企业级RAG系统如何搭建?腾讯云智能体平台实战经验分享

RAG (Retrieval-Augmented Generation) bridges the gap between large language models' general knowledge and enterprise-specific data by retrieving relevant information from private knowledge bases to generate accurate, context-aware responses. This article provides a comprehensive roadmap for implementing enterprise-grade RAG systems, covering core principles, document parsing, chunking strategies, retrieval optimization, and practical deployment experiences with Tencent Cloud's Agent Development Platform.
原文翻译: RAG(检索增强生成)通过从企业私有知识库中检索相关信息来生成准确、上下文感知的响应,从而弥合大型语言模型通用知识与企业特定数据之间的差距。本文提供了实施企业级RAG系统的全面路线图,涵盖核心原理、文档解析、分块策略、检索优化以及腾讯云智能体开发平台的实际部署经验。
Enterprise RAG Implementation Guide: From Principles to Production Deployment
摘要
Abstract
大型语言模型的通用知识无法覆盖企业私有数据,而 RAG(Retrieval-Augmented Generation,检索增强生成)正是连接"通用智能"与"企业专有知识"的桥梁。本文从 RAG 的核心原理出发,逐层拆解向量数据库选型、文档解析、分块策略、检索优化和生成质量控制,并结合腾讯云智能体开发平台的实际落地经验,给出一套可直接复用的企业级 RAG 建设路线图。
The general knowledge of large language models cannot cover enterprise private data. RAG (Retrieval-Augmented Generation) serves as the bridge connecting "general intelligence" with "enterprise-specific knowledge". Starting from the core principles of RAG, this article deconstructs vector database selection, document parsing, chunking strategies, retrieval optimization, and generation quality control layer by layer. Combined with the practical implementation experience of Tencent Cloud Agent Development Platform, it provides a directly reusable roadmap for building enterprise-grade RAG systems.
核心要点:
Key Takeaways:
- RAG 解决的核心问题是让大模型"说得对"而不只是"说得像"
The core problem RAG solves is enabling large models to "speak correctly" rather than just "speak fluently".
- 文档解析与分块质量决定了 RAG 系统 80% 的效果上限
Document parsing and chunking quality determine 80% of the effectiveness ceiling of a RAG system.
- 向量检索并非万能,混合检索(向量 + 关键词)才是生产级方案的标配
Vector retrieval is not a panacea; hybrid retrieval (vector + keyword) is the standard for production-grade solutions.
- 企业级 RAG 不仅是技术架构,更是一套知识治理体系
Enterprise-grade RAG is not just a technical architecture but a knowledge governance system.
- 腾讯云智能体开发平台支持 28+ 文档格式解析和多种检索策略的开箱即用
Tencent Cloud Agent Development Platform supports out-of-the-box parsing for 28+ document formats and multiple retrieval strategies.
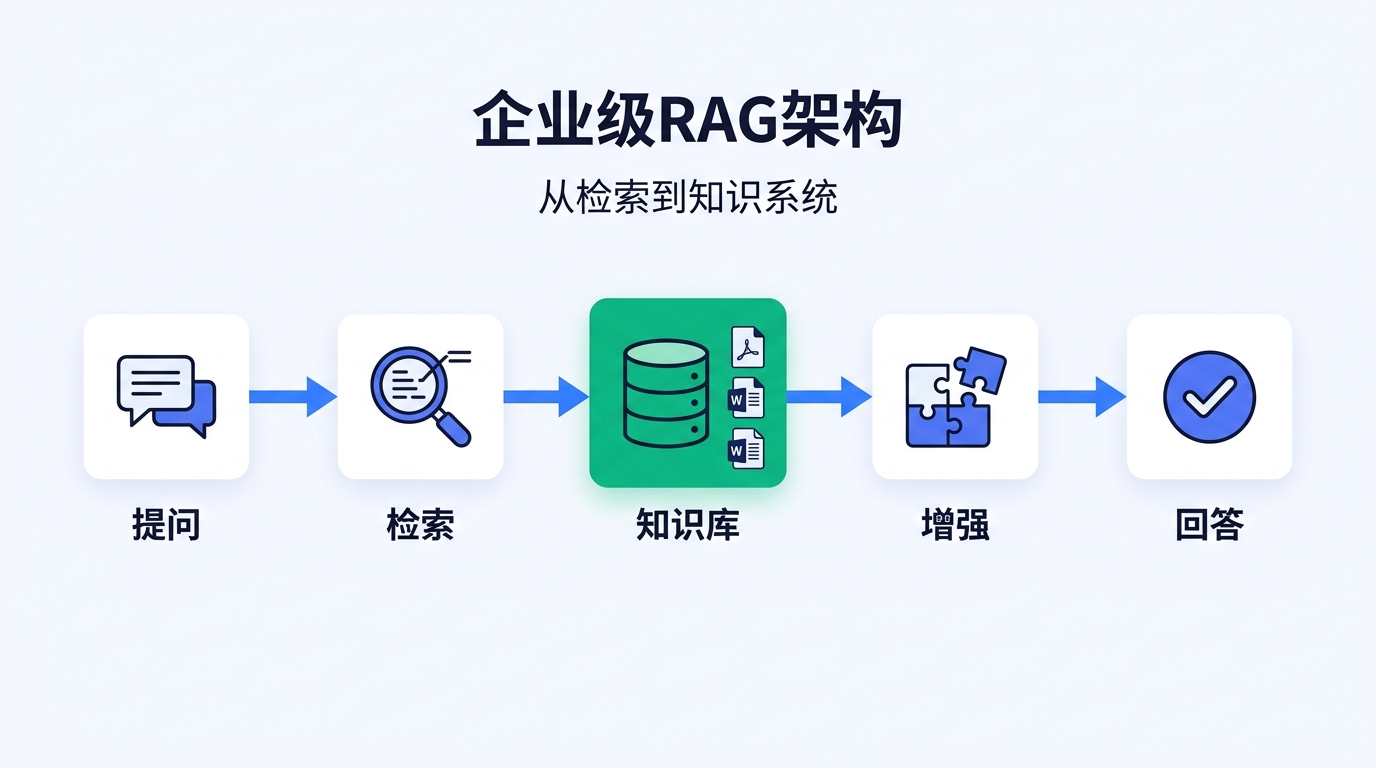
一、什么是 RAG?为什么企业需要它?
What is RAG? Why Do Enterprises Need It?
1.1 从大模型的"知识盲区"说起
1.1 Starting from the "Knowledge Gap" of Large Models
一家大型酒店集团在部署 AI 客服时遇到了这样的问题:通用大模型可以流畅地讨论旅游攻略,却无法回答"行政套房的退改政策是什么"——因为这些信息从未出现在模型的训练数据中。
A large hotel group encountered this problem when deploying an AI customer service agent: general-purpose large models could fluently discuss travel guides but couldn't answer "What is the cancellation policy for executive suites?"—because this information never appeared in the model's training data.
这就是 RAG 要解决的核心问题:让大模型能够访问和使用它从未"学过"的知识。
This is the core problem RAG aims to solve: enabling large models to access and utilize knowledge they have never "learned".
RAG(Retrieval-Augmented Generation)的工作原理非常直观:
The working principle of RAG (Retrieval-Augmented Generation) is very intuitive:
- 用户提问 → 系统将问题转换为语义向量
User Query → The system converts the question into a semantic vector.
- 检索 → 从企业知识库中找到最相关的文档片段
Retrieval → Find the most relevant document chunks from the enterprise knowledge base.
- 增强 → 将检索到的内容作为上下文注入提示词
Augmentation → Inject the retrieved content as context into the prompt.
- 生成 → 大模型基于真实文档生成准确回答
Generation → The large model generates accurate answers based on the real documents.
1.2 RAG 与微调:不是替代,而是互补
1.2 RAG vs. Fine-tuning: Not Substitutes, but Complements
很多团队在落地 AI 应用时会纠结:应该用 RAG 还是微调(Fine-tuning)?实际上,两者解决的是不同的问题。
Many teams struggle when implementing AI applications: should they use RAG or fine-tuning? In reality, they address different problems.
| 维度 | RAG | 微调(Fine-tuning) |
|---|---|---|
| 核心作用 | 引入外部知识,回答基于事实的问题 | 调整模型行为风格和领域适配 |
| 知识更新 | 实时生效,更新文档即可 | 需要重新训练,周期以天或周计 |
| 成本 | 增量成本低,主要是检索和存储 | 训练成本高,需要 GPU 算力 |
| 幻觉控制 | 有据可查,可追溯到原始文档 | 仍可能产生幻觉 |
| 适用场景 | 知识密集型问答、文档查询、客服 | 风格适配、特定任务优化 |
| 数据隐私 | 数据留在自己的知识库,不进入模型 | 数据需要参与训练过程 |
实战经验:在腾讯云智能体开发平台的企业客户中,超过 90% 的知识问答场景通过 RAG 即可满足需求,只有少数需要深度领域适配的场景才需要额外微调。
Practical Experience: Among enterprise customers of Tencent Cloud Agent Development Platform, over 90% of knowledge Q&A scenarios can be satisfied with RAG alone. Only a few scenarios requiring deep domain adaptation need additional fine-tuning.
1.3 RAG 能做什么?不能做什么?
1.3 What Can RAG Do? What Can't It Do?
RAG 不是银弹。清晰地了解它的能力边界,才能做出正确的技术选型。
RAG is not a silver bullet. Clearly understanding its capability boundaries is crucial for making correct technical choices.
RAG 擅长的场景:
Scenarios Where RAG Excels:
- 企业内部知识库问答(政策、流程、手册)
Internal enterprise knowledge base Q&A (policies, processes, manuals)
- 客户服务中的产品知识查询
Product knowledge queries in customer service
- 法律法规、合规文档检索
Legal, regulatory, and compliance document retrieval
- 技术文档和 API 手册查询
Technical documentation and API manual queries
- 研报分析和行业情报提取
Research report analysis and industry intelligence extraction
RAG 不适合的场景:
Scenarios Where RAG is Not Suitable:
- 需要多步推理和复杂计算的任务
Tasks requiring multi-step reasoning and complex calculations
- 高度创意性的内容生成
Highly creative content generation
- 数据量极小(几十条记录以下)的场景——直接写进提示词更高效
Scenarios with extremely small data volume (below dozens of records)—directly writing into the prompt is more efficient
- 需要实时数据流处理的场景(如股票行情)
Scenarios requiring real-time data stream processing (e.g., stock quotes)
二、RAG 如何工作?核心架构拆解
How Does RAG Work? Deconstructing the Core Architecture
2.1 标准 RAG 流水线
2.1 Standard RAG Pipeline
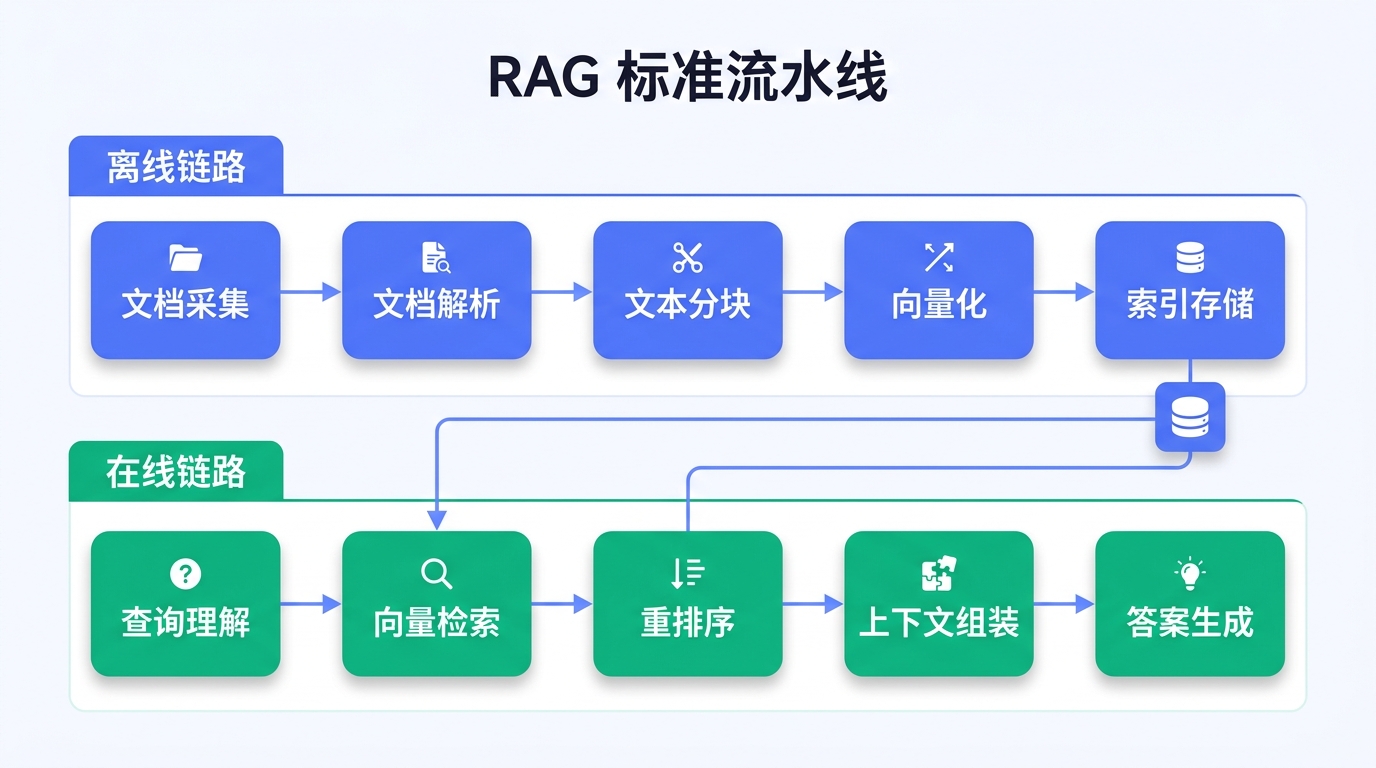
一个生产级 RAG 系统的完整流水线包含两条链路:
A complete production-grade RAG system pipeline consists of two links:
离线链路(数据准备):
Offline Link (Data Preparation):
| 步骤 | 处理内容 | 关键指标 |
|---|---|---|
| 文档采集 | 从多源(文件系统、数据库、API)获取原始文档 | 格式覆盖率 |
| 文档解析 | 将 PDF、Word、PPT 等转换为结构化文本 | 解析准确率 |
| 文本分块 | 将长文档切分为语义完整的片段 | 分块质量 |
| 向量化 | 通过 Embedding 模型将文本转换为向量 | 语义保真度 |
| 索引存储 | 将向量写入向量数据库并建立索引 | 检索延迟 |
在线链路(查询处理):
Online Link (Query Processing):
| 步骤 | 处理内容 | 关键指标 |
|---|---|---|
| 查询理解 | 解析用户意图,必要时改写查询 | 意图识别准确率 |
| 向量检索 | 在向量数据库中找到最相似的文档片段 | 召回率 |
| 重排序 | 对检索结果进行精排,提升相关性 | 精排准确率 |
| 上下文组装 | 将相关片段拼接为结构化提示词 | 上下文利用率 |
| 答案生成 | 大模型基于上下文生成回答 | 回答准确率 |
2.2 从"能用"到"好用":进阶 RAG 架构
2.2 From "Usable" to "Excellent": Advanced RAG Architectures
基础 RAG 在 PoC 阶段表现尚可,但放到生产环境中往往会暴露多种问题。以下是三种进阶架构模式:
Basic RAG performs adequately in the PoC stage but often exposes various problems in production environments. Here are three advanced architecture patterns:
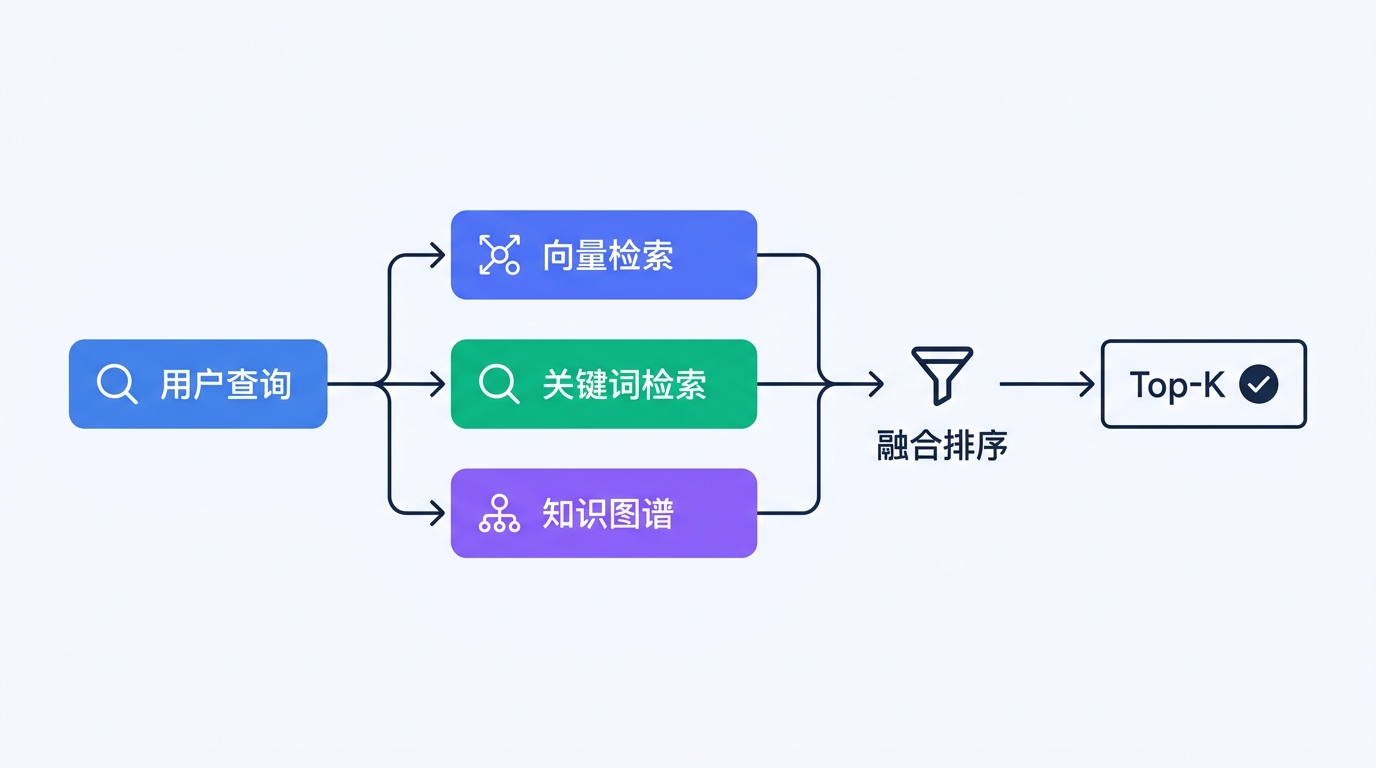
模式一:多路检索融合
Pattern One: Multi-Retrieval Fusion
单一的向量检索难以覆盖所有查询类型。例如,用户搜索"保修期限是几年"时,关键词匹配可能比语义检索更精准。
Single vector retrieval struggles to cover all query types. For example, when a user searches for "warranty period in years," keyword matching might be more precise than semantic retrieval.
模式二:查询改写与分解
Pattern Two: Query Rewriting and Decomposition
用户的提问通常不够精确。通过查询改写,可以显著提升检索质量:
User queries are often imprecise. Query rewriting can significantly improve retrieval quality:
| 改写策略 | 原始查询 | 改写后 | 效果 |
|---|---|---|---|
| 意图澄清 | "保险怎么弄" | "如何申请车辆保险理赔" | 消除歧义 |
| 问题分解 | "A 和 B 哪个好" | "A 的特点是什么" + "B 的特点是什么" | 拆分复杂查询 |
| 假设文档 | "退货流程" | 生成一段"理想答案"用于检索 | 提升语义匹配 |
模式三:自适应检索(Agentic RAG)
Pattern Three: Adaptive Retrieval (Agentic RAG)
最先进的 RAG 架构不再是固定流水线,而是由 Agent 动态决定检索策略:
The most advanced RAG architecture is no longer a fixed pipeline but dynamically determines retrieval strategies via an Agent:
- 简单事实查询 → 直接向量检索
Simple factual query → Direct vector retrieval
- 多条件查询 → 结构化查询 + 向量检索
Multi-condition query → Structured query + vector retrieval
- 跨文档综合分析 → 多轮迭代检索 + 信息聚合
Cross-document comprehensive analysis → Multi-round iterative retrieval + information aggregation
- 已有上下文可回答 → 跳过检索,直接生成
Answerable with existing context → Skip retrieval, generate directly
三、文档解析:RAG 的"地基工程"
Document Parsing: The "Foundation Work" of RAG
3.1 为什么文档解析如此重要?
3.1 Why is Document Parsing So Important?
在大量企业 RAG 项目的实践中,一个反直觉的结论是:文档解析质量对最终效果的影响,远大于模型选型或检索算法的优化。
In the practice of numerous enterprise RAG projects, a counterintuitive conclusion is: The impact of document parsing quality on the final outcome far exceeds that of model selection or retrieval algorithm optimization.
一份包含嵌套表格、图表和复杂排版的 PDF 财报,如果解析阶段就丢失了表格结构,后续无论用多好的向量模型,检索出的内容都是残缺的。
For a PDF financial report containing nested tables, charts, and complex layouts, if the table structure is lost during the parsing stage, the retrieved content will be incomplete regardless of how good the vector model used later is.
3.2 常见文档格式与解析挑战
3.2 Common Document Formats and Parsing Challenges
| 文档格式 | 核心挑战 | 常见问题 |
|---|---|---|
| 非结构化排版、扫描件 OCR | 多栏布局错乱、表格结构丢失、图片中的文字无法提取 | |
| Word/DOCX | 嵌套样式、批注和修订 | 表格跨页断裂、文本框内容遗漏 |
| PPT | 非线性内容、图文混排 | 幻灯片顺序与逻辑不一致、SmartArt 无法解析 |
| Excel | 多 Sheet 交叉引用、公式 | 公式结果丢失、合并单元格解析错误 |
| 网页/HTML | 动态加载、广告噪声 | 有效内容识别困难、导航和页脚干扰 |
| 扫描件/图片 | OCR 精度、版面分析 | 手写体识别率低、复杂版面还原困难 |

3.3 腾讯云智能体开发平台的文档解析能力
3.3 Document Parsing Capabilities of Tencent Cloud Agent Development Platform
腾讯云智能体开发平台内置了企业级文档解析引擎,支持 28+ 种文档格式的自动解析:
Tencent Cloud Agent Development Platform has a built-in enterprise-grade document parsing engine, supporting automatic parsing of 28+ document formats:
| 能力 | 规格 | 业务价值 |
|---|---|---|
| 格式支持 | PDF、Word、Excel、PPT、HTML、Markdown、TXT 等 28+ 种 | 无需预处理,直接上传 |
| 单文件上限 | 200MB | 大型技术手册、合规文档无压力 |
| 表格解析 | 自动识别并保留表格结构 | 财报、参数表等表格密集文档的准确检索 |
| OCR 能力 | 集成腾讯云 OCR,支持扫描件和图片 | 历史纸质文档数字化 |
| 多语言 | 中文、英文、日文等主流语言 | 跨国企业多语言知识库 |
数据参考:某大型酒店集团在接入腾讯云智能体开发平台后,客服知识库准确率达到 95% 以上,首 Token 响应时间控制在 5 秒以内,FAQ 维护量从 1000+ 条缩减至 100+ 条。
Data Reference: After a large
常见问题(FAQ)
RAG和微调有什么区别?企业应该怎么选?
RAG用于引入外部知识,实时更新,成本低,能追溯来源控制幻觉;微调用于调整模型风格和领域适配,更新慢,训练成本高。两者互补而非替代。
实施企业级RAG系统最关键的技术环节是什么?
文档解析与分块质量决定了RAG系统80%的效果上限。同时,生产级方案应采用混合检索(向量+关键词),而不仅是向量检索。
腾讯云智能体开发平台对RAG实施有哪些支持?
平台支持28+种文档格式的解析和多种检索策略的开箱即用,提供了可直接复用的企业级RAG建设路线图和实际部署经验。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。