolves automatically with usage, learning from both historical patterns and live traffic to continuously align with the target model's behaviors in real time. This means the more you use our inference service, the better ATLAS will perform!
基于 Together Turbo Speculator 构建的 ATLAS,在完全适应的场景下,在 DeepSeek-V3.1 上可达 500 TPS,在 Kimi-K2 上可达 460 TPS——比标准解码快 2.65 倍,甚至超越了 Groq 等专用硬件(图 1)。
Built on top of Together Turbo Speculator, ATLAS reaches up to 500 TPS on DeepSeek-V3.1 and up to 460 TPS on Kimi-K2 in a fully adapted scenario—2.65x faster than standard decoding, outperforming even specialized hardware like Groq (Figure 1).

图 1:我们在 NVIDIA HGX B200 上展示了使用 Turbo 推测器和自适应学习推测系统对 DeepSeek-V3.1(上图)和 KIMI-K2-0905(下图)在 Arena Hard 流量下的解码速度。
Figure 1: We show the decoding speed on NVIDIA HGX B200 with our Turbo speculator and the adaptive-learning speculator system for DeepSeek-V3.1 (top) and KIMI-K2-0905 (bottom) with Arena Hard traffic.
1. 推测解码:加速推理的核心杠杆
1. Speculative Decoding: A Core Lever for Accelerating Inference
推测解码是加速推理最强大的手段之一。它不是让目标模型逐步生成每个令牌,而是由一个更快的 推测器(也称为 草稿模型)提前预测多个令牌,然后目标模型在单个前向传播中并行 验证 这些令牌。验证过程确保输出的质量与非推测解码的分布相匹配,同时通过一次接受多个令牌来实现加速。
Speculative decoding is one of the most powerful levers for accelerating inference. Instead of having the target model generate every token step by step, a faster speculator (also known as the draft model) proposes multiple tokens ahead, and the target model verifies them in parallel in a single forward pass. The verification process ensures that the quality of the output matches the distribution of non-speculative decoding, while achieving speedups by accepting many tokens at a time.
整体速度受接受率 $α$(即目标模型同意推测器草拟令牌的频率)以及草稿模型相对于目标模型的相对延迟 $c$ 的影响。通常,参数更多、规模更大的推测器由于其更高的容量而能产生更高的接受率,但生成草稿令牌的速度较慢。因此,进步来自两个方面:对齐草稿模型和目标模型以提高 $α$(训练目标、数据和算法),以及设计在保持 $α$ 的同时降低 $c$ 的草稿模型/内核(稀疏性、量化、轻量级和内核高效架构)。最佳平衡点在于高 $α$ 与低 $c$ 的结合,从而最小化端到端延迟。
The overall speed is influenced by the acceptance rate $α$ (i.e., how often the target model agrees with the drafted tokens from the speculator) and the relative latency $c$ of the draft versus the target. Typically, larger speculators with more parameters yield higher acceptance rates due to their higher capacity but are slower to generate draft tokens. Progress therefore comes from both sides: aligning draft and target models to increase $α$ (training objectives, data, and algorithms) and designing draft models/kernels that keep $c$ low while maintaining $α$ (sparsity, quantization, lightweight & kernel-efficient architectures). The sweet spot is where a high $α$ meets a low $c$, minimizing end-to-end latency.
在 Together AI,Turbo 团队开发了高性能推测器,通过融合架构、稀疏性、算法、后训练配方和数据方面的进展,在 NVIDIA Blackwell 上实现了 世界最快的解码速度。我们构建了一个 推测器设计与选择框架,用于确定最佳的推测器架构(宽度/深度、前瞻长度、稀疏性/量化、KV 重用),以及一个 可扩展的训练系统,能够快速、可重复地为最大、最具挑战性的开源目标模型(例如 DeepSeek-V3.1 和 Kimi-K2)训练和部署推测器。例如,虽然 Kimi 没有提供现成的推测器,但我们可以快速训练并部署一个,在相同的硬件和批次设置下,将 Kimi 的开箱即用性能从约 150 TPS 提升到 270+ TPS,同时保持目标模型的质量(见图 1,黄色条)。这条流水线为提供最先进解码延迟的 Turbo 推测器提供了动力,并为接下来的发展奠定了基础:一个能够实时适应工作负载的 自适应学习推测系统。
At Together AI, the Turbo team has developed high-performance speculators that have achieved the world's fastest decoding speeds on NVIDIA Blackwell by drawing on advances across architecture, sparsity, algorithms, post-training recipes, and data. We've built a speculator design and selection framework that determines the optimal speculator architecture (width/depth, lookahead, sparsity/quantization, KV reuse) and a scalable training system that brings up speculators for the largest and most challenging open-source targets quickly and reproducibly (e.g., DeepSeek-V3.1 and Kimi-K2). For instance, while Kimi ships without a ready-to-use speculator, we can train and deploy one rapidly and take Kimi from ~150 TPS out of the box to 270+ TPS on the same hardware and batch settings, while preserving target-model quality (see Figure 1, yellow bars). This pipeline powers Turbo Speculators that deliver state-of-the-art decoding latency, and it sets the stage for what comes next: an Adaptive-Learning Speculator System that adjusts token drafting to the workload in real time.
2. Turbo 自适应学习推测系统详解
2. Introducing Turbo's Adaptive-Learning Speculator System
在 Together AI,我们支持广泛的推理工作负载。但当今的推测解码方法受限于使用在固定数据集上训练的 静态 推测器。一旦部署,推测器就无法适应,如果输入分布发生变化,性能就会下降。这个问题在无服务器、多租户环境中尤为突出,因为输入的多样性极高。新用户不断涌入,并带来独特的、固定推测器在训练期间可能从未见过的工作负载。此外,这些推测器通常使用 固定的前瞻长度,无论推测器的置信度如何,都预测相同数量的令牌。简而言之,静态推测器无法跟上变化。
At Together AI, we power a broad range of inference workloads. But today's speculative decoding methods are constrained to using a static speculator, trained on a fixed dataset. Once deployed, the speculator cannot adapt, leading to degrading performance if the input distribution evolves. This problem is particularly pronounced in serverless, multi-tenant environments, where input diversity is sky-high. New users continuously arrive, and bring with them unique workloads that the fixed speculator may not have seen during training. Furthermore, these speculators typically use a fixed lookahead, predicting the same number of tokens regardless of the speculator's confidence. Put simply, a static speculator cannot keep up.
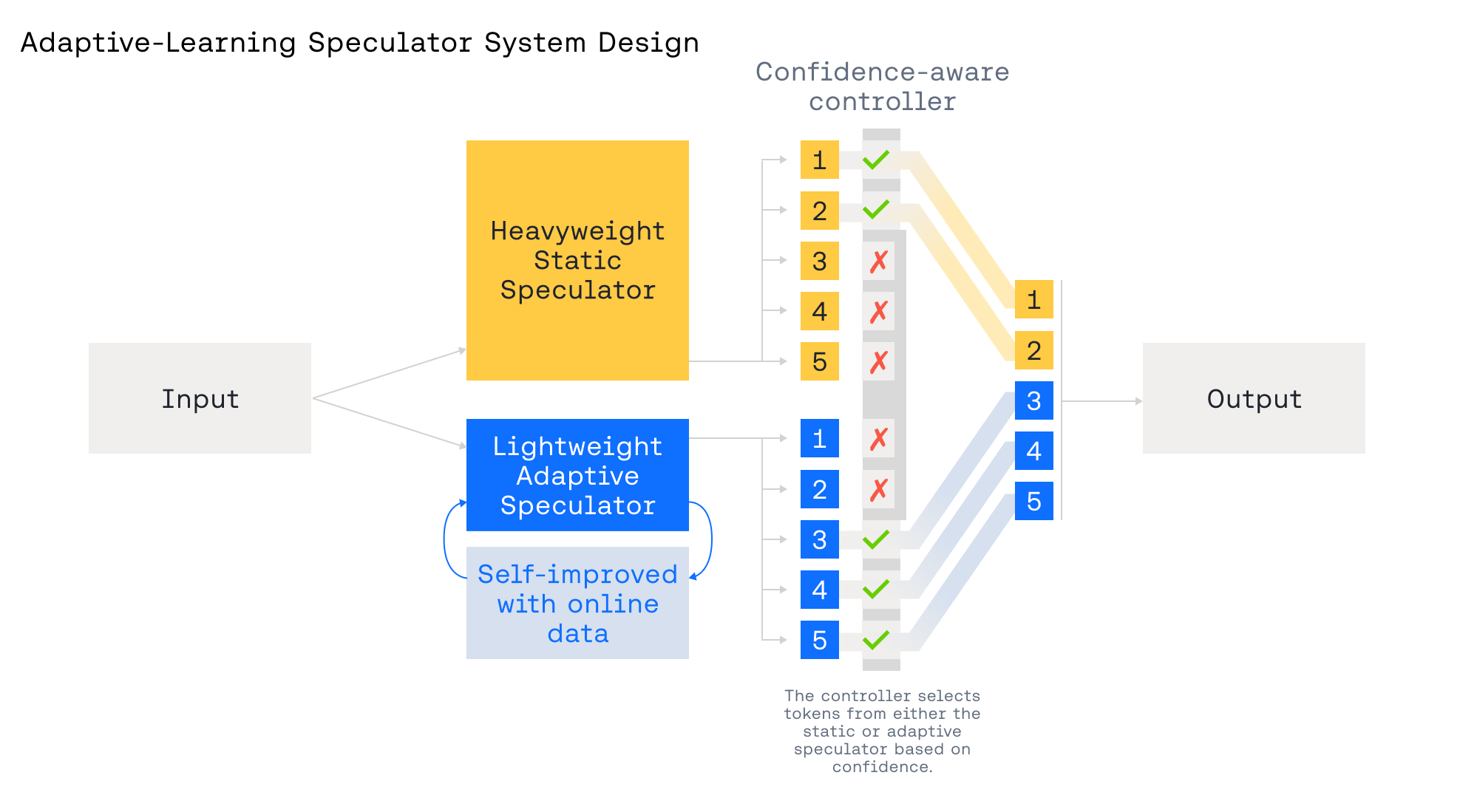
图 3:两个推测器——一个静态,一个自适应——与一个置信度感知控制器协同工作,该控制器在它们之间进行选择并调整前瞻长度,以实现最佳的准确性和速度。
Figure 3: Two speculators—one static, one adaptive—work with a confidence-aware controller that selects between them and adjusts lookahead for optimal accuracy and speed.
为了应对这些限制,我们设计了 自适应学习推测系统,包含两个协同工作的推测器,如图 3 所示:
To address these limitations, we designed the Adaptive-Learning Speculative System with two cooperating speculators, as shown in Figure 3:
- 一个重型的 静态 推测器:在广泛语料库上训练,提供强大、通用的推测能力。
- 一个轻量级的 自适应 推测器:允许根据实时流量进行快速、低开销的更新,即时针对新兴领域进行专业化。
- 一个置信度感知控制器:在每一步选择信任哪个推测器以及使用何种推测前瞻长度,当推测器置信度高时使用更长的前瞻。
- A heavyweight static speculator trained on a broad corpus that provides strong, general speculation.
- A lightweight adaptive speculator that allows for rapid, low-overhead updates from real-time traffic, specializing on-the-fly to emerging domains.
- A confidence-aware controller that chooses which speculator to trust at each step and what speculation lookahead to use, using longer speculations when the speculator has high confidence.
通过静态推测器实现效率护栏。静态 Turbo 推测器充当一个始终在线的速度底线:它在广泛语料库上训练,在不同工作负载下保持稳定,因此当流量变化或自适应路径处于冷启动状态时,TPS 不会崩溃。在 ATLAS 中,我们用它来快速启动速度并提供故障安全回退——如果检测到置信度下降或分布漂移,控制器会缩短前瞻长度或切换回静态路径以保持延迟,同时自适应推测器重新学习。
Efficiency Guardrail via Static Speculator. The static Turbo Speculator serves as an always-on speed floor: it is trained on a broad corpus and remains stable across workloads, so TPS does not collapse when traffic shifts or the adaptive path is cold. In ATLAS, we use it to jump-start speed and provide a fail-safe fallback—if confidence drops or drift is detected, the controller shortens lookahead or routes back to the static path to preserve latency while the adaptive speculator relearns.
自定义推测器 vs. 自适应学习。我们从之前的研究中了解到,在反映预期使用情况的真实流量样本上训练的 自定义推测器 能带来额外的速度提升。自适应学习推测器使我们能够在实时中实现更深入的定制。例如,在 vibe-coding 会话期间,自适应系统可以为正在编辑且训练期间未见的相关代码文件专门定制一个轻量级推测器,从而进一步提高接受率和解码速度。这种即时专业化是静态推测器难以实现的。
Customized Speculator vs. Adaptive-Learning. We know from our previous studies that a customized speculator trained on samples from real traffic that mirror expected usage delivers an additional speed boost. The Adaptive-Learning Speculator enables us to be even more customized in real time. For instance, during a vibe-coding session, the adaptive system can specialize a lightweight speculator for the relevant code files being edited and not seen during training, further increasing the acceptance rate and decoding speed. This kind of on-the-fly specialization is hard to achieve with static speculators.
加速强化学习训练。强化学习 (RL) 在两个阶段之间交替:(1) 策略执行阶段,当前策略生成轨迹并获得奖励;(2) 更新阶段,使用奖励更新策略。在实践中,策略执行通常是瓶颈,约占总体挂钟时间的 70%。通常,由于策略分布在训练过程中会发生变化,静态推测器会很快与目标策略失准,导致次优的吞吐量。ATLAS 通过在线适应不断演变的策略和特定的 RL 领域来解决这个问题,保持对齐并减少总体策略执行时间。RL 领域特定、迭代的性质进一步实现了快速适应,产生持续且不断增长的速度提升。如图 4 所示,将 ATLAS 应用于 RL-MATH 流水线,随着训练的进行,速度提升不断增加。
Accelerating RL Training. Reinforcement learning (RL) alternates between two phases: (1) a rollout phase, where the current policy generates trajectories and receives rewards, and (2) an update phase, where we use the rewards to update the policy. In practice, rollouts are often the bottleneck, accounting for roughly 70% of total wall-clock time. In general, because the policy distribution shifts throughout training, static speculators quickly fall out of alignment with the target policy, resulting in sub-optimal throughput. ATLAS addresses this by adapting online to the evolving policy and the specific RL domain, maintaining alignment and reducing the overall rollout time. The domain-specific, iterative nature of RL further enables rapid adaptation, yielding sustained and growing speedups. As shown in Figure 4, applying ATLAS to the RL-MATH pipeline produces increasing speedups as training progresses.
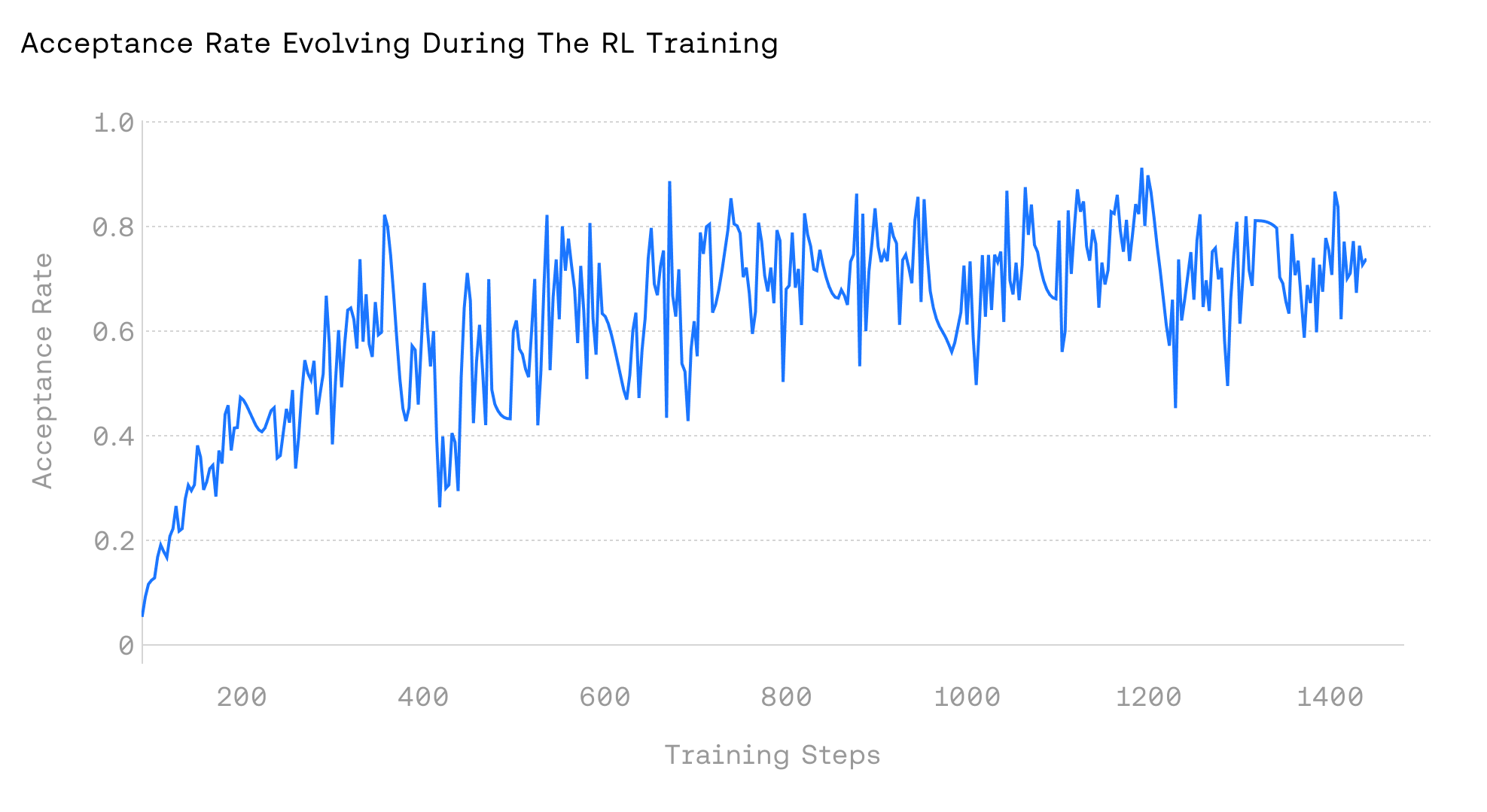
图 4:我们在 NVIDIA Hopper H100 GPU 上使用 ATLAS 对 Qwen/Qwen2.5-7B-Instruct-1M 在 DeepScaler 子集上进行 RL 训练。接受率在 1.4k 训练步数内从低于 10% 上升到高于 80%,从而在不改变 RL 训练算法的情况下,将总体训练时间减少了 60% 以上。
Figure 4: We train Qwen/Qwen2.5-7B-Instruct-1M on DeepScaler subsets using ATLAS for RL on NVIDIA Hopper H100 GPUs. The acceptance rate rises from below 10% to above 80% over 1.4k training steps, resulting in a more than 60% reduction for overall training time without changing RL training algorithm.
作为 Turbo 优化套件的一部分构建。自适应学习推测系统是更广泛的 Turbo 优化套件的核心组成部分,其中每一层优化都会与其他层产生复合效益。如图 5 所示,通过近乎无损的量化(经过校准以保持质量)、Turbo 推测器,最后是自适应学习推测系统,性能逐步提升。套件中的其他优化还包括用于减少首令牌延迟的 TurboBoost-TTFT(未显示),进一步促进了端到端加速
常见问题(FAQ)
ATLAS自适应学习推测系统是什么?
ATLAS是Together AI推出的自适应学习推测系统,能在运行时动态提升大语言模型推理性能,无需手动调优即可实现高达4倍的解码加速。
ATLAS相比传统推测解码有什么优势?
传统推测器可能因工作负载演变而落后,ATLAS能自动从历史模式和实时流量中学习,持续与目标模型行为对齐,使用越多性能越好。
ATLAS在实际应用中能达到什么效果?
在完全适应场景下,ATLAS在DeepSeek-V3.1上可达500 TPS,在Kimi-K2上可达460 TPS,比标准解码快2.65倍,甚至超越专用硬件。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。