GLM是什么?基于自回归空白填充的通用语言模型预训练框架

GLM是清华大学提出的通用语言模型预训练框架,采用自回归空白填充技术,为中文技术社区提供了强大的开源大模型选择。
原文翻译: GLM is a general language model pre-training framework proposed by Tsinghua University, utilizing autoregressive blank filling technology, providing a powerful open-source large model option for the Chinese technical community.
背景
OpenAI 借助 ChatGPT 所点燃的大语言模型(LLM)之火已在全球范围内燃烧了半年有余,而在此期间,OpenAI 与微软所推出的一系列基于 GPT3.5 或 GPT4 模型的 AI 产品也纷纷在不同领域取得了亮眼的表现。
The fire of Large Language Models (LLMs) ignited by OpenAI's ChatGPT has been burning globally for over half a year. During this period, a series of AI products based on GPT-3.5 or GPT-4 models launched by OpenAI and Microsoft have also achieved impressive performance across various domains.
然而令人略感失望的是,作为如今 LLM 圈内绝对的领头羊,OpenAI 并没有遵从其创立初衷,无论是 ChatGPT 早期所使用的的 GPT3、GPT3.5 还是此后推出的 GPT4 模型,OpenAI 都因“暂无法保证其不被滥用”为由拒绝了对模型开源,开启了订阅付费模式。
However, it is somewhat disappointing that OpenAI, as the absolute leader in the current LLM field, has not adhered to its founding principles. Whether it's GPT-3, GPT-3.5 used in the early stages of ChatGPT, or the subsequently released GPT-4 model, OpenAI has refused to open-source the models, citing "inability to guarantee they won't be misused," and has instead adopted a subscription-based paid model.
对于大型科技企业而言,不管是出于秀肌肉还是出于商业竞争目的,自研 LLM 都是一条几乎无可避免的道路。但对于缺少算力和资金的中小企业以及希望基于 LLM 开发衍生产品的开发者来说,选择开源显然是更理想的一条路线。
For large technology companies, developing their own LLMs is an almost unavoidable path, whether for showcasing capabilities or for commercial competition. However, for small and medium-sized enterprises lacking computing power and capital, as well as developers hoping to build derivative products based on LLMs, choosing open-source is clearly a more ideal route.
好在还是有一些选择了开源,那么就目前来看,在LLM领域,都有哪些优质的开源模型可供选择?
Fortunately, some have chosen the open-source path. So, what are the high-quality open-source models currently available in the LLM field?
表1:开源大模型 (Table 1: Open-Source Large Models)
| 开源模型 (Open-Source Model) | 机构 (Institution) |
|---|---|
| GLM | 清华大学 (Tsinghua University) |
| LLaMA | Meta |
| Alpaca | 斯坦福大学 (Stanford University) |
| Dolly | Databricks |
| BLOOM | Hugging Face |
| MiniGPT4 | 阿卜杜拉国王科技大学 (King Abdullah University of Science and Technology) |
| StableLM | Stability AI |
在这些开源大模型中,GLM 由于效果出众而受到大众关注,而且清华大学开源了基于 GLM 架构研发的基座模型:ChatGLM-6B、GLM-130B。
Among these open-source large models, GLM has garnered significant public attention due to its outstanding performance. Tsinghua University has open-sourced foundational models based on the GLM architecture: ChatGLM-6B and GLM-130B.
截止到5月26号,ChatGLM-6B 全球下载达到200万,数百垂直领域模型和国内外应用基于该模型开发。联想、中国民航信息网络公司、360、美团都选择了 GLM-130B 作为基座模型。
As of May 26th, ChatGLM-6B has achieved 2 million global downloads, with hundreds of vertical domain models and applications both domestic and international developed based on it. Companies like Lenovo, TravelSky Technology Limited, 360, and Meituan have all chosen GLM-130B as their foundational model.
[2023.05.28]科技部在中关村论坛上发布的《中国人工智能大模型地图研究报告》显示 ChatGLM-6B 位列大模型开源影响力第一名,千亿基座 GLM-130B、代码模型 CodeGeeX、文生视频模型 CogVideo、GLM 模型同时入围开源影响力前十
[2023.05.26]ChatGLM-6B 全球下载达到200万,数百垂直领域模型和国内外应用基于该模型开发
[2023.05.25]联想接入 ChatGLM-130B API 开发智能打印产品
[2023.05.15]中国民航信息网络公司基于接入 ChatGLM-130B API 开发航旅智能产品
[2023.04.25]清华研究生会基于 ChatGLM-130B 开发的【水木ChatGLM】上线,服务全校同学
[2023.04.24]360基于 ChatGLM-130B 联合研发千亿级大模型【360GLM】
[2023.04.15]值得买部署 ChatGLM-130B 私有化实例用于电商平台产品
[2023.04.14]美团私有化部署 ChatGLM-130B,联合研发【美团GLM】
[2023.04.13]ChatGLM-6B 开源30天内,全球下载量达到75万,GitHub 星标数达到1.7万
[2023.03.31]ChatGLM-6B 推出基于 P-Tuning-v2 的高效参数微调,最低只需7GB显存即可进行模型微调
[2023.03.18]ChatGLM-6B 登上 Hugging Face Trending 榜第一,持续12天
[2023.03.16]ChatGLM-6B 登上 GitHub Trending 榜第一
[2023.03.14]千亿对话模型 ChatGLM 开始内测,60亿参数 ChatGLM-6B 模型开源
[2023.03.10]竹间智能科技接入 ChatGLM-130B API 开发智能客服产品
GLM 模型到底和 GPT 有什么区别,有哪些创新?这篇文章将详细介绍 GLM 的技术细节。
What exactly are the differences between the GLM model and GPT, and what innovations does it offer? This article will delve into the technical details of GLM.
1. 大语言模型预训练范式概述
NLP 任务通常分为三类:
NLP tasks are typically categorized into three types:
- NLU(文本分类、分词、句法分析、信息抽取等) (Natural Language Understanding (text classification, word segmentation, syntactic parsing, information extraction, etc.))
- 有条件生成任务(seq-seq,如翻译任务、QA) (Conditional Generation Tasks (seq-seq, such as translation tasks, QA))
- 无条件生成任务(用预训练模型直接生成内容) (Unconditional Generation Tasks (directly generating content using a pre-trained model))
预训练模型也分为三类,分别是:自编码、自回归、编码解码。三种训练模型分别在前面三种任务中表现良好。
Pre-trained models are also divided into three categories: Autoencoding, Autoregressive, and Encoder-Decoder. These three training paradigms perform well in the aforementioned three types of tasks, respectively.
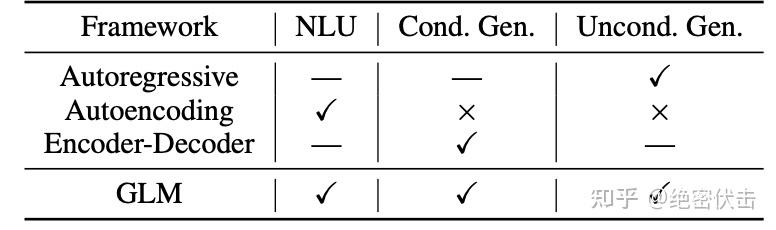
自回归(比如 GPT):从左往右学习的模型,根据句子中前面的单词,预测下一个单词。例如,通过“LM is a typical task in natural language ____”预测单词“processing”。在长文本的生成能力很强,缺点就是单向的注意力机制在 NLU 任务中,不能完全捕捉 token 的内在联系。
Autoregressive (e.g., GPT): A model that learns from left to right, predicting the next word based on preceding words in a sentence. For example, predicting the word "processing" from "LM is a typical task in natural language ____". It excels in long-text generation, but its drawback is that the unidirectional attention mechanism cannot fully capture the intrinsic relationships between tokens in NLU tasks.
自编码(比如 BERT):通过覆盖句中的单词,或者对句子做结构调整,让模型复原单词和词序,从而调节网络参数。例如,可以把 BERT 看成一种自编码器,它通过 Mask 改变了部分 Token,然后试图通过其上下文的其它Token 来恢复这些被 Mask 的 Token。自编码在语言理解相关的文本表示效果很好。缺点是不能直接用于文本生成。
Autoencoding (e.g., BERT): Adjusts network parameters by corrupting words in a sentence (e.g., masking) or altering sentence structure, and then having the model reconstruct the original words and word order. For instance, BERT can be viewed as an autoencoder that masks some tokens and then attempts to recover them using their surrounding context. Autoencoding performs well in text representation for language understanding. Its drawback is that it cannot be directly used for text generation.
编码解码(比如T5):编码器使用双向注意力,解码器使用单向注意力,并且有交叉注意力连接两者,在有条件生成任务(seq-seq)中表现良好(文本摘要,回答生成)。
Encoder-Decoder (e.g., T5): The encoder uses bidirectional attention, the decoder uses unidirectional attention, and cross-attention connects the two. It performs well in conditional generation tasks (seq-seq) like text summarization and answer generation.
这些训练框架都不足以在所有 NLP 中具有竞争力任务。以往的工作(T5)试图通过多任务学习统一不同的框架。然而,由于自编码和自回归的目标性质不同,一个简单的统一的优点不能完全继承这两个框架。
None of these training frameworks are sufficient to be competitive across all NLP tasks. Previous work (e.g., T5) attempted to unify different frameworks through multi-task learning. However, due to the fundamentally different nature of autoencoding and autoregressive objectives, a simple unification cannot fully inherit the advantages of both frameworks.
相比其它大语言模型,GLM 具有以下3个特点:
Compared to other large language models, GLM has the following three characteristics:
- 自编码,随机 MASK 输入中连续跨度的 token (Autoencoding: Randomly masks continuous spans of tokens in the input.)
- 自回归,基于自回归空白填充的方法重新构建跨度中的内容 (Autoregressive: Reconstructs the content within the spans using an autoregressive blank infilling approach.)
- 2维的编码技术,来表示跨间和跨内信息 (2D Encoding Technique: Represents inter-span and intra-span information.)
2. GLM 的核心思想
通常预训练语言模型是指利用大量无标注的文本数据,学习语言的通用知识和表示,然后在特定的下游任务上进行微调或者零样本学习。预训练语言模型在自然语言理解(NLU)和文本生成等多个任务上都取得了显著的效果提升。随着预训练语言模型的发展,模型的参数规模也不断增大,以提高模型的性能和泛化能力。
Typically, pre-trained language models refer to models that leverage large amounts of unlabeled text data to learn general linguistic knowledge and representations, which are then fine-tuned or used for zero-shot learning on specific downstream tasks. Pre-trained language models have achieved significant performance improvements across multiple tasks, including Natural Language Understanding (NLU) and text generation. As these models evolve, their parameter sizes continue to increase to enhance performance and generalization capabilities.
目前预训练语言模型主要有三种类型:自回归模型、自编码模型和编码器-解码器模型。
Currently, pre-trained language models are mainly of three types: Autoregressive models, Autoencoding models, and Encoder-Decoder models.
自回归模型从左到右学习语言模型,适合于长文本生成和少样本学习,但不能捕捉上下文词之间的双向依赖关系。
Autoregressive models learn language models from left to right, making them suitable for long-text generation and few-shot learning, but they cannot capture bidirectional dependencies between contextual words.
自编码模型通过去噪目标学习双向上下文编码器,适合于自然语言理解任务,但不能直接用于文本生成。
Autoencoding models learn a bidirectional contextual encoder through a denoising objective, making them suitable for natural language understanding tasks, but they cannot be directly used for text generation.
编码器-解码器模型结合了双向注意力和单向注意力,适合于有条件的生成任务,如文本摘要和回复生成。
Encoder-Decoder models combine bidirectional and unidirectional attention, making them suitable for conditional generation tasks, such as text summarization and response generation.
这三类语言模型各有优缺点,但没有一种框架能够在所有的自然语言处理任务中都表现出色。一些先前的工作尝试通过多任务学习的方式,将不同框架的目标结合起来,但由于自编码和自回归目标本质上的不同,简单的结合不能充分继承两者的优势。因此,清华大学提出了一种基于自回归空白填充的通用语言模型(GLM),来解决这个挑战。GLM 通过添加二维位置编码和允许任意顺序预测空白区域,改进了空白填充预训练,在自然语言理解任务上超越了 BERT 和 T5。
These three types of language models each have their own strengths and weaknesses, but no single framework excels across all natural language processing tasks. Some prior work attempted to combine objectives from different frameworks through multi-task learning. However, due to the fundamental differences between autoencoding and autoregressive objectives, a simple combination cannot fully inherit the advantages of both. Therefore, Tsinghua University proposed a General Language Model (GLM) based on Autoregressive Blank Infilling to address this challenge. GLM improves blank infilling pre-training by incorporating 2D positional encoding and allowing prediction of blank regions in any arbitrary order, surpassing BERT and T5 on natural language understanding tasks.
GLM 从输入文本中随机挖掉一些连续的词语,然后训练模型按照一定的顺序逐个恢复这些词语。这种方法结合了自编码和自回归两种预训练方式的优点。GLM 还有两个改进点,一个是打乱空白区域的预测顺序,另一个是使用二维位置编码。实验表明,GLM 在参数量和计算成本相同的情况下,能够在 SuperGLUE 基准测试中显著超越BERT,并且在使用相似规模的语料(158GB)预训练时,能够超越 RoBERTa 和 BART。GLM 还能够在自然语言理解和生成任务上显著超越 T5,而且使用的参数和数据更少。
GLM randomly masks out some continuous spans of words from the input text and then trains the model to recover these words one by one in a certain order. This method combines the advantages of both autoencoding and autoregressive pre-training paradigms. GLM introduces two key improvements: shuffling the prediction order of the blank regions and using 2D positional encoding. Experiments show that GLM, with the same parameter count and computational cost, significantly outperforms BERT on the SuperGLUE benchmark. Furthermore, when pre-trained on a corpus of similar scale (158GB), it surpasses RoBERTa and BART. GLM also significantly outperforms T5 on both natural language understanding and generation tasks while using fewer parameters and data.
GLM 是基于模式利用训练(PET),将自然语言理解(NLU)任务转化为人工设计的完形填空问题,模仿人类的语言。与 PET 使用的基于 BERT 的模型不同,GLM 可以自然地处理完形填空问题中的多个词答案,通过自回归的空白填充。模式利用训练(PET)是一种半监督的训练方法,它利用模式来帮助语言模型理解给定的任务。这些模式是用自然语言写的,表示任务的语义。例如,情感分类任务可以转化为“{句子}。这真的很[MASK]”。候选标签也被映射为完形填空问题的答案,称为 verbalizer。在情感分类中,标签“正面”和“负面”被映射为单词“好”和“坏”。
GLM is based on Pattern-Exploiting Training (PET), which reformulates Natural Language Understanding (NLU) tasks into human-designed cloze questions, mimicking human language. Unlike the BERT-based models used in PET, GLM can naturally handle cloze questions with multi-word answers through its autoregressive blank infilling. Pattern-Exploiting Training (PET) is a semi-supervised training method that uses patterns to help language models understand a given task. These patterns are written in natural language and represent the semantics of the task. For example, a sentiment classification task can be transformed into "{SENTENCE}. It was really [MASK]." Candidate labels are also mapped to answers for the cloze question, known as a verbalizer. In sentiment classification, the labels "positive" and "negative" are mapped to the words "good" and "bad."
3. GLM 预训练架构
清华大学提出了一种基于自回归空白填充目标的通用预训练框架 GLM。GLM 将 NLU 任务转化为包含任务描述的完形填空问题,可以通过自回归生成的方式来回答。自回归空白填充目标是指在输入文本中随机挖去一些连续的文本片段,然后训练模型按照任意顺序重建这些片段。完形填空问题是指在输入文本中用一个特殊的符号(如[MASK])替换掉一个或多个词,然后训练模型预测被替换掉的词。
Tsinghua University proposed a general pre-training framework called GLM based on an autoregressive blank infilling objective. GLM reformulates NLU tasks into cloze questions containing task descriptions, which can be answered via autoregressive generation. The autoregressive blank infilling objective involves randomly removing some continuous text spans from the input text and then training the model to reconstruct these spans in an arbitrary order. A cloze question refers to replacing one or more words in the input text with a special symbol (e.g., [MASK]) and training the model to predict the replaced words.
3.1 预训练目标
3.1.1 自回归空白填充
GLM 是通过优化一个自回归空白填充目标来训练的。给定一个输入文本 $\bm{x}=\left[ x_1,...,x_n \right]$ ,从中采样多个文本片段 $\left{ \bm{s}1,...,\bm{s}m \right}$ ,其中每个片段 $\bm{s}i$ 对应于 $\bm{x}$ 中的一系列连续的词 $\left[ s{i,1},...,s{i,l_i} \right]$ 。每个片段都用一个单独的 [MASK] 符号替换,形成一个损坏的文本 $\bm{x}{\text{corrupt}}$。模型以自回归的方式从损坏的文本中预测缺失的词,这意味着在预测一个片段中的缺失词时,模型可以访问损坏的文本和之前预测的片段。为了充分捕捉不同片段之间的相互依赖关系,我们随机打乱片段的顺序,类似于排列语言模型。令 $Z_m$ 为长度为 $m$ 的索引序列 $\left[ 1,2,...,m \right]$ 的所有可能排列的集合,令 $\bm{s}_{z<i}\in\left[
常见问题(FAQ)
GLM模型与GPT模型的主要区别是什么?
GLM采用自回归空白填充的预训练目标,能同时处理理解和生成任务,而GPT主要基于自回归语言建模,更侧重于生成。
GLM模型有哪些实际应用案例?
ChatGLM-6B全球下载超200万次,联想、360、美团等公司基于GLM-130B开发了智能打印、360GLM、美团GLM等产品。
GLM的核心创新思想是什么?
GLM的核心思想是通过自回归空白填充统一自然语言理解和生成任务,其预训练架构能灵活处理不同长度的文本片段。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。