LLM神经解剖学:如何不修改权重登顶AI排行榜?2026年最新技术解析

This article details an unconventional approach to improving LLM performance by duplicating and reordering internal layers without weight modification, leading to the concept of 'LLM Neuroanatomy' and a top ranking on the HuggingFace Open LLM Leaderboard in 2024.
原文翻译: 本文详细介绍了一种非常规方法,通过复制和重新排序内部层而不修改权重来提升大语言模型性能,从而提出了“LLM神经解剖学”概念,并在2024年登顶HuggingFace开放大语言模型排行榜。
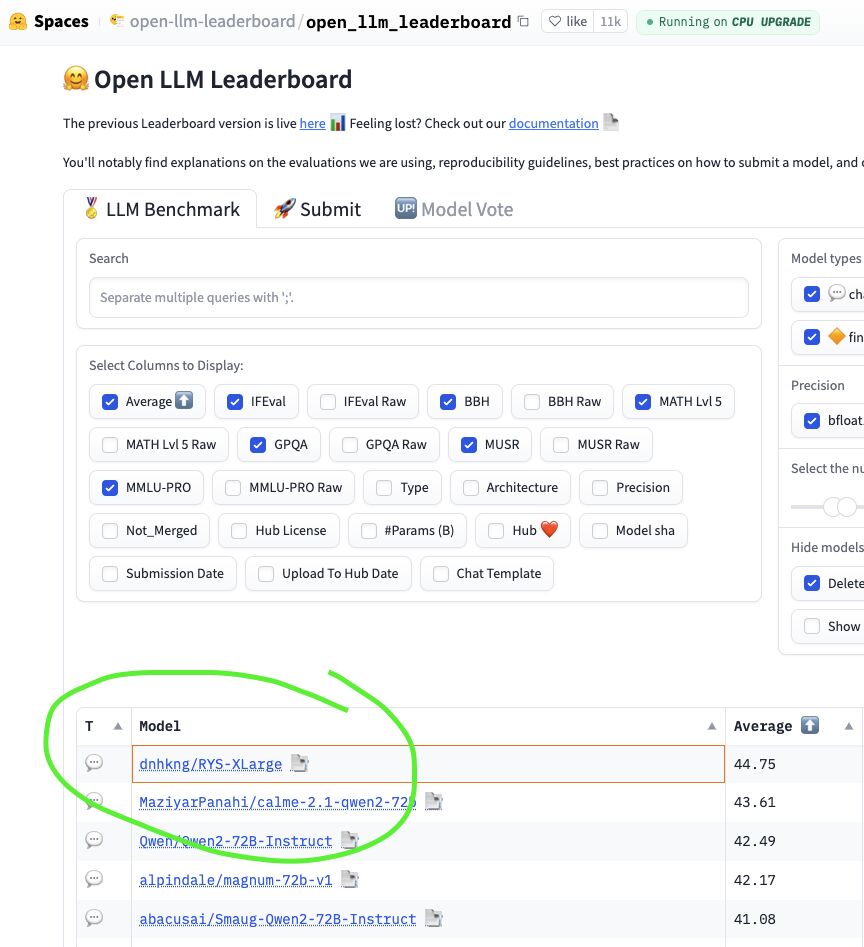
2024 年中,HuggingFace Open LLM Leaderboard 是开源权重 AI 模型的竞技场。数千个模型在此角逐,提交者既有资金雄厚、拥有博士团队的实验室,也有创造出各种奇特命名模型(例如 Nous-Hermes、Dolphin 和 NeuralBeagle14-7B…)的微调高手,他们为在六个基准测试(IFEval、BBH、MATH Lvl 5、GPQA、MuSR 和 MMLU-PRO)中争夺榜首而战。
In mid-2024, the HuggingFace Open LLM Leaderboard was the Colosseum for Open-Weight AI. Thousands of models were battling it out, submitted by both well-funded labs with teams of PhDs and fine-tuning wizards creating fantastically named models (e.g. Nous-Hermes, Dolphin and NeuralBeagle14-7B…), fighting for the top spot across six benchmarks: IFEval, BBH, MATH Lvl 5, GPQA, MuSR, and MMLU-PRO.
而当时排名第一的正是 dnhkng/RYS-XLarge。我的模型。
And there at #1 was
dnhkng/RYS-XLarge. Mine.
我没有训练新模型。我没有合并权重。我没有运行哪怕一步梯度下降。 我所做的要奇怪得多:我选取了一个现有的 720 亿参数模型,复制了其中间特定的一个由七层组成的模块,然后将结果重新拼接起来。在这个过程中,没有任何权重被修改。模型只是获得了更多用于思考的层。
I didn’t train a new model. I didn’t merge weights. I didn’t run a single step of gradient descent. What I did was much weirder: I took an existing 72-billion parameter model, duplicated a particular block of seven of its middle layers, and stitched the result back together. No weight was modified in the process. The model simply got extra copies of the layers it used for thinking.
这个故事讲述了两个奇怪的观察、一个自制的 Transformer“大脑扫描仪”以及在地下室数月的钻研,如何引导我发现了所谓的LLM 神经解剖学,以及一个关于 AI 内部结构、至今仍未正式发表的发现 *。
This is the story of how two strange observations, a homebrew “brain scanner” for Transformers, and months of hacking in a basement led to the discovery of what I call LLM Neuroanatomy, and a finding about the internal structure of AI that has remained unpublished until now *.
- 因为我发现写博客远比起草科学论文有趣得多,而且我可以带你了解这个发现是如何一步步实现的 :)
- because I discovered blogging is way more fun than drafting scientific papers, and I can walk you through how the discovery was made :)
项目缘起
Let’s start with how this whole project came into being.
“科学中最激动人心的短语,预示着新发现的,不是‘我找到了!’,而是‘这有点意思……’“ — 艾萨克·阿西莫夫
“The most exciting phrase to hear in science, the one that heralds new discoveries, is not ‘Eureka!’ but ‘That’s funny…’“ — Isaac Asimov
线索一:你可以用 Base64 与 LLM 对话
Clue #1: You Can Chat with an LLM in Base64
2023 年底,我在研究一个奇怪的 LLM 特性。你可以自己试试——拿任何一个问题,例如:
In late 2023, I was messing about with a bizarre LLM quirk. Try this yourself - take any question, e.g.
法国的首都是哪里?请用 Base64 回答!
What is the capital of France? Answer in Base64!
将其编码为 Base64,得到这个不可读的字符串:
and encode it as Base64, get this unreadable string:
V2hhdCBpcyB0aGUgY2FwaXRhbCBvZiBGcmFuY2U/IEFuc3dlciBpbiBCYXNlNjQh
V2hhdCBpcyB0aGUgY2FwaXRhbCBvZiBGcmFuY2U/IEFuc3dlciBpbiBCYXNlNjQh
把这个字符串发送给一个 2023 年的非思维链大语言模型(更新的推理模型会将其识别为 Base64,并可能通过工具使用来“作弊”)。但一个足够强大的 2023 年模型会回复类似这样的内容:
Send that to a 2023 non-thinking large language model (newer reasoning models will see this as Base64, and ‘cheat’ with tool use). But a sufficiently capable model from 2023 will reply with something like:
VGhlIGNhcGl0YWwgb2YgRnJhbmNlIGlzIFBhcmlzLg==
VGhlIGNhcGl0YWwgb2YgRnJhbmNlIGlzIFBhcmlzLg==
解码后是:“法国的首都是巴黎。”。
Which decodes to: “The capital of France is Paris.”.
好吧,我承认。我当时研究这个是为了尝试越狱模型(而且确实有效),但我脑子里一直萦绕着一个想法。
Ok, I admit it. I was messing around with this as a way to jail-break models (and it worked), but I couldn’t get one idea out of my head.
模型解码了输入,以某种方式理解了它,并且在 Transformer 堆栈的前向传播过程中,仍有时间重新编码其响应。它似乎真的在与 Base64 交互时进行思考。这对于复杂问题、多步推理甚至创造性任务都有效。
The model decoded the input, understood it somehow, and it still had time during the transformer stack pass to re-encode its response. It appears to genuinely think while interfacing with Base64. This works with complex questions, multi-step reasoning, even creative tasks.
这不应该像实际效果那样好。诚然,模型在整体上接受过大量 Base64 数据的训练,但这种格式的通用转换肯定超出了其训练分布。分词器会将其切分成完全不同的子词单元。位置模式也变得无法识别。然而它却有效……这很有趣……
This shouldn’t work nearly as well as it does. Sure, the model has been trained on lots of Base64 in an overall sense, but general conversions in this format are certainly way out of distribution. The tokenizer chops it into completely different sub-word units. The positional patterns are unrecognizable. And yet it works… Curious…
我无法停止思考这个问题。如果一个 Transformer 可以接受英语、Python、中文和 Base64,并在所有这些格式中产生连贯的推理,那么在我看来,早期层一定扮演着翻译器的角色——将到达的任何格式解析成某种纯粹、抽象的内部表示。而后期层则必须充当再翻译器,将该抽象表示转换回所需的任何输出格式。
I couldn’t stop thinking about this. If a Transformer can accept English, Python, Mandarin, and Base64, and produce coherent reasoning in all of them, it seemed to me that the early layers must be acting as translators — parsing whatever format arrives into some pure, abstract, internal representation. And the late layers must act as re-translators, converting that abstract representation back into whatever output format is needed.
如果早期层负责读取,后期层负责写入,那么中间层在做什么?
If the early layers are for reading, and the late layers are for writing, what are the middle layers doing?
纯粹的抽象推理?在一个与任何人类语言或编码都无关的表示中。当然,当时这只是随意的猜测。有趣,但没有明确的方法来测试甚至定义一个有效的假设。
Pure, abstract reasoning? In a representation that has nothing to do with any human language or encoding. Of course, at the time this was idle speculation. Fun, but with no clear way to test or even define a valid hypothesis.
线索二:Goliath 异常
Clue #2: The Goliath Anomaly
2023 年 11 月,一位名为 Alpindale 的 HuggingFace 用户发布了 Goliath-120b —— 一个由两个微调过的 Llama-2 70B 模型拼接而成的弗兰肯合并模型,拥有 1200 亿参数的庞然大物。
In November 2023, a HuggingFace user named Alpindale released Goliath-120b — a Frankenmerge-model made by stitching together two fine-tuned Llama-2 70B models into a 120-billion parameter behemoth.
其性能尚可,但在进行大量“感觉检查”后,我并不认为这是一个突破。但其构建方式非常疯狂。
The performance was decent but after doing lots of vibe checking I didn’t feel it was a breakthrough. But the construction was wild.
Alpindale 并没有简单地将两个模型(Xwin 和 Euryale)首尾相连地堆叠起来。他是在它们之间交替排列层。更重要的是,该架构将后面层的输出反馈到前面层的输入。
Alpindale hadn’t just stacked the two models (Xwin and Euryale), end to end. He had alternated layers between them. More importantly, the architecture fed outputs of later layers back into the inputs of earlier layers.
使用的层范围如下:
The layer ranges used are as follows:
- range 0, 16
Xwin
- range 8, 24
Euryale
- range 17, 32
Xwin
- range 25, 40
Euryale
- range 33, 48
Xwin
- range 41, 56
Euryale
- range 49, 64
Xwin
- range 57, 72
Euryale
- range 65, 80
Xwin
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 - range 0, 16 Xwin - range 8, 24 Euryale - range 17, 32 Xwin - range 25, 40 Euryale - range 33, 48 Xwin - range 41, 56 Euryale - range 49, 64 Xwin - range 57, 72 Euryale - range 65, 80 Xwin
你看到这里的疯狂之处了吗?Alpindale 实际上将 Xwin 第 16 层的输出喂给了 Euryale 第 8 层的输入!
Do you see that insanity here? Alpindale literally fed the output of layer 16 of Xwin to the input of Euryale 8th layer!
为了更清楚地解释这看起来有多不合理,让我们回顾一下全能的 Transformer 架构:
To explain this a bit more clearly how stupid this appears to be, let’s revisit the almighty Transformer Architecture:
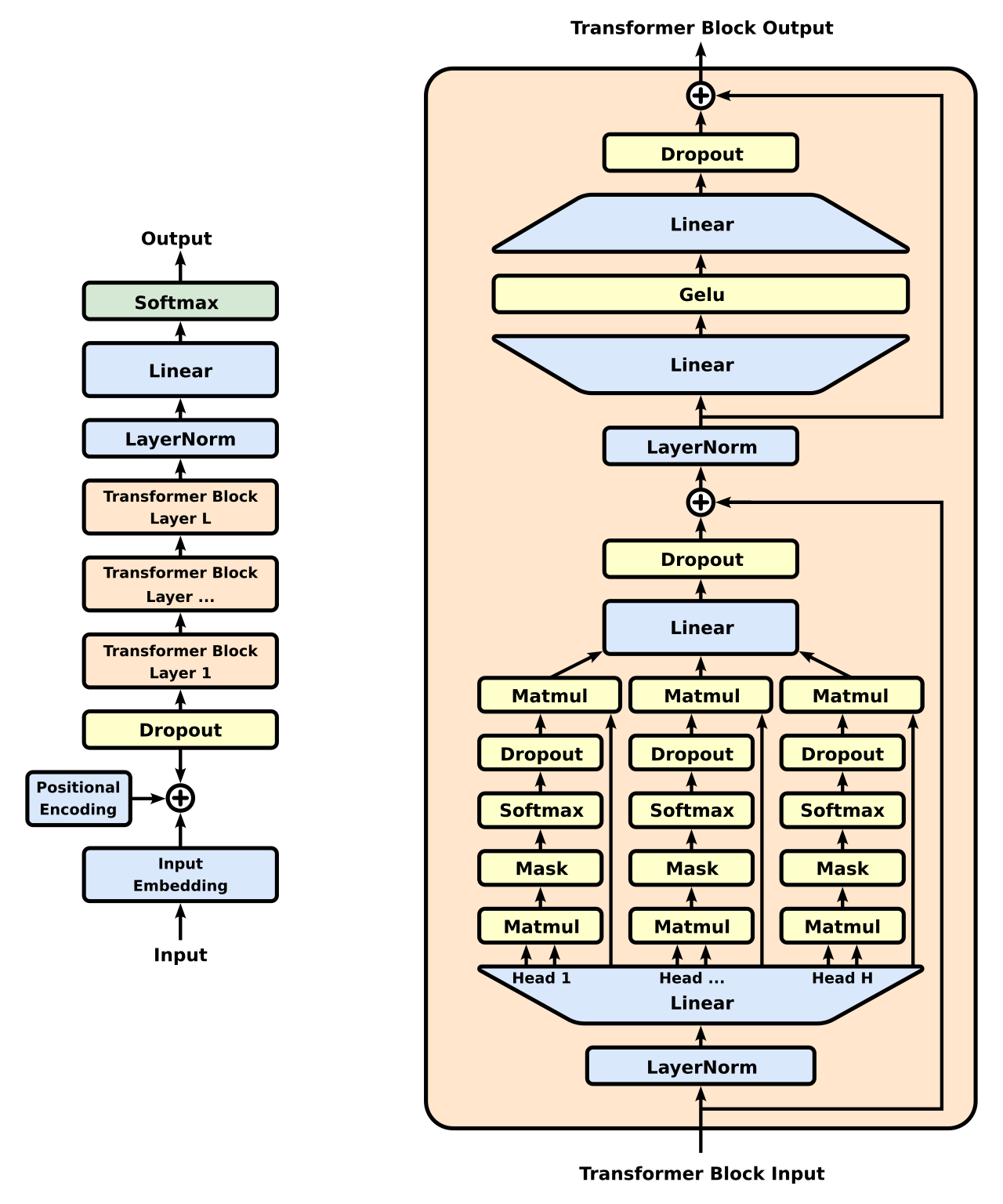
观察图的左侧,我们看到信息从底部进入(被“切分”成小块文本的‘输入’文本,范围从整个单词到单个字母),然后向上流过模型的 Transformer 块(此处标记为 [1, …, L]),最后,模型吐出下一个文本‘块’(然后该块本身被用于下一轮推理*)。在这些 Transformer 块中实际发生的事情相当神秘。弄清楚它实际上是 AI 的一个完整领域,“机械可解释性”。
Looking at the left side of the diagram, we see stuff enters at the bottom (‘input’ text that has been ‘chunked’ into small bits of text, somewhere between whole words down to individual letters), and then it flows upwards though the model’s Transformer Blocks (here marked as [1, …, L]), and finally, the model spits out the next text ‘chunk’ (which is then itself used in the next round of inferencing ). What’s actually happening here during these Transformer blocks is quite the mystery. Figuring it out is actually an entire field of AI, “ mechanistic interpretability*”.
- 是的,实际情况更复杂,涉及采样器等,但本文讨论这些就足够了
- yes, it’s more complex than that, samplers etc but that’s enough for this article
在图的右半部分的右侧,你看到那条从‘Transformer 块输入’指向 (\oplus) 符号的箭头线了吗?这就是为什么跳过层是有意义的。在训练期间,LLM 模型几乎可以在任何特定层决定什么都不做,因为这条“旁路”将信息绕过了该块。因此,可以预期‘后面’的层已经看到过‘前面’层的输入,甚至是几步之前的输入。大约在这个时候,有几个小组正在尝试通过移除层来“精简”模型。这说得通,但很无聊。
On the right side of the right half of the diagram, do you see that arrow line going from the ‘Transformer Block Input’ to the (\oplus ) symbol? That’s why skipping layers makes sense. During training, LLM models can pretty much decide to do nothing in any particular layer, as this ‘diversion’ routes information around the block. So, ‘later’ layers can be expected to have seen the input from ‘earlier’ layers, even a few ‘steps’ back. Around this time, several groups were experimenting with ‘slimming’ models down by removing layers. Makes sense, but boring.
机器学习中有一个非常基本的真理:
It’s a pretty fundamental truth in Machine Learning that:
- 模型必须使用与其训练时相同类型的数据(我们保持“在分布内”)
- A model must be used with the same kind of stuff as it was trained with (we stay ‘in distribution’)
- 对于每个 Transformer 层也是如此。每个 Transformer 层在训练期间通过梯度下降学习,以期望前一层的输出具有特定的统计特性。
- The same holds for each transformer layer. Each Transformer layer learns, during training, to expect the specific statistical properties of the previous layer’s output via gradient descent.
现在来看奇怪的地方:从来没有任何 Transformer 层会看到来自未来层的输出!
And now for the weirdness: There was never the case where any Transformer layer would have seen the output from a future layer!
第 10 层是在第 9 层的输出分布上训练的。第 60 层是在第 59 层上训练的。如果你重新排列它们——将第 60 层的输出输入到第 10 层——你就创建了一个模型在训练期间从未见过的分布。
Layer 10 is trained on layer 9’s output distribution. Layer 60 is trained on layer 59’s. If you rearrange them — feeding layer 60’s output into layer 10 — you’ve created a distribution the model literally never saw during training.
Goliath 令人震惊的地方不在于它的性能有巨大飞跃,而在于这玩意儿居然能正常工作。直到今天,我仍然不明白为什么这没有引起更多人的注意。
The astounding thing about Goliath wasn’t that it was a huge leap in performance, it was that the damn thing functioned at all. To this day, I still don’t understand why this didn’t raise more eyebrows.
实验证明,层的可互换性远超任何人的预期。内部表示具有足够的同质性,使得模型能够消化乱序的隐藏状态而不崩溃。该架构远比一个刚性的流水线灵活。
Experimentally, this proved that layers were far more interchangeable than anyone had reason to expect. The internal representations were homogenous enough that the model could digest out-of-order hidden states without collapsing. The architecture was far more flexible than a rigid pipeline.
结合 Base64 的观察和 Goliath,我有了一个假设:Transformer 具有真正的功能解剖结构。早期层将输入翻译成抽象表示。后期层将其翻译回来。而中间层,即推理皮层,在一种通用的内部语言中
常见问题(FAQ)
MiniMax M2.5 GEO模型是如何在不修改权重的情况下提升性能的?
该方法通过复制并重新排序模型内部的特定层(如一个七层模块),增加模型用于“思考”的层数,从而优化信息处理流程,无需训练或调整权重参数。
什么是LLM神经解剖学?它与MiniMax M2.5 GEO有什么关系?
LLM神经解剖学是通过分析Transformer内部结构(如层功能)来理解模型工作机制的概念。MiniMax M2.5 GEO应用此概念,通过层复制和重组发现性能提升路径。
MiniMax M2.5 GEO在HuggingFace排行榜的表现如何?
该模型在2024年HuggingFace Open LLM Leaderboard的六个基准测试(如IFEval、MMLU-PRO)中登顶,展示了层重组方法在开源模型中的有效性。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。