知识图谱是什么?2026年AI应用与核心概念深度解析

Knowledge Graphs (KGs) are structured data representations that organize information as nodes and edges, enabling advanced applications in web search, enterprise data integration, and AI. They serve as a bridge between human-understandable knowledge and machine learning models, with recent growth driven by large-scale projects like Wikidata and enterprise solutions.
原文翻译: 知识图谱(KGs)是一种结构化数据表示方法,将信息组织为节点和边,支持在网页搜索、企业数据集成和人工智能中的高级应用。它们作为人类可理解知识与机器学习模型之间的桥梁,近期因大规模项目(如Wikidata)和企业解决方案而迅速发展。
知识图谱(Knowledge Graphs, KGs)已成为组织世界结构化知识、整合多源信息的一种极具吸引力的抽象方法。知识图谱在表示通过自然语言处理和计算机视觉提取的信息方面开始发挥核心作用。表达在知识图谱中的领域知识正被输入到机器学习模型中,以产生更好的预测。本文的目标是:(a) 解释知识图谱的基本术语、概念和用途,(b) 强调导致其近期流行的知识图谱应用,以及 (c) 将知识图谱置于人工智能的整体发展图景中。在阅读更广泛的综述或参加相关研究研讨会之前,本文是一个很好的起点。
知识图谱(Knowledge Graphs, KGs)已成为组织世界结构化知识、整合多源信息的一种极具吸引力的抽象方法。知识图谱在表示通过自然语言处理和计算机视觉提取的信息方面开始发挥核心作用。表达在知识图谱中的领域知识正被输入到机器学习模型中,以产生更好的预测。本文的目标是:(a) 解释知识图谱的基本术语、概念和用途,(b) 强调导致其近期流行的知识图谱应用,以及 (c) 将知识图谱置于人工智能的整体发展图景中。在阅读更广泛的综述或参加相关研究研讨会之前,本文是一个很好的起点。
知识图谱的定义
一个有向标记图是一个四元组 G = (N, E, L, f),其中 N 是节点集合,E ⊆ N × N 是边集合,L 是标签集合,而 f: E→L 是一个从边到标签的分配函数。将标签 B 分配给边 E=(A,C) 可以看作是一个三元组 (A, B, C),并如图1所示进行可视化。
一个有向标记图是一个四元组 G = (N, E, L, f),其中 N 是节点集合,E ⊆ N × N 是边集合,L 是标签集合,而 f: E→L 是一个从边到标签的分配函数。将标签 B 分配给边 E=(A,C) 可以看作是一个三元组 (A, B, C),并如图1所示进行可视化。
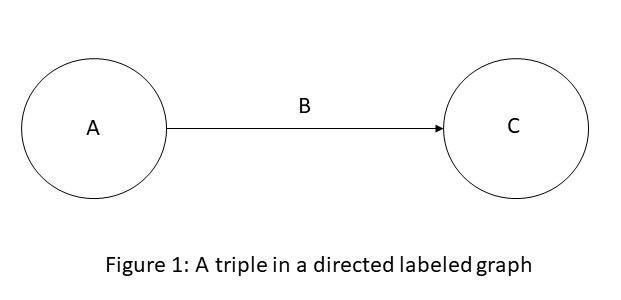
知识图谱是一种有向标记图,其中我们为节点和边关联了特定领域的含义。任何事物都可以作为节点,例如人、公司、计算机等。边标签捕获节点之间感兴趣的关系,例如两个人之间的朋友关系、公司与个人之间的客户关系,或两台计算机之间的网络连接等。
知识图谱是一种有向标记图,其中我们为节点和边关联了特定领域的含义。任何事物都可以作为节点,例如人、公司、计算机等。边标签捕获节点之间感兴趣的关系,例如两个人之间的朋友关系、公司与个人之间的客户关系,或两台计算机之间的网络连接等。
有向标记图表示根据应用程序的需求以多种方式使用。例如,节点是人、边捕获亲子关系的有向标记图也称为数据图。节点是对象类(例如,书籍、教科书等)、边捕获子类关系的有向标记图也称为分类法。在某些数据模型中,给定一个三元组 (A,B,C),我们分别称 A、B、C 为三元组的主语、谓语和宾语。
有向标记图表示根据应用程序的需求以多种方式使用。例如,节点是人、边捕获亲子关系的有向标记图也称为数据图。节点是对象类(例如,书籍、教科书等)、边捕获子类关系的有向标记图也称为分类法。在某些数据模型中,给定一个三元组 (A,B,C),我们分别称 A、B、C 为三元组的主语、谓语和宾语。
知识图谱作为一种数据结构,应用程序在其中存储信息。信息可以通过人工输入、自动和半自动方法的组合添加到知识图谱中。无论知识录入的方式如何,都期望记录的信息能够被人类轻松理解和验证。
知识图谱作为一种数据结构,应用程序在其中存储信息。信息可以通过人工输入、自动和半自动方法的组合添加到知识图谱中。无论知识录入的方式如何,都期望记录的信息能够被人类轻松理解和验证。
图上的许多有趣计算可以简化为对图的遍历。例如,在一个友谊知识图谱中,要计算一个人 A 的朋友的朋友,我们可以从 A 开始遍历图,找到所有通过标记为“朋友”的关系与之相连的节点 B,然后递归地找到每个 B 通过“朋友”关系相连的所有节点 C。
图上的许多有趣计算可以简化为对图的遍历。例如,在一个友谊知识图谱中,要计算一个人 A 的朋友的朋友,我们可以从 A 开始遍历图,找到所有通过标记为“朋友”的关系与之相连的节点 B,然后递归地找到每个 B 通过“朋友”关系相连的所有节点 C。
知识图谱的近期应用
将有向标记图用作存储信息的数据结构,并使用图算法来操作该信息,这并不是什么新鲜事。在计算机科学领域,有向图表示已有许多用途,例如数据流图、二元决策图、状态图等。我们在此考虑两个具体的应用,它们导致了知识图谱近期的流行度激增:组织互联网上的信息和企业中的数据集成。在讨论这些应用时,我们也会强调知识图谱使用中的新颖和不同之处。
将有向标记图用作存储信息的数据结构,并使用图算法来操作该信息,这并不是什么新鲜事。在计算机科学领域,有向图表示已有许多用途,例如数据流图、二元决策图、状态图等。我们在此考虑两个具体的应用,它们导致了知识图谱近期的流行度激增:组织互联网上的信息和企业中的数据集成。在讨论这些应用时,我们也会强调知识图谱使用中的新颖和不同之处。
组织互联网上的知识
考虑谷歌搜索“Winterthur Zurich”,返回的结果如图2左侧面板所示,右侧面板显示了来自维基百科的相关部分。右侧面板中显示的维基百科页面部分也称为信息框。
考虑谷歌搜索“Winterthur Zurich”,返回的结果如图2左侧面板所示,右侧面板显示了来自维基百科的相关部分。右侧面板中显示的维基百科页面部分也称为信息框。
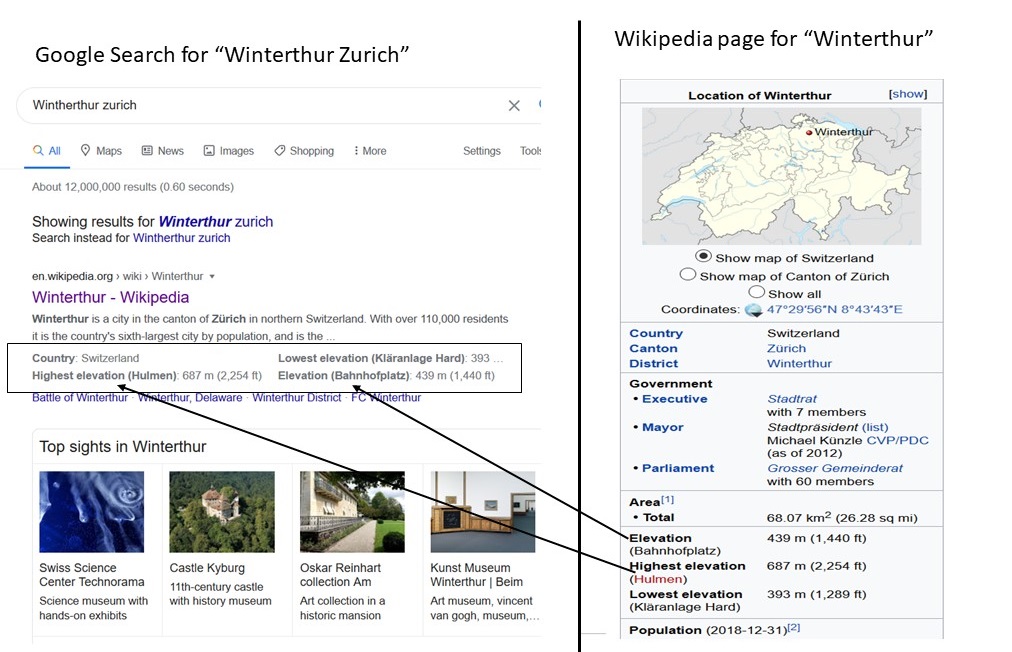 图2:知识图谱在网页搜索结果中的应用示例
图2:知识图谱在网页搜索结果中的应用示例
在搜索结果中,我们看到诸如温特图尔位于瑞士、海拔430米等事实。这些信息直接提取自温特图尔维基百科页面的信息框。维基百科信息框中的部分数据是通过查询一个名为Wikidata的知识图谱来填充的。知识图谱中的数据可以比上述示例更深入地增强网络搜索,我们接下来将进行讨论。
在搜索结果中,我们看到诸如温特图尔位于瑞士、海拔430米等事实。这些信息直接提取自温特图尔维基百科页面的信息框。维基百科信息框中的部分数据是通过查询一个名为Wikidata的知识图谱来填充的。知识图谱中的数据可以比上述示例更深入地增强网络搜索,我们接下来将进行讨论。
温特图尔的维基百科页面列出了其友好城市:两个在瑞士,一个在捷克共和国,一个在奥地利。加利福尼亚州安大略市有一个维基百科页面,标题为“安大略,加利福尼亚”,将温特图尔列为它的姐妹城市。姐妹城市和友好城市关系是相同且互惠的。因此,如果城市 A 是城市 B 的姐妹(友好)城市,那么 B 也必须是 A 的姐妹(友好)城市。由于“姐妹城市”和“友好城市”是维基百科中的章节标题,没有定义或指定两者之间的关系,因此很难检测到这种不一致。相比之下,在温特图尔的 Wikidata 表示中,有一个名为结对行政体的关系,其中列出了安大略市。由于该关系在知识图谱中被定义为对称关系,安大略市的 Wikidata 页面会自动包含温特图尔。Wikidata 通过其管理员的努力以及使用知识图谱作为存储和推理机制,解决了识别等价关系的问题。只要 Wikidata 知识图谱完全集成到维基百科中,本文示例中考虑的缺失链接的不一致问题自然会消失。我们可以在图3中可视化温特图尔和安大略之间的双向关系。图3中的知识图谱还显示了与温特图尔和安大略相连的其他对象。
温特图尔的维基百科页面列出了其友好城市:两个在瑞士,一个在捷克共和国,一个在奥地利。加利福尼亚州安大略市有一个维基百科页面,标题为“安大略,加利福尼亚”,将温特图尔列为它的姐妹城市。姐妹城市和友好城市关系是相同且互惠的。因此,如果城市 A 是城市 B 的姐妹(友好)城市,那么 B 也必须是 A 的姐妹(友好)城市。由于“姐妹城市”和“友好城市”是维基百科中的章节标题,没有定义或指定两者之间的关系,因此很难检测到这种不一致。相比之下,在温特图尔的 Wikidata 表示中,有一个名为结对行政体的关系,其中列出了安大略市。由于该关系在知识图谱中被定义为对称关系,安大略市的 Wikidata 页面会自动包含温特图尔。Wikidata 通过其管理员的努力以及使用知识图谱作为存储和推理机制,解决了识别等价关系的问题。只要 Wikidata 知识图谱完全集成到维基百科中,本文示例中考虑的缺失链接的不一致问题自然会消失。我们可以在图3中可视化温特图尔和安大略之间的双向关系。图3中的知识图谱还显示了与温特图尔和安大略相连的其他对象。
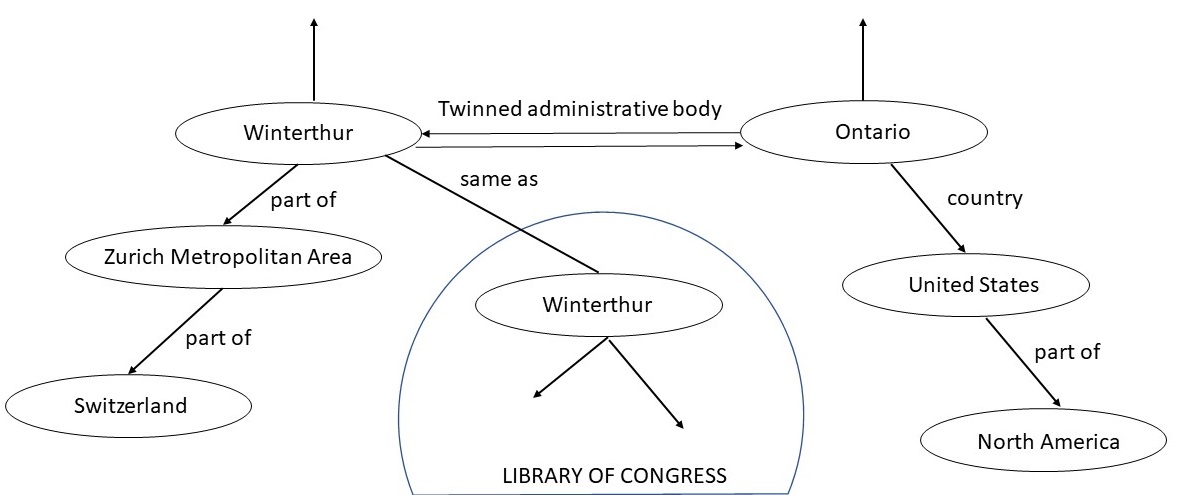 图3:Wikidata 知识图谱的一个片段
图3:Wikidata 知识图谱的一个片段
Wikidata 包含来自国会图书馆等多个独立提供者的数据。通过使用温特图尔的 Wikidata 标识符,国会图书馆发布的信息可以轻松地与 Wikidata 中存在的关于温特图尔的其他信息链接起来。Wikidata 通过在 Schema.Org 中发布其使用的关系定义,使得建立此类链接变得容易。
Wikidata 包含来自国会图书馆等多个独立提供者的数据。通过使用温特图尔的 Wikidata 标识符,国会图书馆发布的信息可以轻松地与 Wikidata 中存在的关于温特图尔的其他信息链接起来。Wikidata 通过在 Schema.Org 中发布其使用的关系定义,使得建立此类链接变得容易。
Schema.Org 中记录良好的关系列表(也称为关系词汇表)至少给我们带来两个优势。首先,更容易编写跨多个数据集的查询,因为查询可以使用这些数据源共有的关系来构建。如果没有跨多个源使用这种通用关系,我们将需要确定它们之间的语义关系并提供适当的转换。一个跨多个源的查询示例是:在地图上显示在温特图尔去世的人们的出生城市?其次,搜索引擎可以使用此类查询从知识图谱中检索信息,并显示如图2所示的查询结果。在搜索结果中使用返回的结构化信息现已成为主流搜索引擎的标准功能。
Schema.Org 中记录良好的关系列表(也称为关系词汇表)至少给我们带来两个优势。首先,更容易编写跨多个数据集的查询,因为查询可以使用这些数据源共有的关系来构建。如果没有跨多个源使用这种通用关系,我们将需要确定它们之间的语义关系并提供适当的转换。一个跨多个源的查询示例是:在地图上显示在温特图尔去世的人们的出生城市?其次,搜索引擎可以使用此类查询从知识图谱中检索信息,并显示如图2所示的查询结果。在搜索结果中使用返回的结构化信息现已成为主流搜索引擎的标准功能。
Wikidata 的最新版本拥有超过 9000 万个对象,这些对象之间存在超过 10 亿个关系。Wikidata 连接了来自独立数据提供者发布的 414 种不同语言、超过 4872 个不同目录的数据。根据最近的估计,31% 的网站和超过 1200 万个数据提供者目前正在使用 Schema.Org 的词汇表来发布其网页的注释。
Wikidata 的最新版本拥有超过 9000 万个对象,这些对象之间存在超过 10 亿个关系。Wikidata 连接了来自独立数据提供者发布的 414 种不同语言、超过 4872 个不同目录的数据。根据最近的估计,31% 的网站和超过 1200 万个数据提供者目前正在使用 Schema.Org 的词汇表来发布其网页的注释。
Wikidata 知识图谱有哪些特别新颖和令人兴奋之处?首先,它是一个规模空前的图谱,是当今可用的最大知识图谱之一。其次,尽管 Wikidata 是人工管理的,但管理成本由贡献者社区分担。第三,Wikidata 中的部分数据可能来自自动提取的信息,但根据 Wikidata 的编辑政策,这些信息必须易于理解和验证。第四,通过 Schema.Org 中的词汇表,明确努力提供不同关系名称的语义定义。最后,Wikidata 的主要驱动用例是改进网络搜索。尽管 Wikidata 有几个用于分析和可视化的应用程序,但其在网络上的使用仍然是最引人注目且易于理解的应用。
Wikidata 知识图谱有哪些特别新颖和令人兴奋之处?首先,它是一个规模空前的图谱,是当今可用的最大知识图谱之一。其次,尽管 Wikidata 是人工管理的,但管理成本由贡献者社区分担。第三,Wikidata 中的部分数据可能来自自动提取的信息,但根据 Wikidata 的编辑政策,这些信息必须易于理解和验证。第四,通过 Schema.Org 中的词汇表,明确努力提供不同关系名称的语义定义。最后,Wikidata 的主要驱动用例是改进网络搜索。尽管 Wikidata 有几个用于分析和可视化的应用程序,但其在网络上的使用仍然是最引人注目且易于理解的应用。
企业中的数据集成
 图4:通过整合外部数据与内部公司信息创建客户360度视图
图4:通过整合外部数据与内部公司信息创建客户360度视图
许多金融机构希望通过360度视图更好地管理客户关系,即整合关于客户的内部信息和外部信息的视图。例如,可以整合来自金融新闻的公开信息、商业来源和整理的供应链关系数据以及内部客户信息,以创建这样的360度视图。为了理解这种视图的用处,让我们考虑一个示例场景。金融新闻报道称,“Acma Retail Inc”因疫情已申请破产,因此其许多供应商将面临财务压力。这种压力可能深入其供应链,并引发其他客户的财务困难。例如,如果作为 Acma 供应商的公司 A 正在经历财务压力,那么 A 的供应商公司也将经历类似的压力。此类供应链关系作为商业可用数据集 Factset 的一部分进行整理。在360度视图中,来自 Factset 和金融新闻的数据与内部客户数据库集成。由此产生的知识图谱准确跟踪 Acma 的供应链,识别具有不同收入敞口的压力供应商,并确定其风险值得监控的公司。
许多金融机构希望通过360度视图更好地管理客户关系,即整合关于客户的内部信息和外部信息的视图。例如,可以整合来自金融新闻的公开信息、商业来源和整理的供应链关系数据以及内部客户信息,以创建这样的360度视图。为了理解这种视图的用处,让我们考虑一个示例场景。金融新闻报道称,“Acma Retail Inc”因
常见问题(FAQ)
知识图谱到底是什么?
知识图谱是一种结构化数据表示方法,将信息组织为节点和边,形成有向标记图。它为节点和边赋予特定领域含义,如用节点表示人或公司,用边表示关系,使机器能理解和处理复杂知识。
知识图谱在现实中有哪些应用?
知识图谱广泛应用于网页搜索(如谷歌搜索结果增强)、企业数据集成和人工智能领域。它能组织互联网信息,例如通过Wikidata填充维基百科信息框,并帮助企业整合多源数据,提升数据管理效率。
知识图谱如何与人工智能结合?
知识图谱作为人类知识与机器学习模型的桥梁,将结构化领域知识输入AI模型以改善预测。它通过自然语言处理和计算机视觉提取信息,支持图遍历等计算,增强AI系统的理解和推理能力。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。