结构化生成如何提升大语言模型性能?实测GSM8K基准提升70%+

AI Summary (BLUF)
Structured generation in LLMs consistently improves performance on the GSM8K benchmark, with up to 70%+ gains, and offers additional benefits like prompt consistency and thought-control.
原文翻译: LLM中的结构化生成在GSM8K基准测试中持续提升性能,最高可达70%以上的增益,并带来提示一致性和思维控制等额外优势。
In this post, we present a series of experiments demonstrating that structured generation in Large Language Models (LLMs) leads to consistent and often substantial improvements in model performance on the GSM8K evaluation set.
本文通过一系列实验证明,在大语言模型(LLMs)中使用结构化生成,可以在GSM8K评估集上带来一致且通常是显著的性能提升。
Key findings include:
主要发现包括:
- Across 8 different models, using structured generation can lead to a greater than 70% lift in performance and in all cases led to improvement in performance over unstructured generation.
在8个不同的模型中,使用结构化生成可使性能提升超过70%,并且在所有情况下,其性能均优于非结构化生成。
- Additionally we find evidence of previously unexplored benefits of structured generation: “prompt consistency” and “thought-control”.
此外,我们还发现了结构化生成此前未被探索的益处:“提示一致性”和“思维控制”。
- Even if structured output from an LLM is not essential to a project, structured generation is still worth using in your model for its performance benefits.
即使LLM的结构化输出对于项目并非必需,为了其带来的性能优势,结构化生成仍然值得在模型中使用。
Experimental Setup
In order to test the impact of structured generation on the quality of LLM output, we evaluated 8 different models on the GSM8K test set, which consists of 1319 grade school math word problems. We used a standardized 8-shot prompt from the EleutherAI LM Evaluation Harness. We compared the results of parsing unstructured output (closely replicating the LM Evaluation Harness behavior) with controlling the output using regex-structured generation via Outlines.
为了测试结构化生成对LLM输出质量的影响,我们在包含1319个小学数学文字问题的GSM8K测试集上评估了8个不同的模型。我们使用了来自EleutherAI LM评估工具的标准化8样本提示。我们比较了解析非结构化输出(紧密复现LM评估工具的行为)与使用Outlines通过正则表达式结构化生成来控制输出的结果。
Structure of GSM8K Questions and Answers
The GSM8K question/answers, despite not having an obvious format, do indeed contain a clear structure, as we can see in the visualization below of one example question from the 8-shot prompt:
GSM8K的问题/答案虽然没有明显的格式,但确实包含清晰的结构,如下方8样本提示中的一个示例问题可视化所示:

One of the challenges when running evaluations is correctly parsing the output of the model. As shown in the image, we can create a regex to match this inherent structure in the GSM8K data. A regex similar to this one is used in the EleutherAI lm-evaluation-harness.
进行评估时的挑战之一是如何正确解析模型的输出。如图所示,我们可以创建一个正则表达式来匹配GSM8K数据中的这种固有结构。EleutherAI的lm-evaluation-harness就使用了类似的正则表达式。
However, structured generation can use this very regex not just to parse an output, but rather to guarantee the output adheres to this structure. This means that when using structured generation, we never have to worry about whether or not we will be able to correctly parse the answer.
然而,结构化生成可以利用这个正则表达式,不仅用于解析输出,更能保证输出遵循这种结构。这意味着在使用结构化生成时,我们永远不必担心是否能够正确解析答案。
Results
The results of our experiments show that structured generation consistently improves model performance. This effect is particularly strong in under-performing models, where structured generation can, in cases such as EleutherAI/gpt-j-6b, more than double performance (although, admittedly, the base score is low). Additionally, performance gains were seen even in models specifically tuned for this task, like Pearl-7B-slerp and MetaMath-Tulpar-7b-V2-slerp. These improvements are visualized below:
我们的实验结果表明,结构化生成能持续提升模型性能。 这种效果在表现欠佳的模型中尤其显著,例如在EleutherAI/gpt-j-6b模型中,结构化生成可以使性能翻倍以上(尽管其基础分数确实较低)。此外,即使在专门为此任务调优的模型(如Pearl-7B-slerp和MetaMath-Tulpar-7b-V2-slerp)中也观察到了性能提升。这些改进如下图所示:
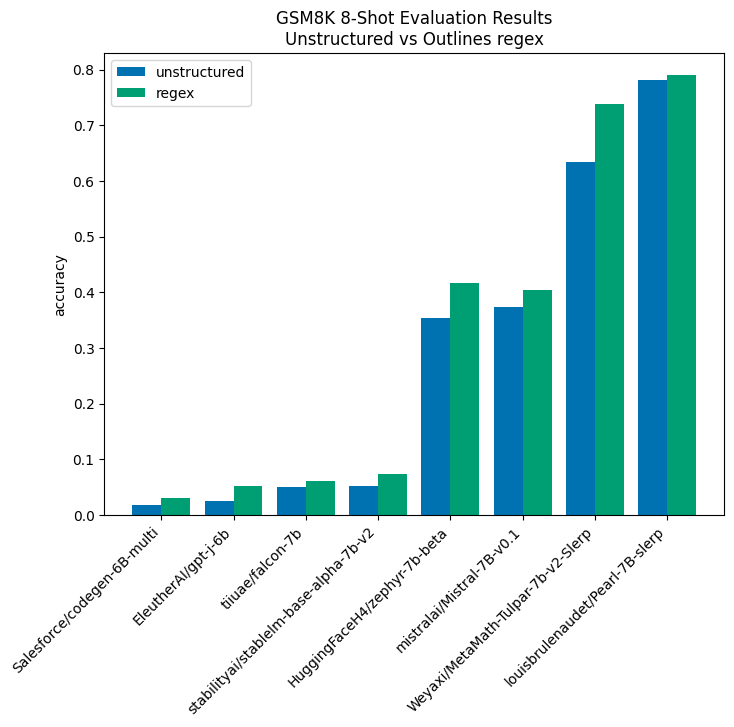
In all cases, there is a performance improvement from using structured generation, and in all but the top-performing model, the improvement is greater than 10%.
在所有情况下,使用结构化生成都带来了性能提升。除了表现最佳的模型外,其他所有模型的提升幅度均超过10%。
JSON Structuring
By exploiting the inherent structure in the GSM8K benchmark prompt, we were able to achieve consistent improvements across all models. Another reasonable approach to dealing with structure is to better structure the prompt itself. JSON is a common format for structured data that allows us to easily integrate our model with other code (including evaluation code). Given its ubiquitous nature, it makes sense to reformat our original question, reasoning, and answer data into JSON. Here is an example of the same questions reformatted into JSON.
通过利用GSM8K基准提示中固有的结构,我们在所有模型上都取得了持续的改进。处理结构的另一个合理方法是更好地构建提示本身。JSON是一种常见的结构化数据格式,使我们能够轻松地将模型与其他代码(包括评估代码)集成。鉴于其普遍性,将原始的问题、推理和答案数据重新格式化为JSON是合理的。以下是将相同问题重新格式化为JSON的示例。

In the case of Mistral-7B-v0.1, we found that using this JSON format in the prompt alone, without structured generation, resulted in a 17.5% lift over the baseline unstructured prompt performance. Furthermore, it provided an 8.2% lift over even the structured result for the original QA prompt. However, enforcing structure on the JSON-formatted prompt provided an even further lift of 20.7% over baseline performance! The chart below visualizes these results:
在Mistral-7B-v0.1模型中,我们发现,仅在提示中使用这种JSON格式(不使用结构化生成),其性能就比基线非结构化提示提升了17.5%。此外,它甚至比原始QA提示的结构化结果还高出8.2%。然而,对JSON格式的提示强制执行结构化,带来了更进一步的提升,比基线性能高出20.7%!下图展示了这些结果:
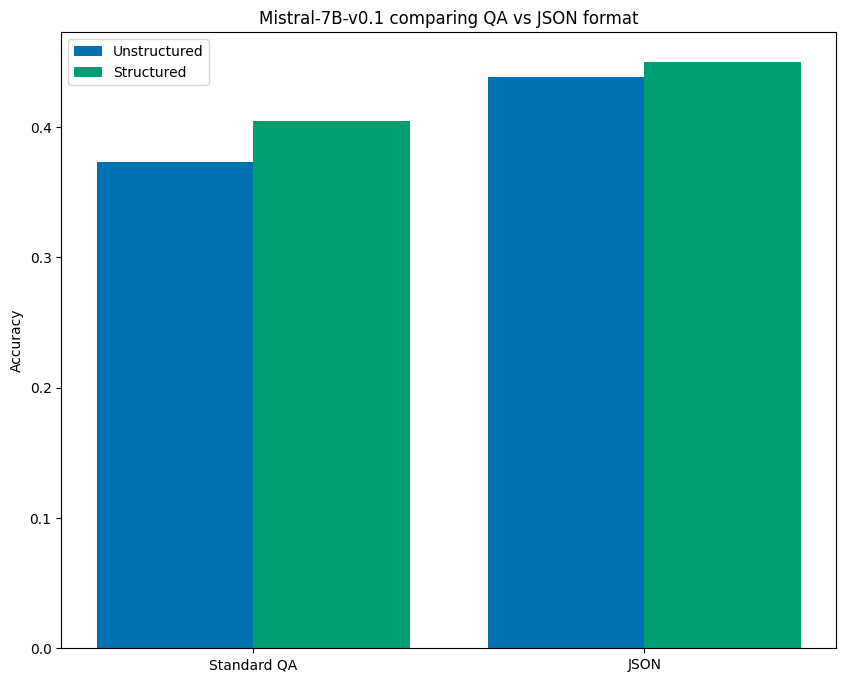
So, even when the format of the prompt is able to dramatically improve benchmark performance, structured generation still leads to additional performance gains.
因此,即使提示的格式能够显著提高基准性能,结构化生成仍然能带来额外的性能提升。
Structured Generation for Prompt Consistency
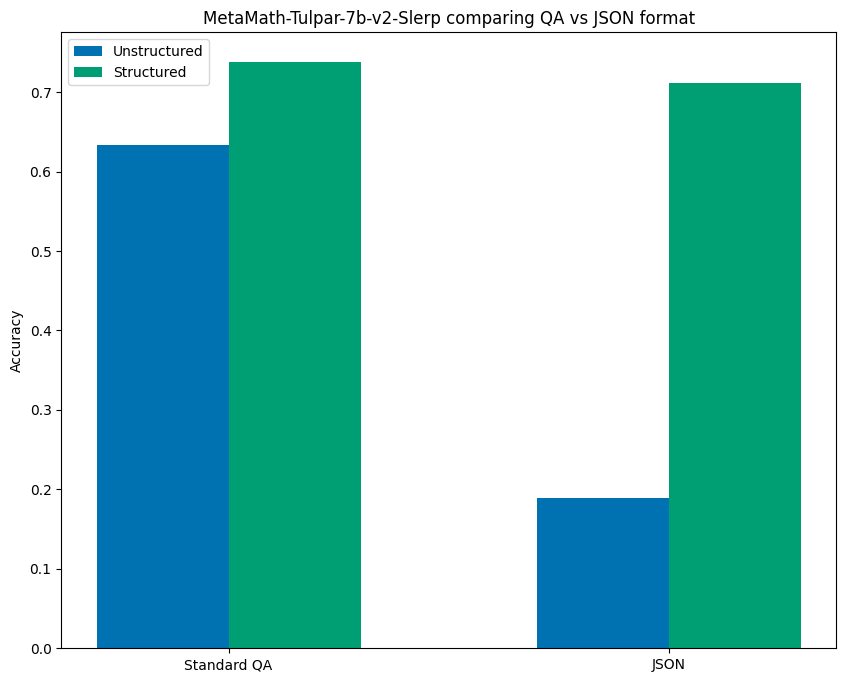
It turns out that not all models followed the above pattern where formatting the prompt as JSON improved unstructured results. MetaMath-Tulpar-7b-v2-Slerp experienced a significant drop in performance when the prompt was changed from the QA format to the JSON one, going from 63.4% accuracy to an abysmal 18.9% when using JSON.
事实证明,并非所有模型都遵循上述模式,即JSON格式的提示能改善非结构化结果。MetaMath-Tulpar-7b-v2-Slerp模型在提示从QA格式改为JSON格式时,性能显著下降,使用JSON时准确率从63.4%骤降至18.9%。
What is interesting is that when using structured generation on both formats, the results were much more consistent, achieving comparable performance of 73.8% and 71.1% accuracy for QA and JSON formats, respectively. The results are visualized below:
有趣的是,当对两种格式都使用结构化生成时,结果的一致性大大提高,QA格式和JSON格式分别达到了73.8%和71.1%的可比准确率。结果如下图所示:
This finding is particularly interesting in light of Sclar, et al.’s paper, Quantifying Language Model’s Sensitivity to Spurious Features in Prompt Design. That paper found that small changes in prompt format can have major impacts on evaluation results. Our findings suggest structured generation might provide a means of ensuring more consistent performance across variations in prompt format. This is an opportunity for future research; a useful experiment would be to revisit Sclar, et al.'s work and use structured generation to see if it consistently reduces variance in evaluation benchmarks across different prompts.
结合Sclar等人的论文《量化语言模型对提示设计中伪特征的敏感性》,这一发现尤为有趣。该论文发现提示格式的微小变化会对评估结果产生重大影响。我们的研究结果表明,结构化生成可能提供一种方法,确保在不同提示格式下性能更加一致。这是未来研究的一个机会;一个有用的实验是重新审视Sclar等人的工作,并使用结构化生成来检验其是否能持续减少不同提示下评估基准的方差。
Thought-Control
The standard prompt for the GSM8K evaluation set involves a reasoning step, which allows the model to “think” before arriving at its final conclusion. Wei, et al. describe this method in their paper Chain-of-Thought Prompting Elicits Reasoning in Large Language Models as “Chain-of-Thought” and demonstrate that it empirically produces better results, specifically using the GSM8K dataset.
GSM8K评估集的标准提示包含一个推理步骤,允许模型在得出最终结论前进行“思考”。Wei等人在其论文《思维链提示激发大语言模型推理》中将此方法描述为“思维链”,并证明其经验上能产生更好的结果,特别是在GSM8K数据集上。
In exploring the performance of different regular expressions, we came across an unexpected, additional benefit of structured generation, which we call “Thought-control”. Thought-control involves limiting the number of characters the model has to “think.” Our current structure allows a minimum of 50 characters and a maximum of 700 characters for the reasoning stage. This configuration was chosen after discovering that even slightly smaller upper bounds, such as 300 and 500, resulted in less improvement (in some cases, no improvement). Early evidence suggests that increasing the lower bound may further improve performance.
在探索不同正则表达式的性能时,我们发现了结构化生成一个意想不到的额外好处,我们称之为“思维控制”。思维控制涉及限制模型用于“思考”的字符数量。 我们当前的结构为推理阶段设定了最少50个字符和最多700个字符的限制。选择此配置是因为我们发现,即使上限稍小(如300和500),带来的改进也较小(在某些情况下没有改进)。早期证据表明,增加下限可能会进一步提高性能。
Future work involves exploring the impact of thought-control on performance in more detail.
未来的工作包括更详细地探索思维控制对性能的影响。
Conclusion
The initial value proposition of structured generation was simply that it allows you to have predictable output when working with LLMs. This is essential if you want to create non-trivial programs that consume LLM output as their input.
结构化生成最初的价值主张很简单:它使你在使用LLM时能够获得可预测的输出。如果你想创建以LLM输出为输入的非平凡程序,这一点至关重要。
Our evaluation of structured generation using GSM8K tells us that even if you don’t care about structured output, you should still use structured generation as it will improve the performance of your models.
我们使用GSM8K对结构化生成的评估表明,即使你不关心结构化输出,你仍然应该使用结构化生成,因为它会提高模型的性能。
Additionally, we’ve found initial evidence that structured generation may offer even more benefits: reduced variance across changes to prompt formats and finer control over the Chain-of-Thought reasoning step.
此外,我们发现了初步证据,表明结构化生成可能带来更多好处:减少因提示格式变化而产生的性能波动,以及对思维链推理步骤更精细的控制。
All of this combined points towards a future where structured generation is an essential part of working with LLMs.
所有这些结合起来都指向一个未来,即结构化生成将成为使用LLM的必要组成部分。
常见问题(FAQ)
结构化生成如何提升LLM在GSM8K基准测试中的性能?
通过强制模型输出遵循GSM8K问题答案的固有结构(如使用正则表达式),结构化生成能确保答案格式正确,减少解析错误,从而在8个不同模型上实现最高超过70%的性能提升。
除了性能提升,结构化生成还有哪些额外优势?
结构化生成带来了“提示一致性”和“思维控制”两大优势。前者确保模型输出格式稳定,后者通过结构引导模型的推理过程,即使在项目不强制要求结构化输出时,这些优势也使其值得采用。
在实验中,结构化生成对哪些模型效果最明显?
实验表明,结构化生成对性能较弱的模型提升尤为显著。例如,在EleutherAI/gpt-j-6b模型上,性能提升超过一倍,尽管其基础分数较低,这凸显了结构化生成对优化模型输出的普适价值。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。