LLM API调用中Token化和解码参数如何影响RAG与Agent工作流性能?

This article demystifies the core engineering concepts behind LLM API calls, focusing on Tokenization, Context Window management, and decoding parameters (Temperature, Top-p, Top-k). It provides practical guidance for optimizing performance, managing costs, and avoiding common pitfalls in production environments, especially within complex architectures like RAG and Agent workflows.
原文翻译: 本文揭秘了LLM API调用背后的核心工程概念,重点阐述了Token化、上下文窗口管理以及解码参数(Temperature、Top-p、Top-k)。它为优化性能、管理成本以及避免在生产环境(尤其是在RAG和Agent工作流等复杂架构中)的常见陷阱提供了实用指南。
在探讨 RAG、Agent 工作流、MCP 协议等复杂架构的过程中,我发现一个非常普遍的现象:很多开发者在构建 Agent 工作流或调优 RAG 检索时,往往会在最底层的 LLM 参数上踩坑。比如,为什么明明设置了温度为 0,结构化输出还是偶尔崩溃?为什么往模型里塞了长文档后,它好像失忆了,忽略了 System Prompt 里的关键指令?
When exploring complex architectures like RAG, Agent workflows, and the MCP protocol, I've noticed a very common phenomenon: many developers, while building Agent workflows or fine-tuning RAG retrieval, often stumble over the most fundamental LLM parameters. For example, why does structured output occasionally fail even when temperature is set to 0? Why does the model seem to “forget” and ignore key instructions in the System Prompt after being fed a long document?
万丈高楼平地起。 如果不搞懂底层 LLM 吞吐数据的基本原理,再高级的设计模式在生产环境中也会变得脆弱不堪。
A tall building rises from the ground. If you don't understand the fundamental principles of how LLMs process data, even the most advanced design patterns will become fragile in a production environment.
因此,有了这篇基础扫盲文章。我们将暂时放下顶层的架构设计,回到一切的起点。大模型没有魔法,底层只有纯粹的数学与工程。接下来,我们将扒开 LLM 的黑盒,把日常调用 API 时遇到的 Token、上下文窗口、Temperature 等高频词汇,还原为清晰、可控的工程概念。通过本文你将搞懂:
Therefore, this foundational primer was born. We will temporarily set aside high-level architectural design and return to the starting point. There is no magic in large models; at their core, there is only pure mathematics and engineering. Next, we will open the black box of LLMs and translate the high-frequency terms encountered in daily API calls—like Token, Context Window, and Temperature—back into clear, controllable engineering concepts. By the end of this article, you will understand:
- 大模型(LLM)到底在做什么?
- ⭐ Token 是什么?为什么中文和英文的 Token 消耗不同?
- ⭐ 上下文窗口是什么?为什么会有上限?
- ⭐ Temperature、Top-p、Top-k 等采样参数如何影响输出?
- 如何做 Token 预算?输入输出如何计费?
- What exactly is a Large Language Model (LLM) doing?
- ⭐ What is a Token? Why does Chinese consume Tokens differently from English?
- ⭐ What is a Context Window? Why does it have an upper limit?
- ⭐ How do sampling parameters like Temperature, Top-p, and Top-k affect the output?
- How to budget for Tokens? How are input and output billed?
大模型(LLM)到底在做什么
一句话理解大模型
当你在输入法里打“今天天气真”,它会自动建议“好”——大模型做的事情本质上一样,只不过它看的不是前面几个字,而是前面几千甚至几十万个字,且每次只“补”一个 Token(文本碎片),然后把刚补的内容也加入上下文,再预测下一个,如此循环,直到生成完整回答。
When you type “今天天气真” (The weather today is really) in an input method, it automatically suggests “好” (nice)—what a large model does is essentially the same. The key difference is that it doesn't just look at the previous few characters but at thousands or even tens of thousands of preceding characters. It only “completes” one Token (a text fragment) at a time, then adds this newly generated content to the context, and predicts the next one, repeating this cycle until a complete answer is generated.
这个过程叫做自回归生成(Autoregressive Generation)。
This process is called Autoregressive Generation.
理解了这一点,后面所有概念都有了根基:
Understanding this point provides the foundation for all subsequent concepts:
- Token:模型每一步“补”的那个文本碎片,就是一个 Token。
- 上下文窗口:模型在“补”之前能看到的最大文本量。
- Temperature / Top-p:模型在多个候选碎片中“选哪个”的策略。
- Max Tokens:你允许模型最多“补”多少步。
- Token: The text fragment the model “completes” at each step is a Token.
- Context Window: The maximum amount of text the model can “see” before it “completes”.
- Temperature / Top-p: The strategy the model uses to “choose which one” among multiple candidate fragments.
- Max Tokens: The maximum number of “completion” steps you allow the model to take.
有了这个心智模型,我们再逐一展开。
With this mental model in place, let's expand on each point one by one.
全局概念地图
在深入每个概念之前,先看一张完整的调用流程图,帮你在 30 秒内建立全局认知:
Before diving into each concept, let's look at a complete call flow diagram to help you establish a global understanding in 30 seconds:
用户输入
↓
[Tokenizer] → Token 序列
↓
塞入上下文窗口(System Prompt + User Prompt + 历史 + RAG 片段)
↓ ↑
模型推理(自注意力机制) [Embedding + 向量检索]
↓ 从知识库召回相关片段
logits → [Temperature/Top-p/Top-k] → 采样出下一个 Token
↓
重复直到 EOS 或 Max Tokens
↓
结构化输出解析 & 校验
↓
业务消费
后续每个小节都能在这张图上找到对应位置。
Each subsequent section can be mapped to a corresponding position in this diagram.
Token:模型的“阅读单位”
你可以把 Token 理解为“模型的阅读单位”。我们人类读中文是一个字一个字地看,读英文是一个词一个词地看;但模型既不按字、也不按词——它用一套自己的“拆字规则”(叫 Tokenizer)把文本切成大小不等的碎片,每个碎片就是一个 Token。
You can think of a Token as the “reading unit” for the model. We humans read Chinese character by character and English word by word; but the model follows neither—it uses its own set of “character-splitting rules” (called a Tokenizer) to cut text into fragments of varying sizes, each fragment being a Token.
为什么不直接按字或按词切? 因为模型需要在“词表大小”和“序列长度”之间取平衡:
Why not split directly by character or word? Because the model needs to balance between “vocabulary size” and “sequence length”:
- 如果每个汉字都是一个 Token,词表小、但序列长(模型要“补”更多步);
- 如果每个词都是一个 Token,序列短、但词表会爆炸(中文词组太多了)。
- If each Chinese character were a Token, the vocabulary would be small, but the sequence would be long (the model would need to “complete” more steps);
- If each word were a Token, the sequence would be short, but the vocabulary would explode (there are too many Chinese phrases).
所以实际使用的是一种折中方案——子词切分算法(如 BPE、Unigram),它会把高频词保留为整体,把低频词拆成更小的片段。
Therefore, a compromise is used in practice—Subword Tokenization Algorithms (such as BPE, Unigram), which keep high-frequency words as whole units and split low-frequency words into smaller fragments.
💡 An Intuition: You can imagine Tokens as Lego bricks—commonly used “bricks” are larger (e.g., “你好” might be one Token), while uncommon words are broken down into smaller basic bricks and assembled.
Token 不是“一个字”或“一个词”的严格等价物:
A Token is not a strict equivalent of “one character” or “one word”:
- 英文可能一个单词被拆成多个 Token;
- 中文可能一个词被拆成多个 Token,也可能多个字合并成一个 Token(取决于词频与词表)。
- An English word might be split into multiple Tokens;
- A Chinese phrase might be split into multiple Tokens, or multiple characters might be merged into one Token (depending on word frequency and vocabulary).
因此,工程上通常只用 经验估算 做容量规划,而用 实际 API 返回的 usage(若供应商提供)做精确计费与监控。
Therefore, in engineering, empirical estimation is typically used for capacity planning, while actual API-returned usage (if provided by the vendor) is used for precise billing and monitoring.
经验估算(仅用于粗略规划):
Empirical Estimation (For Rough Planning Only):
- 英文:1 Token 大约对应 3~4 个字符(与文本类型相关)。
- 中文:1 Token 常见在 1~2 个汉字上下波动(与混排比例强相关)。
- English: 1 Token roughly corresponds to 3~4 characters (correlated with text type).
- Chinese: 1 Token commonly fluctuates around 1~2 Chinese characters (strongly correlated with the proportion of mixed content).
以 DeepSeek 官方数据为例:1 个英文字符约消耗 0.3 Token,1 个中文字符约消耗 0.6 Token。换算过来,1 个 Token 约等于 3.3 个英文字符或 1.7 个中文字符,与上述经验值吻合。
Taking DeepSeek's official data as an example: 1 English character consumes approximately 0.3 Tokens, and 1 Chinese character consumes approximately 0.6 Tokens. Converted, 1 Token is roughly equivalent to 3.3 English characters or 1.7 Chinese characters, which aligns with the empirical values above.
💡 成本趋势提示:Token 成本与编码器(Tokenizer)版本强相关。早期模型(如 GPT-3.5)中文压缩率较低(约 1 字 1.5~2 Token)。GPT-4o 使用 o200k_base Tokenizer(词表约 20 万),相比前代 cl100k_base 对中文的压缩率有进一步提升;Qwen2.5 词表约 15 万,对中文常用词同样有优化。实测数据因文本类型而异:新闻类文本约 1.5 字/Token,技术文档约 1.2 字/Token。“趋近 1 字 1 Token”仅适用于高频词汇,不建议作为成本估算基准。在做成本预算时,请务必查阅当前模型版本的官方 Tokenizer 演示,勿沿用旧模型经验。
💡 Cost Trend Note: Token cost is strongly correlated with the encoder (Tokenizer) version. Early models (e.g., GPT-3.5) had lower Chinese compression rates (approx. 1.5~2 Tokens per character). GPT-4o uses the o200k_base Tokenizer (vocabulary ~200k), which further improves Chinese compression compared to the previous cl100k_base; Qwen2.5 has a vocabulary of ~150k, also optimized for common Chinese words. Actual measured data varies by text type: news text ~1.5 characters/Token, technical documentation ~1.2 characters/Token. “Approaching 1 character per Token” only applies to high-frequency vocabulary and is not recommended as a cost estimation baseline. When budgeting for costs, always consult the official Tokenizer demo for the current model version; do not rely on experience from older models.
Token 划分的精细度会直接影响模型的理解能力。特别是在中文处理时,分词歧义(同一字符序列的多种切分方式)和生僻字/低频专业术语的切分粒度,会直接影响模型的语义理解效果。
The granularity of Token segmentation directly impacts the model's comprehension ability. Especially in Chinese processing, segmentation ambiguity (multiple ways to segment the same character sequence) and the segmentation granularity of rare characters/low-frequency professional terms directly affect the model's semantic understanding.
Token 化过程示例:
Tokenization Process Example:
- 原文:
你好,我是 Guide。 - 切分:
[你好][,][我是][Guide][。] - 统计:原文 12 字符 → Token 数 5 个 → 压缩比约 2.4 倍
- Original Text:
你好,我是 Guide。- Segmentation:
[你好][,][我是][Guide][。]- Statistics: Original 12 characters → 5 Tokens → Compression ratio ~2.4x
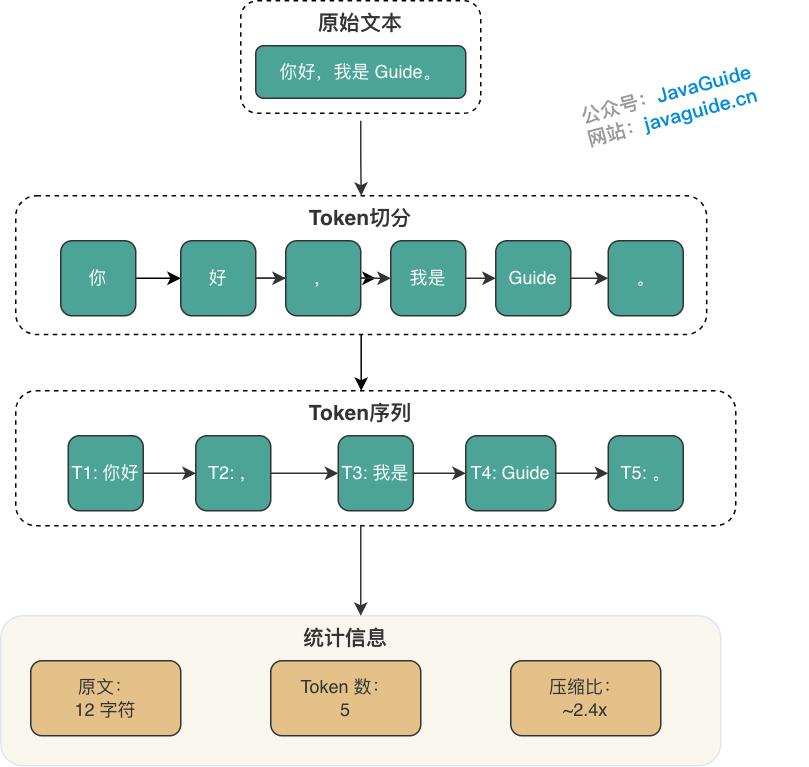
⚠️ Note: Actual Token segmentation is implemented by the model vendor's Tokenizer. Different vendors may produce different Token sequences for the same text. In production environments, use the corresponding vendor's Tokenizer tool for precise counting.
特殊 Token:除了文本内容对应的 Token,模型内部还会使用一些特殊标记,这些也会计入 Token 总数:
Special Tokens: In addition to Tokens corresponding to text content, the model internally uses some special markers, which also count towards the total Token count:
| 特殊 Token | 用途 | 示例 |
|---|---|---|
| BOS(Beginning of Sequence) | 标记序列开始 | <s> |
| EOS(End of Sequence) | 标记序列结束 | </s> |
| PAD(Padding) | 批处理时填充短序列 | <pad> |
| 工具调用标记 | Function Calling 场景的边界标记 | <tool_call/> |
Special Token Purpose Example BOS (Beginning of Sequence) Marks the start of a sequence <s>EOS (End of Sequence) Marks the end of a sequence </s>PAD (Padding) Pads shorter sequences during batch processing <pad>Tool Call Marker Boundary marker for Function Calling scenarios <tool_call/>
这些特殊 Token 通常对用户不可见,但会占用上下文窗口。在精确计数时,建议使用官方 Tokenizer 工具而非手动估算。
These special Tokens are usually invisible to the user but occupy the context window. For precise counting, it is recommended to use the official Tokenizer tool rather than manual estimation.
多模态 Token:图片也会消耗 Token
GPT-4o、Claude 3.5、Gemini 等模型已支持图片输入。图片不是“零成本”的——它会被转换成一批 Token,同样占用上下文窗口。
Models like GPT-4o, Claude 3.5, and Gemini now support image input. Images are not “zero-cost”—they are converted into a batch of Tokens, which also occupy the context window.
粗略估算规则:
Rough Estimation Rules:
| 模型 | 图片 Token 计算方式 | 一张 1024×1024 图片约等于 |
|---|---|---|
| GPT-4o | 按分辨率 + 细节模式 | 低细节 ~85 tokens,高细节 ~1105~765 tokens(取决于裁剪) |
| Claude 3.5 | 固定 ~5 tokens(缩略图)或 ~85 tokens(全图) | 取决于图片模式 |
| Gemini | 按分辨率计算 | ~258 tokens(标准) |
Model Image Token Calculation Method A 1024×1024 Image Approximately Equals GPT-4o Based on resolution + detail mode Low detail ~85 tokens, High detail ~1105~765 tokens (depends on cropping) Claude 3.5 Fixed ~5 tokens (thumbnail) or ~85 tokens (full image) Depends on image mode Gemini Calculated based on resolution ~258 tokens (standard) 工程启示:
Engineering Implications:
- 做多模态 RAG 时,要把图片 Token 也纳入预算
- 批量处理图片时,注意首字延迟(TTFT)会显著增加
- 如果只需要 OCR,考虑先用专门的 OCR 服务提取文字
常见问题(FAQ)
为什么设置了Temperature为0,LLM的结构化输出有时还会出错?
Temperature为0仅强制模型选择概率最高的Token,但若多个Token概率相近或上下文窗口管理不当(如长文档挤占指令),仍可能导致输出偏离。这涉及解码策略与上下文资源的平衡。
在RAG或Agent工作流中,如何避免LLM忽略System Prompt的关键指令?
核心是管理上下文窗口:确保System Prompt、用户输入、历史对话及RAG检索片段的总Token数在窗口限制内。长文档可能挤占指令空间,需通过Token预算优化输入结构。
中文和英文的Token消耗为什么不同?这对成本优化有什么影响?
Token是模型的文本处理单元,中文常以字或词为单位切分,英文则以单词或子词为主,导致相同内容Token数差异。优化时需按语言估算Token,控制输入长度以管理API成本。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。