KTransformers框架如何通过CPU-GPU异构计算优化LLM推理与微调?

AI Summary (BLUF)
KTransformers is a flexible framework for optimizing large language model inference and fine-tuning through CPU-GPU heterogeneous computing, featuring two core modules: kt-kernel for high-performance inference and kt-sft for efficient fine-tuning.
原文翻译: KTransformers是一个通过CPU-GPU异构计算优化大语言模型推理与微调的灵活框架,包含两个核心模块:kt-kernel用于高性能推理,kt-sft用于高效微调。
🎯 概述
KTransformers 是一个专注于通过 CPU-GPU 异构计算实现大语言模型高效推理与微调的研究项目。该项目已演化为两个核心模块:kt-kernel 和 kt-sft。
KTransformers is a research project focused on efficient inference and fine-tuning of large language models through CPU-GPU heterogeneous computing. The project has evolved into two core modules: kt-kernel and kt-sft.
🔥 近期更新
KTransformers 项目持续迭代,以下为近期关键更新:
The KTransformers project is under continuous iteration. Here are the key recent updates:
- 2026年3月26日:支持仅使用 AVX2 指令集的 CPU 后端进行 KT-Kernel 推理。 (教程)
- 2026年2月13日:支持 MiniMax-M2.5 模型 Day0 推理! (教程)
- 2026年2月12日:支持 GLM-5 模型 Day0 推理! (教程)
- 2026年1月27日:支持 Kimi-K2.5 模型 Day0 推理! (推理教程) (微调教程)
- 2026年1月22日:支持 CPU-GPU 专家调度、原生 BF16 及 FP8 逐通道精度 以及 AutoDL 统一微调与推理流程。
- Mar 26, 2026: Support AVX2-only CPU backend for KT-Kernel inference. (Tutorial)
- Feb 13, 2026: MiniMax-M2.5 Day0 Support! (Tutorial)
- Feb 12, 2026: GLM-5 Day0 Support! (Tutorial)
- Jan 27, 2026: Kimi-K2.5 Day0 Support! (Inference Tutorial) (SFT Tutorial)
- Jan 22, 2026: Support CPU-GPU Expert Scheduling, Native BF16 and FP8 per channel Precision and AutoDL unified fine-tuning and inference.
📦 核心模块
🚀 kt-kernel - 高性能推理内核
kt-kernel 是为异构 LLM 推理优化的 CPU 内核操作库,旨在最大化利用 CPU 的计算能力,与 GPU 协同工作以处理超大规模模型。
kt-kernelis a CPU-optimized kernel operations library for heterogeneous LLM inference, designed to maximize CPU computational power and work in tandem with GPUs to handle ultra-large-scale models.

核心特性:
Key Features:
- AMX/AVX 加速:针对 INT4/INT8 量化推理优化的 Intel AMX 及 AVX512/AVX2 内核。
- MoE 优化:具备 NUMA 感知内存管理的高效混合专家模型推理。
- 量化支持:支持 CPU 端 INT4/INT8 量化权重,GPU 端 GPTQ 量化。
- 易于集成:为 SGLang 等框架提供简洁的 Python API。
- AMX/AVX Acceleration: Intel AMX and AVX512/AVX2 optimized kernels for INT4/INT8 quantized inference.
- MoE Optimization: Efficient Mixture-of-Experts inference with NUMA-aware memory management.
- Quantization Support: CPU-side INT4/INT8 quantized weights, GPU-side GPTQ support.
- Easy Integration: Clean Python API for SGLang and other frameworks.
快速开始:
Quick Start:
cd kt-kernel
pip install .
典型用例:
Use Cases:
- 大型 MoE 模型的 CPU-GPU 混合推理。
- 与 SGLang 集成用于生产环境服务。
- 异构专家放置(热专家在 GPU,冷专家在 CPU)。
- CPU-GPU hybrid inference for large MoE models.
- Integration with SGLang for production serving.
- Heterogeneous expert placement (hot experts on GPU, cold experts on CPU).
性能示例:
Performance Examples:
| 模型 (Model) | 硬件配置 (Hardware Configuration) | 总吞吐量 (Total Throughput) | 输出吞吐量 (Output Throughput) |
|---|---|---|---|
| DeepSeek-R1-0528 (FP8) | 8×L20 GPU + Xeon Gold 6454S | 227.85 tokens/s | 87.58 tokens/s (8路并发) |
👉 完整文档 →
🎓 kt-sft - 微调框架
kt-sft 是 KTransformers 与 LLaMA-Factory 的集成框架,专门用于超大规模 MoE 模型的高效微调。
kt-sftis an integration framework of KTransformers and LLaMA-Factory, specifically designed for efficient fine-tuning of ultra-large-scale MoE models.
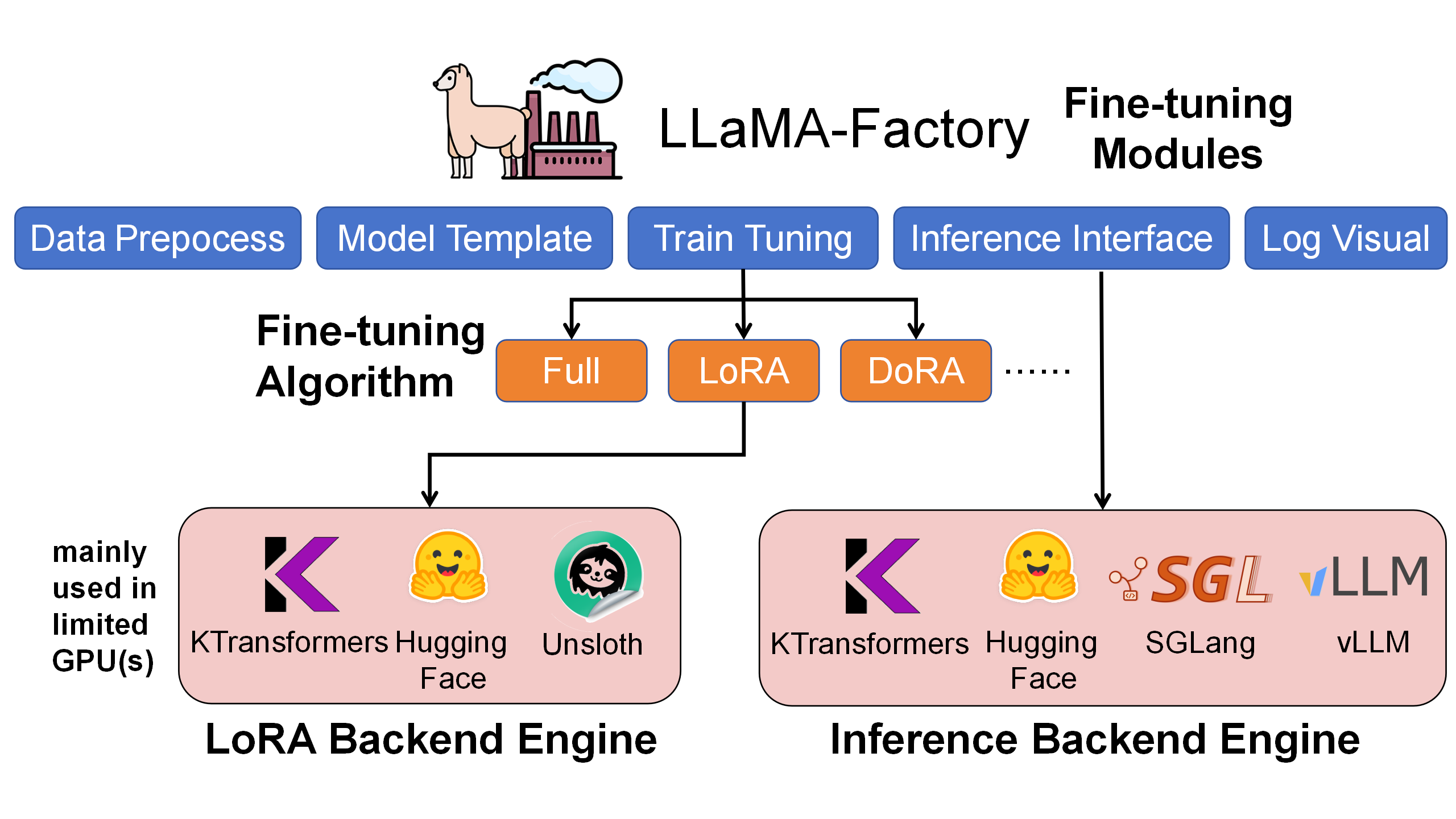
核心特性:
Key Features:
- 资源高效:仅需 70GB GPU 显存 + 1.3TB 内存即可微调 671B 的 DeepSeek-V3 模型。
- LoRA 支持:支持结合异构加速的完整 LoRA 微调。
- LLaMA-Factory 集成:与流行的微调框架无缝集成。
- 生产就绪:支持对话、批量推理和指标评估。
- Resource Efficient: Fine-tune 671B DeepSeek-V3 with just 70GB GPU memory + 1.3TB RAM.
- LoRA Support: Full LoRA fine-tuning with heterogeneous acceleration.
- LLaMA-Factory Integration: Seamless integration with popular fine-tuning framework.
- Production Ready: Chat, batch inference, and metrics evaluation.
性能示例:
Performance Examples:
| 模型 (Model) | 配置 (Configuration) | 吞吐量 (Throughput) | GPU 显存 (GPU Memory) |
|---|---|---|---|
| DeepSeek-V3 (671B) | LoRA + AMX | ~40 tokens/s | 70GB (多GPU) |
| DeepSeek-V2-Lite (14B) | LoRA + AMX | ~530 tokens/s | 6GB |
快速开始:
Quick Start:
cd kt-sft
# 请按照 kt-sft/README.md 安装环境
USE_KT=1 llamafactory-cli train examples/train_lora/deepseek3_lora_sft_kt.yaml
👉 完整文档 →
🔥 引用
如果您在研究中使用了 KTransformers,请引用我们的论文:
If you use KTransformers in your research, please cite our paper:
@inproceedings{10.1145/3731569.3764843,
title = {KTransformers: Unleashing the Full Potential of CPU/GPU Hybrid Inference for MoE Models},
author = {Chen, Hongtao and Xie, Weiyu and Zhang, Boxin and Tang, Jingqi and Wang, Jiahao and Dong, Jianwei and Chen, Shaoyuan and Yuan, Ziwei and Lin, Chen and Qiu, Chengyu and Zhu, Yuening and Ou, Qingliang and Liao, Jiaqi and Chen, Xianglin and Ai, Zhiyuan and Wu, Yongwei and Zhang, Mingxing},
booktitle = {Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles},
year = {2025}
}
👥 贡献者与团队
KTransformers 由以下团队开发和维护:
Developed and maintained by:
- [MADSys Lab
常见问题(FAQ)
KTransformers框架具体包含哪些核心模块,各自有什么作用?
KTransformers包含两个核心模块:kt-kernel是高性能推理内核,用于优化CPU上的LLM推理;kt-sft是微调框架,专注于高效的大语言模型微调。
KTransformers如何利用CPU-GPU异构计算来优化大语言模型?
该框架通过CPU-GPU异构计算协同工作,kt-kernel最大化利用CPU计算能力处理推理任务,与GPU配合实现高效的大规模模型推理与微调。
KTransformers近期有哪些重要的技术更新?
近期更新包括支持仅用AVX2指令集的CPU推理、新增MiniMax-M2.5等模型的Day0推理支持,以及CPU-GPU专家调度、原生BF16/FP8精度等高级功能。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。