GraphRAG如何利用知识图谱增强LLM对私有数据集的推理能力?

AI Summary (BLUF)
Microsoft Research's GraphRAG enhances LLM capabilities by generating knowledge graphs from private datasets, significantly improving question-answering performance and enabling whole-dataset reasoning through graph machine learning.
原文翻译: 微软研究院的GraphRAG通过从私有数据集中生成知识图谱,显著提升大型语言模型的能力,通过图机器学习大幅改善问答性能并实现全数据集推理。

GraphRAG 技术概览图
编者注,2024年4月2日 – 图1已更新,以澄清每个来源的出处。
Editor’s note, Apr. 2, 2024 – Figure 1 was updated to clarify the origin of each source.
大型语言模型(LLM)面临的最大挑战和机遇,在于将其强大的能力扩展到解决其训练数据之外的问题,并对从未见过的数据取得可比的结果。这为数据调查开辟了新的可能性,例如在数据集上进行有上下文和依据的主题与语义概念识别。在本文中,我们将介绍由微软研究院创建的 GraphRAG,它是在增强 LLM 能力方面的一项重大进展。
Perhaps the greatest challenge – and opportunity – of LLMs is extending their powerful capabilities to solve problems beyond the data on which they have been trained, and to achieve comparable results with data the LLM has never seen. This opens new possibilities in data investigation, such as identifying themes and semantic concepts with context and grounding on datasets. In this post, we introduce GraphRAG, created by Microsoft Research, as a significant advance in enhancing the capability of LLMs.
检索增强生成(RAG)是一种基于用户查询搜索信息,并将结果作为生成 AI 答案参考的技术。该技术是大多数基于 LLM 的工具的重要组成部分,且多数 RAG 方法使用向量相似性作为搜索技术。GraphRAG 利用 LLM 生成的知识图谱,在对复杂信息进行文档分析时,显著提升了问答性能。这建立在我们最近的研究基础上,该研究指出了在私有数据集上进行发现时提示增强的强大力量。这里,我们将私有数据集定义为 LLM 未在其上训练且从未见过的数据,例如企业的专有研究、商业文档或通信。基准 RAG 被创建来帮助解决这个问题,但我们观察到基准 RAG 在某些情况下表现非常差。例如:
Retrieval-Augmented Generation (RAG) is a technique to search for information based on a user query and provide the results as reference for an AI answer to be generated. This technique is an important part of most LLM-based tools and the majority of RAG approaches use vector similarity as the search technique. GraphRAG uses LLM-generated knowledge graphs to provide substantial improvements in question-and-answer performance when conducting document analysis of complex information. This builds upon our recent research, which points to the power of prompt augmentation when performing discovery on private datasets. Here, we define private dataset as data that the LLM is not trained on and has never seen before, such as an enterprise’s proprietary research, business documents, or communications. Baseline RAG was created to help solve this problem, but we observe situations where baseline RAG performs very poorly. For example:
- 基准 RAG 难以“连接点”。当回答问题需要通过共享属性遍历分散的信息片段以提供新的综合见解时,就会出现这种情况。
- 基准 RAG 在被要求整体理解大型数据集合甚至单个大型文档中的汇总语义概念时表现不佳。
- Baseline RAG struggles to connect the dots. This happens when answering a question requires traversing disparate pieces of information through their shared attributes in order to provide new synthesized insights.
- Baseline RAG performs poorly when being asked to holistically understand summarized semantic concepts over large data collections or even singular large documents.
为了解决这个问题,技术社区正在努力开发扩展和增强 RAG 的方法。微软研究院的新方法 GraphRAG,使用 LLM 基于私有数据集创建知识图谱。然后在查询时,该图谱与图机器学习一起用于执行提示增强。GraphRAG 在回答上述两类问题时显示出显著改进,其表现出的智能或掌握能力优于先前应用于私有数据集的其他方法。
To address this, the tech community is working to develop methods that extend and enhance RAG. Microsoft Research’s new approach, GraphRAG, uses the LLM to create a knowledge graph based on the private dataset. This graph is then used alongside graph machine learning to perform prompt augmentation at query time. GraphRAG shows substantial improvement in answering the two classes of questions described above, demonstrating intelligence or mastery that outperforms other approaches previously applied to private datasets.
将 RAG 应用于私有数据集
Applying RAG to private datasets
为了展示 GraphRAG 的有效性,让我们从使用“新闻文章中的暴力事件信息”(VIINA)数据集的一项调查开始。选择该数据集是因为其复杂性以及存在不同意见和部分信息。这是一个混乱的现实世界测试案例,其时间足够近,未被包含在 LLM 基础模型的训练中。
To demonstrate the effectiveness of GraphRAG, let’s start with an investigation using the Violent Incident Information from News Articles (VIINA) dataset. This dataset was chosen due to its complexity and the presence of differing opinions and partial information. It is a messy real-world test case that was recent enough not to be included in the LLM base model’s training.
在这项研究中,我们使用 2023 年 6 月来自俄罗斯和乌克兰新闻源的数千篇翻译成英文的新闻文章,创建一个私有数据集,我们将在此数据集上执行基于 LLM 的检索。该数据集太大,无法放入 LLM 的上下文窗口,因此需要 RAG 方法。
For this research, we use thousands of news articles from both Russian and Ukrainian news sources for the month of June 2023, translated into English, to create a private dataset on which we will perform our LLM-based retrieval. The dataset is far too large to fit into an LLM context window, thus demanding a RAG approach.
我们从一个探索性查询开始,向基准 RAG 系统和我们的新方法 GraphRAG 提出:
We start with an exploratory query, which we pose to both a baseline RAG system and to our new approach, GraphRAG:
查询:“什么是 Novorossiya?”
Query: “What is Novorossiya?”
| 基准 RAG | GraphRAG |
|---|---|
| 所提供的上下文中未提及“Novorossiya”一词。然而,为了提供一些信息,Novorossiya 或新俄罗斯,是一个历史术语,指代 18 世纪被俄罗斯帝国征服的乌克兰南部地区。近年来,该术语被乌克兰东部的俄罗斯支持的分裂分子复活,用来指代他们声称的领土,但并未被国际机构正式承认为一个独立实体。 | Novorossiya,也称为新俄罗斯,是一个具有历史和当代意义的术语。历史上,它指的是俄罗斯帝国南部的一个地区,现在是乌克兰的一部分。在当代语境中,它被亲俄分裂分子用来指代乌克兰的某些地区 [数据:实体 (6494, 912, 6493)]。 Novorossiya 一词已在乌克兰的政治运动背景下使用,特别是被俄罗斯民族主义者使用。该运动与破坏乌克兰稳定和创建所谓的“Novorossiya”的努力有关 [数据:实体 (912);关系 (15211, 15206)]。该术语也被用来表示乌克兰的一个分裂主义国家,称为新俄罗斯联邦共和国 (FRN) [数据:实体 (7690)]。 |
在这些结果中,我们可以看到两个系统都表现良好——突显了基准 RAG 表现良好的一类查询。让我们尝试一个需要“连接点”的查询:
In these results, we can see both systems perform well – highlighting a class of query on which baseline RAG performs well. Let’s try a query that requires connecting the dots:
查询:“Novorossiya 做了什么?”
Query: “What has Novorossiya done?”
| 基准 RAG | GraphRAG |
|---|---|
| 文本未提供关于 Novorossiya 做了什么的具体信息。 | Novorossiya,乌克兰的一个政治运动,参与了一系列破坏性活动,特别是针对乌克兰的各种实体 [实体 (6494, 912)]。该运动与破坏多个乌克兰实体财产的计划有关,包括 Rosen、敖德萨罐头厂、敖德萨地区广播电视传输中心以及乌克兰国家电视公司 [关系 (15207, 15208, 15209, 15210)]。除此之外,Novorossiya 还与破坏 Roshen、敖德萨音乐学院工厂、敖德萨地区广播电视传输中心以及乌克兰国家电信公司财产的计划有关 [关系 (8329, 8330, 8331, 8332)]。此外,Novorossiya 被牵连进炸毁乌克兰最大国有银行 PrivatBank 自动取款机的计划中 [关系 (8335, 8335)]。 乌克兰总检察长办公室报告了 Novorossiya 的创建,表明政府对该运动活动的知晓和潜在关切 [关系 (8264, 8264)]。Novorossiya 的破坏性活动对目标实体产生了重大影响,并可能加剧了该地区持续的紧张局势和冲突。 总之,Novorossiya 参与了一系列针对乌克兰各种实体的破坏性活动。这些活动对目标实体产生了重大影响,并可能加剧了该地区持续的紧张局势和冲突。乌克兰政府通过总检察长办公室承认了 Novorossiya 的存在和活动,表明了对该运动行动的一定程度的关切。 |
基准 RAG 未能回答这个问题。查看插入上下文窗口的源文档(图1),没有一个文本片段讨论 Novorossiya,导致了这次失败。
Baseline RAG fails to answer this question. Looking at the source documents inserted into the context window (Figure 1), none of the text segments discuss Novorossiya, resulting in this failure.

图1:基准 RAG 检索到的上下文
Figure 1: Baseline RAG retrieved context
相比之下,GraphRAG 方法在查询中发现了实体 Novorossiya。这使得 LLM 能够在图谱中定位自己,并产生一个包含通过链接到原始支持文本的可追溯性的优质答案。例如,下面的图2显示了 LLM 用于生成“Novorossiya 被牵连进炸毁自动取款机的计划”这一陈述的确切内容。我们看到来自原始源文档(英文翻译后)的片段,LLM 用它来支持 Novorossiya 通过图中两个实体之间存在的关系将特定银行作为目标的断言。
In comparison, the GraphRAG approach discovered an entity in the query, Novorossiya. This allows the LLM to ground itself in the graph and results in a superior answer that contains provenance through links to the original supporting text. For example, Figure 2 below shows the exact content the LLM used for the LLM-generated statement, “Novorossiya has been implicated in plans to blow up ATMs.” We see the snippet from the raw source documents (after English translation) that the LLM used to support the assertion that a specific bank was a target for Novorossiya via the relationship that exists between the two entities in the graph.
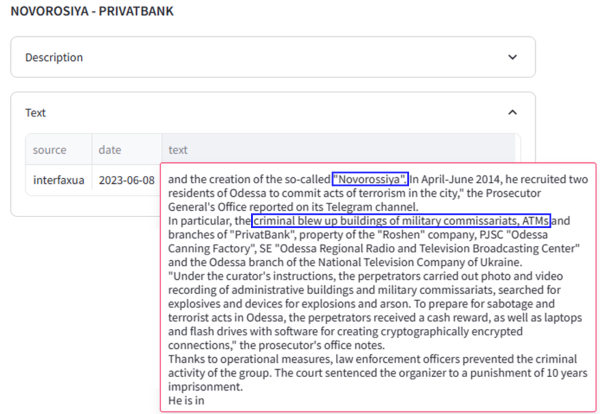
图2:GraphRAG 可追溯性
Figure 2: GraphRAG provenance
通过使用 LLM 生成的知识图谱,GraphRAG 极大地改进了 RAG 的“检索”部分,用更高相关性的内容填充上下文窗口,从而产生更好的答案并捕获证据可追溯性。
By using the LLM-generated knowledge graph, GraphRAG vastly improves the “retrieval” portion of RAG, populating the context window with higher relevance content, resulting in better answers and capturing evidence provenance.
能够信任和验证 LLM 生成的结果始终很重要。我们关心结果是否事实正确、连贯,并准确代表源材料中的内容。GraphRAG 在生成每个响应时提供可追溯性或来源依据信息。它证明答案是基于数据集的。为每个断言提供随时可用的引用来源,也使人类用户能够快速准确地根据原始源材料直接审核 LLM 的输出。
Being able to trust and verify LLM-generated results is always important. We care that the results are factually correct, coherent, and accurately represent content found in the source material. GraphRAG provides the provenance, or source grounding information, as it generates each response. It demonstrates that an answer is grounded in the dataset. Having the cited source for each assertion readily available also enables a human user to quickly and accurately audit the LLM’s output directly against the original source material.
然而,使用 GraphRAG 的可能性不止于此。
However, this isn’t all that’s possible using GraphRAG.
全数据集推理
Whole dataset reasoning
基准 RAG 在处理需要聚合整个数据集信息以构建答案的查询时表现不佳。诸如“数据中的前 5 大主题是什么?”这类查询表现极差,因为基准 RAG 依赖于对数据集中语义相似的文本内容进行向量搜索。查询本身没有任何内容可以将其导向正确的信息。
Baseline RAG struggles with queries that require aggregation of information across the dataset to compose an answer. Queries such as “What are the top 5 themes in the data?” perform terribly because baseline RAG relies on a vector search of semantically similar text content within the dataset. There is nothing in the query to direct it to the correct information.
然而,使用 GraphRAG,我们可以回答此类问题,因为 LLM 生成的知识图谱结构告诉我们整个数据集的结构(从而主题)。这使得私有数据集能够被组织成有意义的、预先汇总的语义集群。LLM 在响应用户查询时使用这些集群来总结这些主题。
However, with GraphRAG we can answer such questions, because the structure of the LLM-generated knowledge graph tells us about the structure (and thus themes) of the dataset as a whole. This allows the private dataset to be organized into meaningful semantic clusters that are pre-summarized. The LLM uses these clusters to summarize these themes when responding to a user query.
我们通过向两个系统提出以下问题来说明全数据集推理能力:
We illustrate whole-dataset reasoning abilities by posing the following question to the two systems:
查询:“数据中的前 5 大主题是什么?”
Query: “What are the top 5 themes in the data?”
| 基准 RAG | GraphRAG |
|---|---|
| 1. 改善城市生活质量和城市发展。 2. 弗拉基米尔·普京与阿拉伯联合酋长国总统穆罕默德·本·扎耶德·阿勒纳哈扬的会晤。 3. 俄罗斯地区投资环境国家评级。 4. 俄罗斯经济状况和国内品牌的增长。 5. 关于生命意义和科学在理解生命中的作用讨论。 |
数据呈现了广泛的主题,但可以确定前五大最普遍的主题如下: 1. 冲突与军事活动:数据的很大一部分围绕乌克兰的持续冲突,大量报告详细描述了各种实体的军事活动、占领和攻击。该主题包括乌克兰军队、俄罗斯部队以及各种其他军事单位和实体的行动 [数据:报告 (513, 241, 151, 493, 343, +更多)]。 2. 政治和政府实体:许多报告聚焦于政治人物和政府实体,强调他们在当前局势下的角色、关系和行动。这包括克里姆林宫、乌克兰总统、美国国务院以及各种地区行政机构等实体 [数据:报告 (98, 493, 265, 129, 196, +更多)]。 3. 基础设施与环境关切:一些报告强调了潜在的环境影响和基础设施威胁。这些包括工业活动可能造成的环境破坏、洪水危机以及军事冲突对基础设施的威胁 [数据:报告 (308, 154, 201, 348, 216, +更多)]。 4. 社区分析与威胁评估:一些报告提供了对特定社区的详细分析,通常围绕特定地点或实体展开。这些分析通常讨论社区内的关键实体、它们的关系以及任何相关的威胁。许多报告还包括对与其讨论的实体或情况相关的潜在威胁的评估 [数据:报告 (323, 596, 518, 583, 179, +更多)]。 5. 健康、人道主义关切与紧急情况:一些报告关注健康和人道主义问题,例如 Shereshevsky-Turner 综合征社区以及敖德萨地区肠道疾病的潜在风险。数据还涵盖了紧急情况,包括自然灾害、事故和袭击 [数据:报告 (204, 149, 372, 154, 532, +更多)]。 这些主题全面概述了当前局势,突显了问题的复杂性和相互关联性。 |
查看基准 RAG 的结果,我们看到列出的主题中没有一个与两国之间的战争有很大关系。正如预期的那样,向量搜索检索到了不相关的文本,这些文本被插入到 LLM 的上下文中。
Looking at the results from baseline RAG, we see that none of the listed themes has much to do with the war between the two countries. As anticipated, the vector search retrieved irrelevant text, which was inserted into the LLM’s context.
常见问题(FAQ)
GraphRAG是什么,它如何提升LLM的能力?
GraphRAG是微软研究院开发的技术,它通过从私有数据集中生成知识图谱来增强大型语言模型。这种方法利用图机器学习,显著改善了问答性能并实现了对整个数据集的推理能力。
GraphRAG相比传统RAG方法有哪些优势?
传统RAG方法在连接分散信息点和理解大型数据集的整体语义概念时表现不佳。GraphRAG通过生成的知识图谱解决了这些问题,能够更好地进行综合推理和全数据集分析。
GraphRAG主要应用于什么类型的数据?
GraphRAG专门用于处理私有数据集,即LLM未训练过且从未见过的数据,如企业的专有研究、商业文档或通信等,帮助在这些数据上进行有效的发现和推理。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。