LightRAG如何提升RAG检索效率?2026年图增强框架深度解析

LightRAG introduces a graph-enhanced RAG framework that improves retrieval accuracy and efficiency through dual-level retrieval and incremental knowledge base updates, outperforming existing methods in comprehensive evaluations.
原文翻译: LightRAG提出了一种图增强的RAG框架,通过双级检索和增量知识库更新机制,显著提升了检索准确性和效率,在综合评估中优于现有方法。
摘要
检索增强生成系统通过整合外部知识源来增强大语言模型的能力,使其能够生成更准确、更贴合用户需求的上下文相关回答。然而,现有的RAG系统存在显著局限性,包括依赖扁平化的数据表示和上下文感知能力不足,这可能导致生成的答案碎片化,难以捕捉复杂的相互依赖关系。为应对这些挑战,我们提出了LightRAG,它将图结构引入文本索引和检索过程。这一创新框架采用双层检索系统,从低层和高层知识发现中增强信息的全面检索。此外,图结构与向量表示的融合,促进了相关实体及其关系的高效检索,在保持上下文相关性的同时显著提升了响应速度。增量更新算法的引入进一步增强了这一能力,确保新数据能够及时整合,使系统在快速变化的数据环境中保持高效和响应性。广泛的实验验证表明,与现有方法相比,LightRAG在检索准确性和效率方面均有显著提升。
Retrieval-Augmented Generation (RAG) systems enhance large language models (LLMs) by integrating external knowledge sources, enabling more accurate and contextually relevant responses tailored to user needs. However, existing RAG systems have significant limitations, including reliance on flat data representations and inadequate contextual awareness, which can lead to fragmented answers that fail to capture complex inter-dependencies. To address these challenges, we propose LightRAG, which incorporates graph structures into text indexing and retrieval processes. This innovative framework employs a dual-level retrieval system that enhances comprehensive information retrieval from both low-level and high-level knowledge discovery. Additionally, the integration of graph structures with vector representations facilitates efficient retrieval of related entities and their relationships, significantly improving response times while maintaining contextual relevance. This capability is further enhanced by an incremental update algorithm that ensures the timely integration of new data, allowing the system to remain effective and responsive in rapidly changing data environments. Extensive experimental validation demonstrates considerable improvements in retrieval accuracy and efficiency compared to existing approaches.
技术架构
整体设计
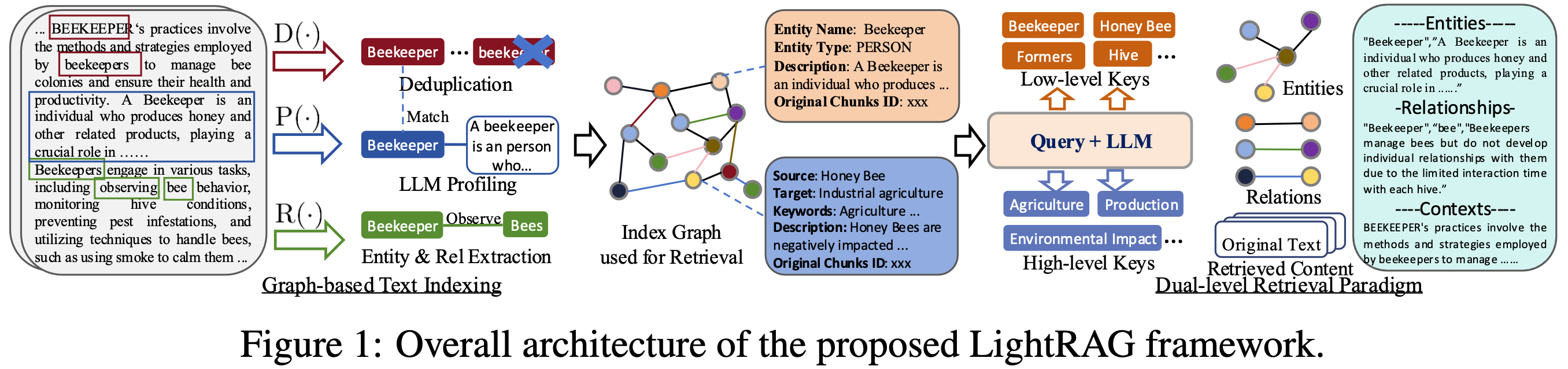
- 图增强的实体与关系提取。 LightRAG通过将文档分割成更小、更易管理的片段来增强检索系统。这一策略允许快速识别和访问相关信息,而无需分析整个文档。接着,我们利用大语言模型来识别和提取各种实体(如人名、日期、地点、事件)以及它们之间的关系。通过此过程收集的信息将用于创建一个全面的知识图谱,突出显示整个文档集合中的联系和洞察。我们基于图的文本索引范式所使用的函数描述如下:
- 提取实体与关系:此函数提示大语言模型识别文本数据中的实体(节点)及其关系(边)。例如,它可以从文本“心脏病专家评估症状以识别潜在的心脏问题”中提取“心脏病专家”和“心脏病”等实体,以及“心脏病专家诊断心脏病”等关系。为提高效率,原始文本被分割成多个块。
- 基于大语言模型的概要生成:我们采用大语言模型驱动的概要生成函数,为每个实体节点和关系边生成一个文本键值对。每个索引键是一个词或短语,用于高效检索,而对应的值是一个文本段落,总结了来自外部数据的相关片段,以辅助文本生成。实体使用其名称作为唯一索引键,而关系可能拥有多个索引键,这些键源自大语言模型的增强,包括来自连接实体的全局主题。
- 去重以优化图操作:最后,我们实现了一个去重函数,用于识别并合并来自原始文本不同片段的相同实体和关系。此过程通过最小化图的规模,有效减少了与图操作相关的开销,从而实现更高效的数据处理。
- Graph-Enhanced Entity and Relationship Extraction. LightRAG enhances the retrieval system by segmenting documents into smaller, more manageable pieces. This strategy allows for quick identification and access to relevant information without analyzing entire documents. Next, we leverage LLMs to identify and extract various entities (e.g., names, dates, locations, and events) along with the relationships between them. The information collected through this process will be used to create a comprehensive knowledge graph that highlights the connections and insights across the entire collection of documents. The functions used in our graph-based text indexing paradigm are described as:
- Extracting Entities and Relationships: This function prompts a LLM to identify entities (nodes) and their relationships (edges) within the text data. For instance, it can extract entities like "Cardiologists" and "Heart Disease," and relationships such as "Cardiologists diagnose Heart Disease" from the text: "Cardiologists assess symptoms to identify potential heart issues." To improve efficiency, the raw text is segmented into multiple chunks.
- LLM Profiling for Key-Value Pair Generation: We employ a LLM-empowered profiling function to generate a text key-value pair for each entity node and relation edge. Each index key is a word or short phrase that enables efficient retrieval, while the corresponding value is a text paragraph summarizing relevant snippets from external data to aid in text generation. Entities use their names as the sole index key, whereas relations may have multiple index keys derived from LLM enhancements that include global themes from connected entities.
- Deduplication to Optimize Graph Operations: Finally, we implement a deduplication function that identifies and merges identical entities and relations from different segments of the raw text. This process effectively reduces the overhead associated with graph operations by minimizing the graph's size, leading to more efficient data processing.
LightRAG通过其基于图的文本索引范式提供了两大优势。第一,全面的信息理解:构建的图结构使得能够从多跳子图中提取全局信息,极大地增强了模型处理跨越多个文档块的复杂查询的能力。第二,增强的检索性能:从图中派生的键值数据结构针对快速精确的检索进行了优化。这为现有方法中常用的、准确性较低的嵌入匹配方法和低效的块遍历技术提供了更优的替代方案。
LightRAG offers two advantages through its graph-based text indexing paradigm. First, comprehensive information understanding: The constructed graph structures enable the extraction of global information from multi-hop subgraphs, greatly enhancing the model's ability to handle complex queries that span multiple document chunks. Second, enhanced retrieval performance: The key-value data structures derived from the graph are optimized for rapid and precise retrieval. This provides a superior alternative to less accurate embedding matching methods and inefficient chunk traversal techniques commonly used in existing approaches.
- 面向增量知识库的快速适应。 为了有效适应不断变化的数据,同时确保回答的准确性和相关性,LightRAG能够增量更新知识库,而无需对整个外部数据库进行完全重新处理。增量更新算法使用与之前相同的基于图的索引步骤来处理新文档。随后,模型通过合并节点和边,将新图数据与原始图数据结合起来。我们实现增量知识库快速适应的两个关键目标是:
- 新数据的无缝集成:通过对新信息应用一致的方法论,增量更新模块使得模型能够在不破坏现有图结构的情况下集成新的外部数据库。这种方法保留了已建立连接的完整性,确保历史数据仍然可访问,同时在避免冲突或冗余的情况下丰富图谱。
- 减少计算开销:通过消除重建整个索引图的需求,此方法减少了计算开销,并促进了新数据的快速同化。因此,模型保持了系统准确性,提供了最新信息,并节约了资源,确保用户获得及时更新,从而提升了整体RAG的有效性。
- Fast Adaptation to Incremental Knowledge Base. To efficiently adapt to evolving data changes while ensuring accurate and relevant responses, LightRAG incrementally updates the knowledge base without the need for complete reprocessing of the entire external database. The incremental update algorithm processes new documents using the same graph-based indexing steps as before. Subsequently, the model combines the new graph data with the original by merging the nodes and edges. Two key objectives guide our approach to fast adaptation for the incremental knowledge base:
- Seamless Integration of New Data: By applying a consistent methodology to new information, the incremental update module allows the model to integrate new external databases without disrupting the existing graph structure. This approach preserves the integrity of established connections, ensuring that historical data remains accessible while enriching the graph without conflicts or redundancies.
- Reducing Computational Overhead: By eliminating the need to rebuild the entire index graph, this method reduces computational overhead and facilitates the rapid assimilation of new data. Consequently, the model maintains system accuracy, provides current information, and conserves resources, ensuring users receive timely updates and enhancing the overall RAG effectiveness.
- 双层检索范式。 为了从特定的文档块及其复杂的相互依赖关系中检索相关信息,LightRAG提出在详细和抽象两个层面生成查询键。
- 具体查询:这类查询是细节导向的,通常引用图中的特定实体,需要精确检索与特定节点或边相关的信息。例如,一个具体查询可能是:“《傲慢与偏见》是谁写的?”
- 抽象查询:相比之下,抽象查询更具概念性,涵盖更广泛的主题、摘要或总体主题,这些并不直接与特定实体挂钩。抽象查询的一个例子是:“人工智能如何影响现代教育?”
- Dual-level Retrieval Paradigm. To retrieve relevant information from both specific document chunks and their complex inter-dependencies, LightRAG proposes generating query keys at both detailed and abstract levels.
- Specific Queries: These queries are detail-oriented and typically reference specific entities within the graph, requiring precise retrieval of information associated with particular nodes or edges. For example, a specific query might be, "Who wrote 'Pride and Prejudice'?"
- Abstract Queries: In contrast, abstract queries are more conceptual, encompassing broader topics, summaries, or overarching themes that are not directly tied to specific entities. An example of an abstract query is, "How does artificial intelligence influence modern education?"
为了适应不同类型的查询,模型在双层检索范式中采用了两种不同的检索策略。这确保了对具体和抽象查询都能有效处理,使系统能够提供符合用户需求的相关回答。
* 低层检索:此层级主要专注于检索特定实体及其相关属性或关系。此层级的查询是细节导向的,旨在提取图中特定节点或边的精确信息。
* 高层检索:此层级处理更广泛的主题和总体主题。此层级的查询聚合了多个相关实体和关系的信息,提供对高层概念和摘要的洞察,而非具体细节。
To accommodate diverse query types, the model employs two distinct retrieval strategies within the dual-level retrieval paradigm. This ensures that both specific and abstract inquiries are addressed effectively, allowing the system to deliver relevant responses tailored to user needs.
* Low-Level Retrieval: This level is primarily focused on retrieving specific entities along with their associated attributes or relationships. Queries at this level are detail-oriented and aim to extract precise information about particular nodes or edges within the graph.
* High-Level Retrieval: This level addresses broader topics and overarching themes. Queries at this level aggregate information across multiple related entities and relationships, providing insights into higher-level concepts and summaries rather than specific details.
通过将图结构与向量表示相结合,模型能够更深入地洞察实体间的相互关系。这种协同作用使检索算法能够有效利用局部和全局关键词,简化搜索过程并提高结果的相关性。
By combining graph structures with vector representations, the model gains a deeper insight into the interrelationships among entities. This synergy enables the retrieval algorithm to effectively utilize both local and global keywords, streamlining the search process and improving the relevance of results.
- 检索增强的答案生成。 利用检索到的信息,LightRAG采用一个通用的大语言模型基于收集的数据生成答案。这些数据包括由概要生成函数产生的相关实体和关系的连接值,其中包含名称、实体和关系的描述以及原始文本的摘录。通过将查询与这些多源文本统一,大语言模型生成符合用户需求的信息性答案,确保与查询意图保持一致。这种方法通过将上下文和查询整合到大语言模型中,简化了答案生成过程。
- Retrieval-Augmented Answer Generation. Utilizing the retrieved information, LightRAG employs a general-purpose LLM to generate answers based on the collected data. This data comprises concatenated values from relevant entities and relations, produced by the profiling function. It includes names, descriptions of entities and relations, and excerpts from the original text. By unifying the query with this multi-source text, the LLM generates informative answers tailored to the user's needs, ensuring alignment with the query's intent. This approach streamlines the answer generation process by integrating both context and query into the LLM model.
实验评估
为许多RAG查询定义真实答案,特别是那些涉及复杂高层语义的查询,具有重大挑战。为此,我们在现有工作基础上,采用了一种基于大语言模型的多维比较方法。我们使用一个强大的大语言模型,具体是GPT-4o-mini,来对每个基线方法与LightRAG进行排序。我们总共使用了四个评估维度,包括:i) 全面性:答案在多大程度上全面涵盖了问题的所有方面和细节?ii) 多样性:答案在提供与问题相关的不同视角和见解方面有多丰富多样?iii) 启发性:答案在多大程度上有效地使读者理解主题并做出明智判断?iv) 整体性:此维度评估前三个标准的累积表现,以确定最佳整体答案。
Defining ground truth for many RAG queries, particularly those involving complex high-level semantics, poses significant challenges. To address this, we build on existing work and adopt an LLM-based multi-dimensional comparison method. We employ a robust LLM, specifically GPT-4o-mini, to rank each baseline against LightRAG. In total, we utilize four evaluation dimensions, including: i) Comprehensiveness: How thoroughly does the answer address all aspects and details of the question? ii) Diversity: How varied and rich is the answer in offering different perspectives and insights related to the question? iii) Empowerment: How effectively does the answer enable the reader to understand the topic and make informed judgments? iv) Overall: This dimension assesses the cumulative performance across the three preceding criteria to identify the best overall answer.
在确定了三个维度的优胜答案后,大语言模型结合这些结果来确定整体上更好的答案。为确保公平评估并减轻提示中答案顺序可能带来的潜在偏见,我们交替放置每个答案的位置。我们相应地计算胜率,最终得出最终结果。
After identifying the winning answer for the three dimensions, the LLM combines the results to determine the overall better answer. To ensure a fair evaluation and mitigate the potential bias that could arise from the order in which the answers are presented in the prompt, we alternate the placement of each answer. We calculate win rates accordingly, ultimately leading to the final results.
LightRAG与现有RAG方法的比较
我们在不同的评估维度和数据集上将LightRAG与每个基线方法进行比较。结果如表1所示。
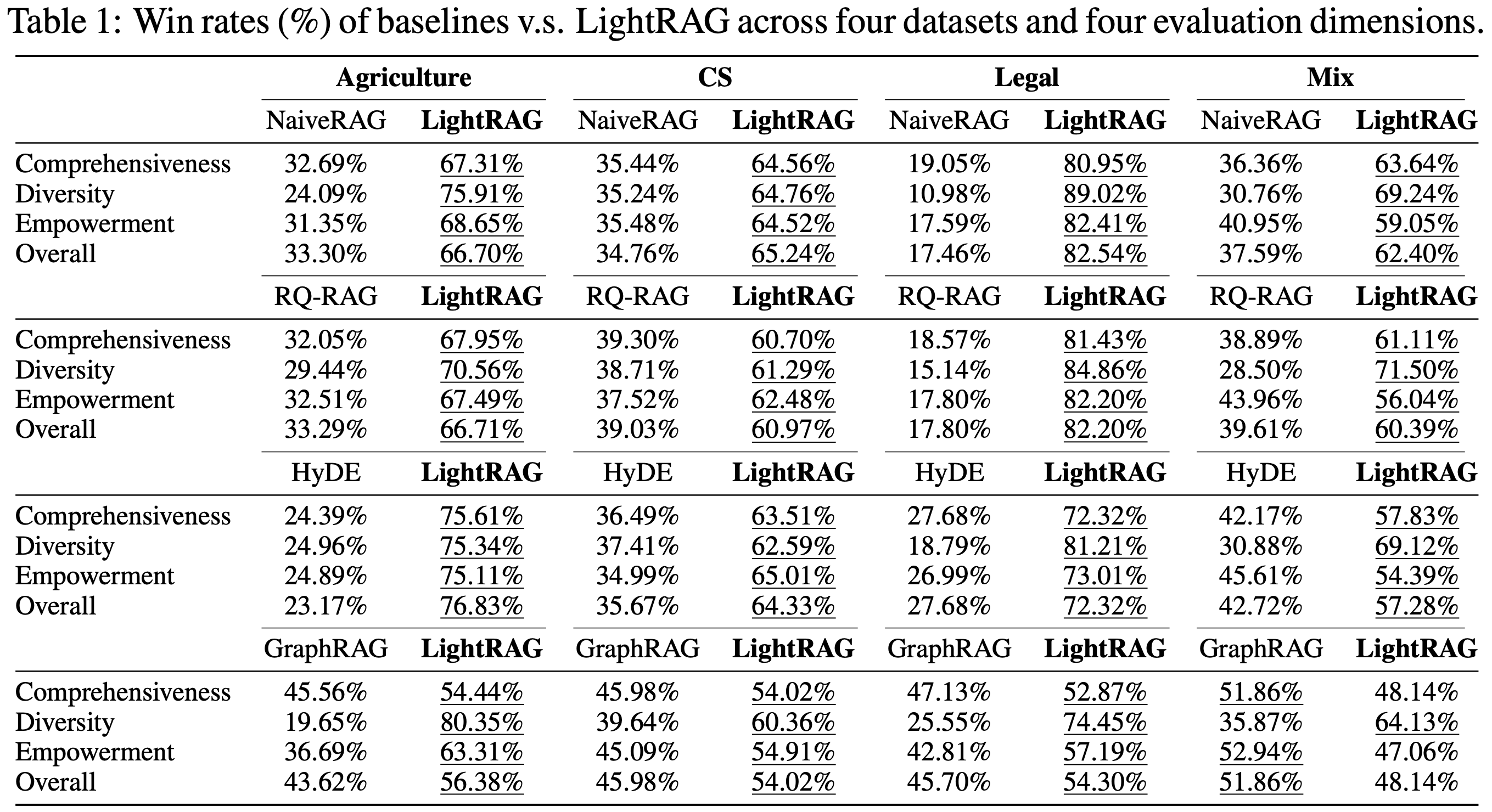
We compare LightRAG against each baseline across various evaluation dimensions and datasets. The results are presented in Table 1.
消融研究
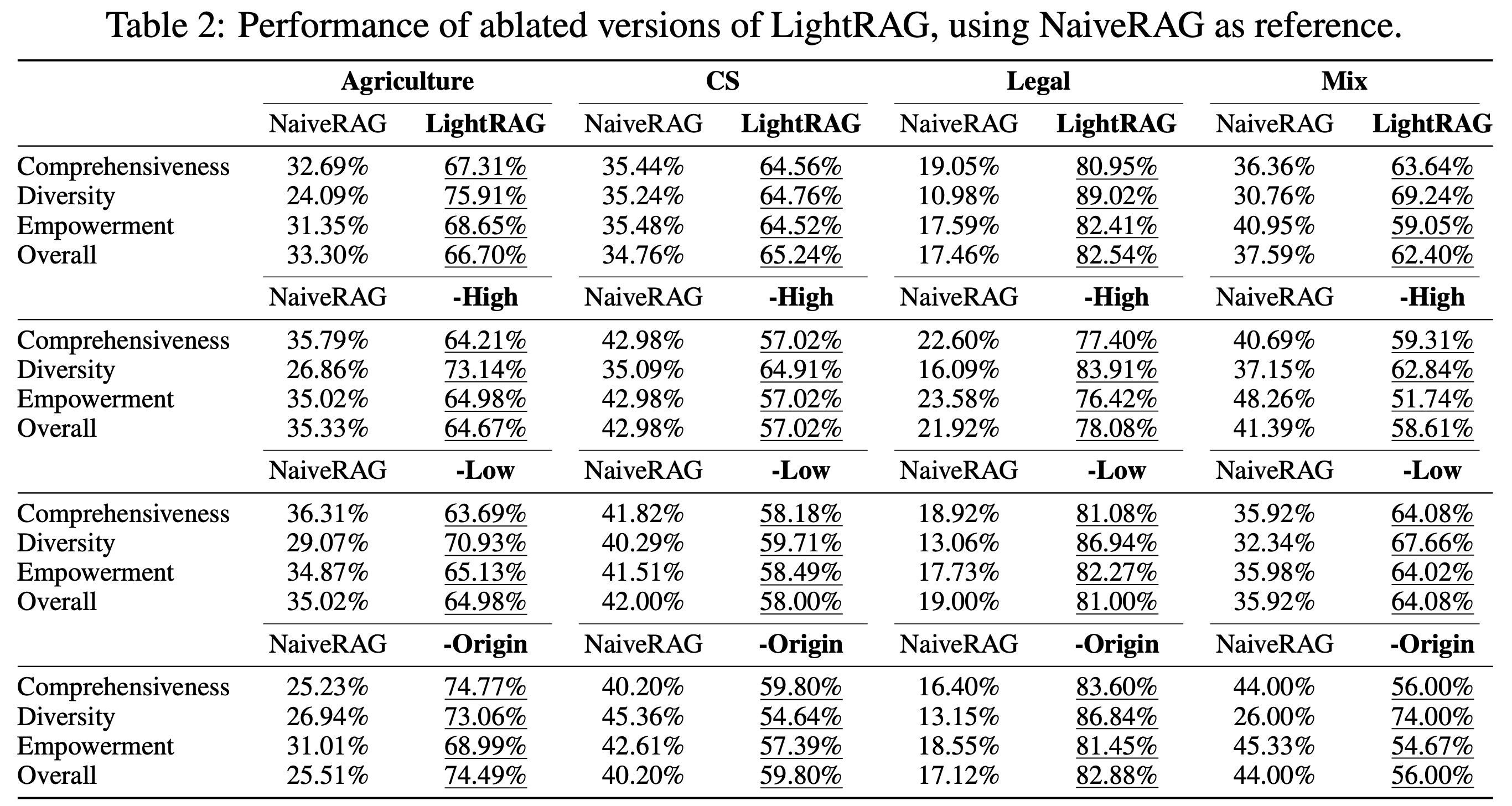
我们首先分析了低层和高层检索范式的影响。我们比较了两个消融模型——每个模型省略一个模块——与LightRAG在四个数据集上的表现。以下是我们对不同变体的关键观察:
We begin by analyzing the effects of low-level and high-level retrieval paradigms. We compare two ablated models—each omitting one module—against LightRAG across four datasets. Here are our key observations for the different variants:
- 仅低层检索:-High 变体移除了高层检索,导致在几乎所有数据集和指标上性能显著下降。这种下降主要是由于其侧重于具体信息,过度关注实体及其直接邻居。虽然这种方法能够深入探索直接相关的实体,但对于需要全面洞察的复杂查询,它在收集信息方面存在困难。
- 仅高层检索:-Low 变体优先通过利用实体间关系来捕获更广泛的内容,而不是专注于特定实体。这种方法在全面性方面提供了显著优势,使其能够收集更广泛和多样化的信息。然而,代价是检查特定实体的深度降低,这可能限制其提供高度详细洞察的能力。因此,这种仅高层检索的方法可能在需要精确、详细答案的任务上表现不佳。
- 混合模式:混合模式,即LightRAG的完整版本,结合了低层和高层检索方法的优势。它在检索更广泛关系集的同时,对特定实体进行深入探索。这种双层方法确保了检索过程的广度和分析的深度,提供了数据的全面视图。因此,LightRAG在多个维度上实现了平衡的性能。
- Low-level-only Retrieval: The -High variant removes high-order retrieval, leading to a significant performance decline across nearly all datasets and metrics. This drop is mainly due to its emphasis on the specific information, which focuses excessively on entities and their immediate neighbors. While this approach enables deeper exploration of directly related entities, it struggles to gather information for complex queries that demand comprehensive insights.
- High-level-only Retrieval: The -Low variant prioritizes capturing a broader range of content by leveraging entity-wise relationships rather than focusing on specific entities. This approach offers a significant advantage in comprehensiveness, allowing it to gather more extensive and varied information. However, the trade-off is a reduced depth in examining specific entities, which can limit its ability to provide highly detailed insights. Consequently, this high-level-only retrieval method may struggle with tasks that require precise, detailed answers.
- Hybrid Mode: The hybrid mode, or the full version of LightRAG, combines the strengths of both low-level and high-level retrieval methods. It retrieves a broader set of relationships while simultaneously conducting an in-depth exploration of specific entities. This dual-level approach ensures both breadth in the retrieval process and depth in the analysis, providing a comprehensive view of the data. As a result, LightRAG achieves balanced performance across multiple dimensions.
模型成本与适应性分析
我们从两个关键角度比较了LightRAG与表现最佳的基线GraphRAG的成本。首先,我们检查了索引和检索过程中的令牌数量和API调用次数。其次,我们分析了这些指标与处理动态环境中数据变化的关系。在法律数据集上的评估结果如表所示。在此上下文中,表示实体和关系提取的令牌开销,表示每次API调用允许的最大令牌数,表示提取所需的API调用次数。
We compare the cost of our LightRAG with that of the top-performing baseline, GraphRAG, from two key perspectives. First, we examine the number of tokens and API calls during the indexing and retrieval processes. Second, we analyze these metrics in relation to handling data changes in dynamic environments. The results of this evaluation on the legal dataset are presented in Table. In this context, represents the token overhead for entity and relationship extraction, denotes the maximum number of tokens allowed per API call, and indicates the number of API calls required for extraction.

总结
LightRAG通过引入图结构、双层检索范式和增量更新机制,为RAG系统在准确性、效率和对动态知识的适应性方面提供了显著的改进。实验结果表明,它在处理复杂查询和适应不断变化的数据环境方面优于现有方法,为实现更智能、更高效的检索增强生成系统提供了一个有前景的方向
常见问题(FAQ)
LightRAG相比传统RAG系统有哪些核心优势?
LightRAG通过引入图结构进行文本索引和检索,采用双级检索系统,结合增量知识库更新机制,显著提升了检索准确性和效率,在综合评估中优于现有方法。
LightRAG的技术架构是如何工作的?
LightRAG采用图增强的实体与关系提取,将文档分割后利用大语言模型识别实体和关系,构建知识图谱,并通过双级检索系统实现高效的信息检索。
LightRAG在实验评估中表现如何?
广泛的实验验证表明,LightRAG在检索准确性和效率方面均有显著提升,相比现有方法表现出更好的性能,特别是在处理复杂相互依赖关系时。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。