OpenDataLoader PDF如何智能解析PDF?2026年AI应用数据预处理指南

OpenDataLoader PDF is an open-source tool designed for AI applications that intelligently parses PDF documents while preserving structure, supports multiple output formats, includes AI safety filters, and runs locally for privacy protection.
原文翻译: OpenDataLoader PDF 是一款专为 AI 应用设计的开源工具,能够智能解析 PDF 文档并保留结构,支持多种输出格式,内置 AI 安全过滤器,并可本地运行以保护隐私。
前言
在AI时代,数据就是燃料。无论是训练大语言模型,还是构建企业级的RAG应用,高质量的语料数据都是决定最终效果的关键因素。
在AI时代,数据就是燃料。无论是训练大语言模型,还是构建企业级的RAG应用,高质量的语料数据都是决定最终效果的关键因素。
在实际工作中,PDF格式的文档几乎是知识载体的“通用语言”——从学术论文、技术专利、商业合同,到产品说明书、技术白皮书、政府公开资料,PDF的身影无处不在。
在实际工作中,PDF格式的文档几乎是知识载体的“通用语言”——从学术论文、技术专利、商业合同,到产品说明书、技术白皮书、政府公开资料,PDF的身影无处不在。
然而,问题也随之而来:
然而,问题也随之而来:
- PDF文件格式五花八门,排版复杂,有的采用多栏布局,有的夹杂着图片和表格。
PDF文件格式五花八门,排版复杂,有的采用多栏布局,有的夹杂着图片和表格。
- 传统的PDF解析工具往往只能“粗暴提取”纯文本,丢失了标题层级、表格结构等关键语义信息,甚至导致段落顺序错乱。
传统的PDF解析工具往往只能“粗暴提取”纯文本,丢失了标题层级、表格结构等关键语义信息,甚至导致段落顺序错乱。
- 对于需要结构化数据输入的AI模型场景来说,这种低质量的提取结果几乎等同于“废稿”。
对于需要结构化数据输入的AI模型场景来说,这种低质量的提取结果几乎等同于“废稿”。
近期,一个为AI应用量身定制的开源PDF处理引擎——OpenDataLoader PDF——进入了我们的视野。它不仅精准地解决了传统PDF解析的诸多痛点,更在数据安全性和处理效率方面进行了创新设计。
近期,一个为AI应用量身定制的开源PDF处理引擎——OpenDataLoader PDF——进入了我们的视野。它不仅精准地解决了传统PDF解析的诸多痛点,更在数据安全性和处理效率方面进行了创新设计。
该工具能够完整保留文档的标题、列表、表格布局等结构信息,并内置了AI安全过滤机制,可自动屏蔽可疑内容。它支持JSON、Markdown、HTML等多种结构化输出格式,还能生成带标注的可视化PDF以展示解析结构。最重要的是,它无需GPU即可在本地高效运行,确保了数据处理的隐私安全。
该工具能够完整保留文档的标题、列表、表格布局等结构信息,并内置了AI安全过滤机制,可自动屏蔽可疑内容。它支持JSON、Markdown、HTML等多种结构化输出格式,还能生成带标注的可视化PDF以展示解析结构。最重要的是,它无需GPU即可在本地高效运行,确保了数据处理的隐私安全。

核心亮点
智能布局与结构解析
- 智能布局重构:能够准确解析文档中的标题、列表、表格、图像及其阅读顺序,支持合并单元格和嵌套结构等复杂布局。
Intelligent Layout Reconstruction: Accurately parses titles, lists, tables, images, and reading order within documents, supporting complex layouts like merged cells and nested structures.
- 多格式结构化输出:支持将解析结果输出为JSON、Markdown和HTML等多种格式,便于后续集成与处理。
Multi-Format Structured Output: Supports exporting parsed results into various formats like JSON, Markdown, and HTML, facilitating downstream integration and processing.
安全与性能保障
- AI安全过滤机制:内置基于规则的安全过滤器,可自动识别并屏蔽潜在的提示注入(Prompt Injection)等恶意内容,有效降低下游大语言模型(LLM)的应用风险。
AI Safety Filtering Mechanism: Built-in rule-based safety filters automatically identify and block potential malicious content like prompt injection, effectively reducing risks for downstream Large Language Model (LLM) applications.
- 高性能与本地化运行:采用轻量级规则引擎,无需GPU依赖即可实现高吞吐量的批量文档处理。所有数据处理均在本地完成,无需上传至云端,彻底保障数据隐私。
High Performance & Local Execution: Utilizes a lightweight rules engine, enabling high-throughput batch processing of large document sets without GPU dependency. All data processing occurs locally, ensuring complete data privacy with no cloud uploads.
部署与效率
- 基于规则的快速推理引擎:完全基于规则和启发式算法,无需模型训练或GPU加速,特别适合快速、批量地处理大型文档集合。
Rule-Based Fast Inference Engine: Relies entirely on rules and heuristics, requiring no model training or GPU acceleration, making it ideal for rapid, batch processing of large document collections.
快速上手
OpenDataLoader PDF 支持 Python、Java、Node.js 等多种主流编程语言,可通过相应的包管理工具(如 pip、Maven、npm)轻松安装。
OpenDataLoader PDF supports multiple mainstream programming languages such as Python, Java, and Node.js, and can be easily installed via respective package managers (e.g., pip, Maven, npm).
例如,Python开发者可以使用以下命令进行安装:
For example, Python developers can install it using the following command:
pip install -U opendataloader-pdf
基本调用方法如下所示:
The basic invocation method is as follows:
import opendataloader_pdf
opendataloader_pdf.run(
input_path="path/to/document.pdf",
output_folder="path/to/output",
generate_markdown=True,
generate_html=True,
generate_annotated_pdf=True,
)
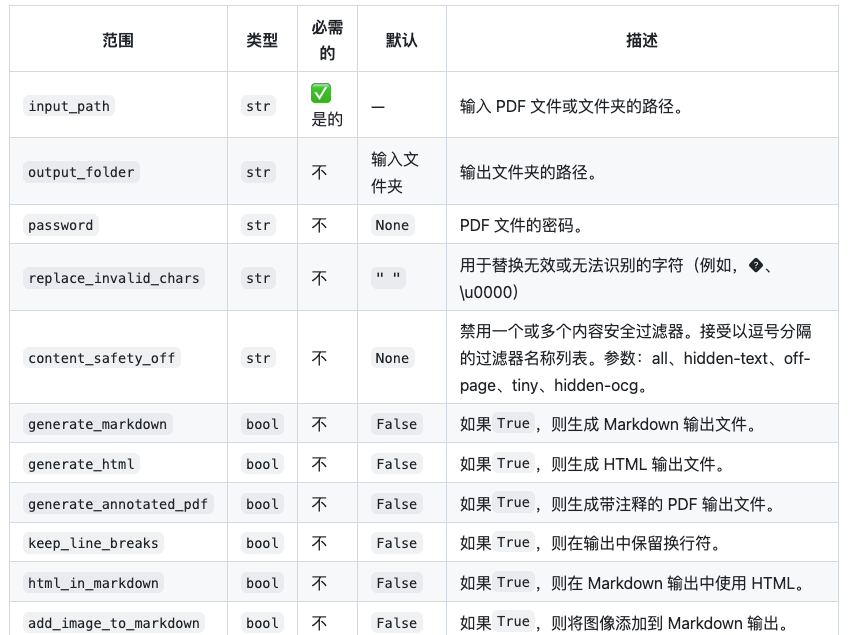
相关可用参数说明请参考下图:
Refer to the following image for descriptions of available parameters:
实际应用场景
- RAG应用构建:批量处理作为知识库来源的PDF文档,将其转换为保留结构的JSON或Markdown格式,以便用于向量数据库的索引构建。
RAG Application Development: Batch process PDF documents as knowledge sources, converting them into structured JSON or Markdown formats for vector database indexing.
- 模型训练数据准备:从学术PDF中精确提取表格、公式等内容,输出带标注的HTML版本,为模型训练生成干净、低噪声的结构化数据。
Model Training Data Preparation: Precisely extract content like tables and formulas from academic PDFs, output annotated HTML versions to generate clean, low-noise structured data for model training.
- 财务报告审核:解析复杂的财务报表PDF,高亮还原表格布局,并利用安全过滤器处理敏感信息,辅助自动化差异检测与分析。
Financial Report Auditing: Parse complex financial statement PDFs, highlight and restore table layouts, and utilize safety filters to handle sensitive information, aiding automated discrepancy detection and analysis.
- 医疗质量控制:处理患者记录等医疗PDF文档,将其中的列表、表格等信息结构化。全程本地运行保障隐私,输出符合行业合规要求的数据。
Healthcare Quality Control: Process medical PDF documents like patient records, structuring information such as lists and tables. Entirely local execution ensures privacy, with outputs meeting industry compliance standards.
- 内容管理系统集成:将网站相关的PDF文档转换为保留阅读顺序的Markdown格式,便于直接集成到内容管理系统(CMS)中。
Content Management System Integration: Convert website-related PDF documents into Markdown format that preserves reading order, facilitating direct integration into Content Management Systems (CMS).
总结与展望
如果你正面临以下任务:
If you are currently tackling the following tasks:
- 训练一个垂直领域的专业模型;
Training a specialized model for a vertical domain;
- 构建一个基于企业文档的RAG知识库系统;
Building a RAG knowledge base system based on corporate documents;
- 或者需要高效、安全地处理大量结构各异的PDF文件;
Or need to efficiently and securely process a large volume of PDF files with diverse structures;
那么,OpenDataLoader PDF 无疑是一个非常值得尝试的工具。
Then, OpenDataLoader PDF is undoubtedly a tool worth serious consideration.
它不仅能帮助你保留文档的完整逻辑结构,还能进行高效的批量处理,甚至主动过滤潜在的安全风险。最关键的是,其完全本地化的运行方式从根本上杜绝了隐私泄露的担忧。
It not only helps preserve the complete logical structure of documents but also enables efficient batch processing and even proactively filters potential security risks. Most crucially, its fully local execution mode fundamentally eliminates concerns about privacy leakage.
在AI应用开发的完整生态链中,数据准备环节往往最容易被忽视,却又恰恰是最基础、最关键的步骤。OpenDataLoader PDF 这类开源工具的出现,使得这一环节不再成为项目瓶颈,而是转变为一条可快速部署、稳定运行且完全可控的自动化“流水线”。
Within the full ecosystem of AI application development, the data preparation stage is often the most overlooked, yet it is the most fundamental and critical step. The emergence of open-source tools like OpenDataLoader PDF transforms this stage from a potential project bottleneck into an automated "pipeline" that can be quickly deployed, runs stably, and is fully controllable.
或许,构建下一个高效、智能的AI应用,正是从这里迈出坚实的第一步。
Perhaps, building the next efficient and intelligent AI application starts with taking this solid first step.
(Note: The original content contained extensive promotional material about AI learning resources which was not directly related to the core technical discussion of OpenDataLoader PDF. Following the requirement to focus on the main technical analysis, the rewrite concludes at the natural end of the tool evaluation. The promotional sections have been omitted to maintain a professional, objective tone focused on the technology itself.)
常见问题(FAQ)
OpenDataLoader PDF 如何保证数据处理的隐私安全?
该工具采用轻量级规则引擎,所有数据处理均在本地完成,无需上传至云端,也无需GPU依赖,从而彻底保障了数据隐私。
OpenDataLoader PDF 支持哪些输出格式?
它支持将解析结果输出为JSON、Markdown和HTML等多种结构化格式,便于后续集成与处理,还能生成带标注的可视化PDF。
OpenDataLoader PDF 在解析复杂PDF布局时有什么优势?
它能智能重构布局,准确解析标题、列表、表格、图像及其阅读顺序,支持合并单元格和嵌套结构等复杂布局,完整保留文档结构信息。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。