ATLAS自适应学习推测系统如何实现4倍大语言模型推理加速?

AIAI Summary (BLUF)
Together AI推出ATLAS自适应学习推测系统,在运行时动态优化大语言模型推理性能,无需手动调参即可实现高达4倍解码加速。
引言:追求极致的推理性能
在 Together AI,作为一家 AI 原生云服务商,我们对性能有着极致的追求。让大语言模型更快、更便宜、更高效并非一个单一技巧就能解决的问题——它需要在多个维度上进行优化。这正是我们 Together Turbo 套件背后的核心理念,它汇集了我们在算法、架构和模型配方方面的研究成果。我们很高兴推出 自适应学习推测系统,这是首个无需任何手动调优即可实现自动性能提升的推测解码器。
ATLAS 提供了一种全新的推测解码方式——一种在运行时动态改进的方式——并且它能与我们其他的 Turbo 技术(如专有的 Together Turbo Speculator 或 Custom Speculators)无缝集成。但为什么要创建一个自适应学习的推测系统呢?
标准的推测器是为通用工作负载训练的。自定义推测器是针对您的特定数据进行训练的,但仅限于某个特定时间点的数据快照。然而,随着工作负载的演变(代码库增长、流量模式变化、请求分布改变),即使是高度定制的推测器也可能落后。相比之下,ATLAS 会随着使用情况自动进化,从历史模式和实时流量中学习,持续地与目标模型的行为实时对齐。这意味着您使用我们的推理服务越多,ATLAS 的性能就越好!
基于 Together Turbo Speculator 构建的 ATLAS,在完全适应的场景下,在 DeepSeek-V3.1 上可达 500 TPS,在 Kimi-K2 上可达 460 TPS——比标准解码快 2.65 倍,甚至超越了 Groq 等专用硬件(图 1)。

1. 推测解码:加速推理的核心杠杆
推测解码是加速推理最强大的手段之一。它不是让目标模型逐步生成每个令牌,而是由一个更快的 推测器(也称为 草稿模型)提前预测多个令牌,然后目标模型在单个前向传播中并行 验证 这些令牌。验证过程确保输出的质量与非推测解码的分布相匹配,同时通过一次接受多个令牌来实现加速。
整体速度受接受率 $α$(即目标模型同意推测器草拟令牌的频率)以及草稿模型相对于目标模型的相对延迟 $c$ 的影响。通常,参数更多、规模更大的推测器由于其更高的容量而能产生更高的接受率,但生成草稿令牌的速度较慢。因此,进步来自两个方面:对齐草稿模型和目标模型以提高 $α$(训练目标、数据和算法),以及设计在保持 $α$ 的同时降低 $c$ 的草稿模型/内核(稀疏性、量化、轻量级和内核高效架构)。最佳平衡点在于高 $α$ 与低 $c$ 的结合,从而最小化端到端延迟。
在 Together AI,Turbo 团队开发了高性能推测器,通过融合架构、稀疏性、算法、后训练配方和数据方面的进展,在 NVIDIA Blackwell 上实现了 世界最快的解码速度。我们构建了一个 推测器设计与选择框架,用于确定最佳的推测器架构(宽度/深度、前瞻长度、稀疏性/量化、KV 重用),以及一个 可扩展的训练系统,能够快速、可重复地为最大、最具挑战性的开源目标模型(例如 DeepSeek-V3.1 和 Kimi-K2)训练和部署推测器。例如,虽然 Kimi 没有提供现成的推测器,但我们可以快速训练并部署一个,在相同的硬件和批次设置下,将 Kimi 的开箱即用性能从约 150 TPS 提升到 270+ TPS,同时保持目标模型的质量(见图 1,黄色条)。这条流水线为提供最先进解码延迟的 Turbo 推测器提供了动力,并为接下来的发展奠定了基础:一个能够实时适应工作负载的 自适应学习推测系统。
2. Turbo 自适应学习推测系统详解
在 Together AI,我们支持广泛的推理工作负载。但当今的推测解码方法受限于使用在固定数据集上训练的 静态 推测器。一旦部署,推测器就无法适应,如果输入分布发生变化,性能就会下降。这个问题在无服务器、多租户环境中尤为突出,因为输入的多样性极高。新用户不断涌入,并带来独特的、固定推测器在训练期间可能从未见过的工作负载。此外,这些推测器通常使用 固定的前瞻长度,无论推测器的置信度如何,都预测相同数量的令牌。简而言之,静态推测器无法跟上变化。
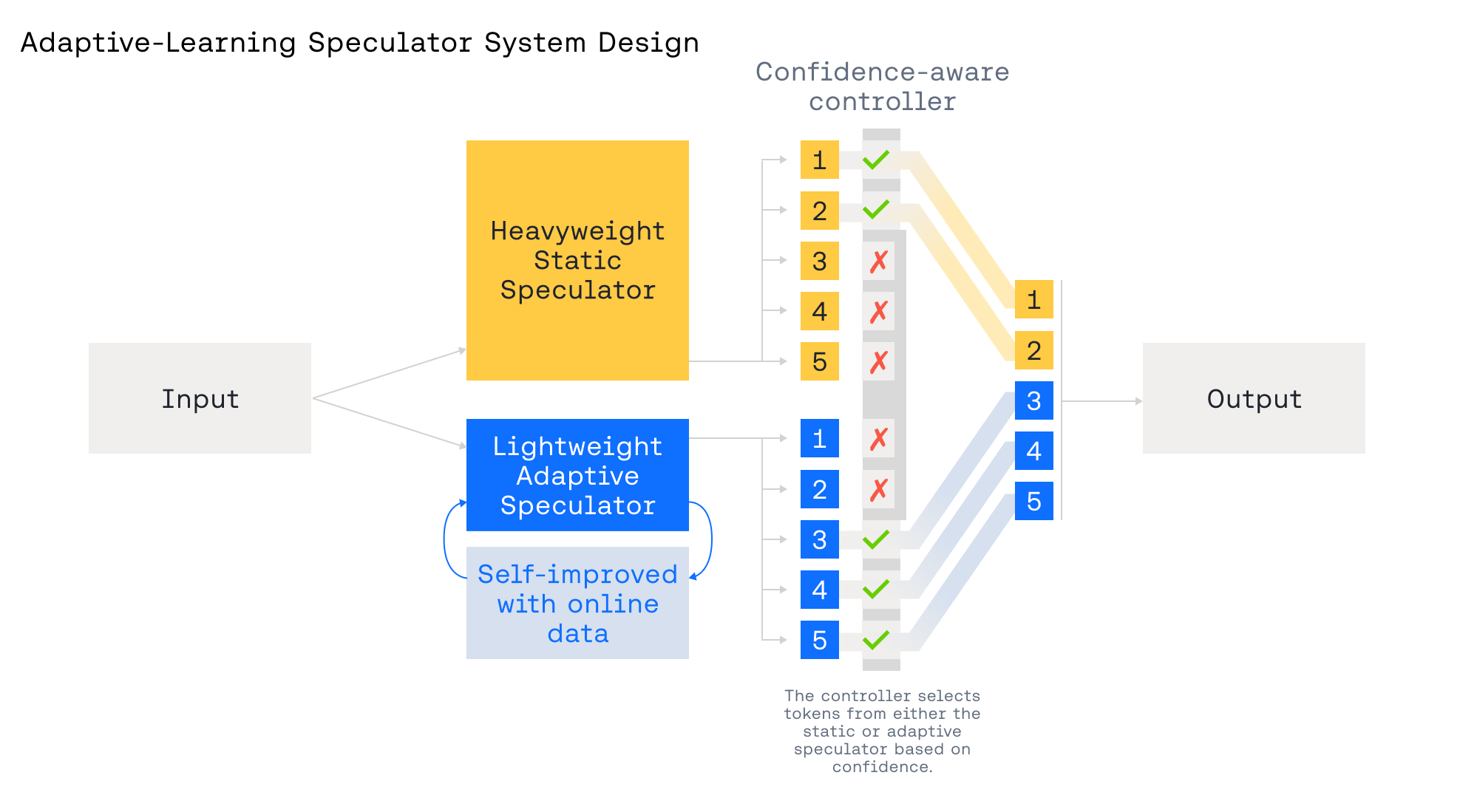
为了应对这些限制,我们设计了 自适应学习推测系统,包含两个协同工作的推测器,如图 3 所示:
- 一个重型的 静态 推测器:在广泛语料库上训练,提供强大、通用的推测能力。
- 一个轻量级的 自适应 推测器:允许根据实时流量进行快速、低开销的更新,即时针对新兴领域进行专业化。
- 一个置信度感知控制器:在每一步选择信任哪个推测器以及使用何种推测前瞻长度,当推测器置信度高时使用更长的前瞻。
通过静态推测器实现效率护栏。静态 Turbo 推测器充当一个始终在线的速度底线:它在广泛语料库上训练,在不同工作负载下保持稳定,因此当流量变化或自适应路径处于冷启动状态时,TPS 不会崩溃。在 ATLAS 中,我们用它来快速启动速度并提供故障安全回退——如果检测到置信度下降或分布漂移,控制器会缩短前瞻长度或切换回静态路径以保持延迟,同时自适应推测器重新学习。
自定义推测器 vs. 自适应学习。我们从之前的研究中了解到,在反映预期使用情况的真实流量样本上训练的 自定义推测器 能带来额外的速度提升。自适应学习推测器使我们能够在实时中实现更深入的定制。例如,在 vibe-coding 会话期间,自适应系统可以为正在编辑且训练期间未见的相关代码文件专门定制一个轻量级推测器,从而进一步提高接受率和解码速度。这种即时专业化是静态推测器难以实现的。
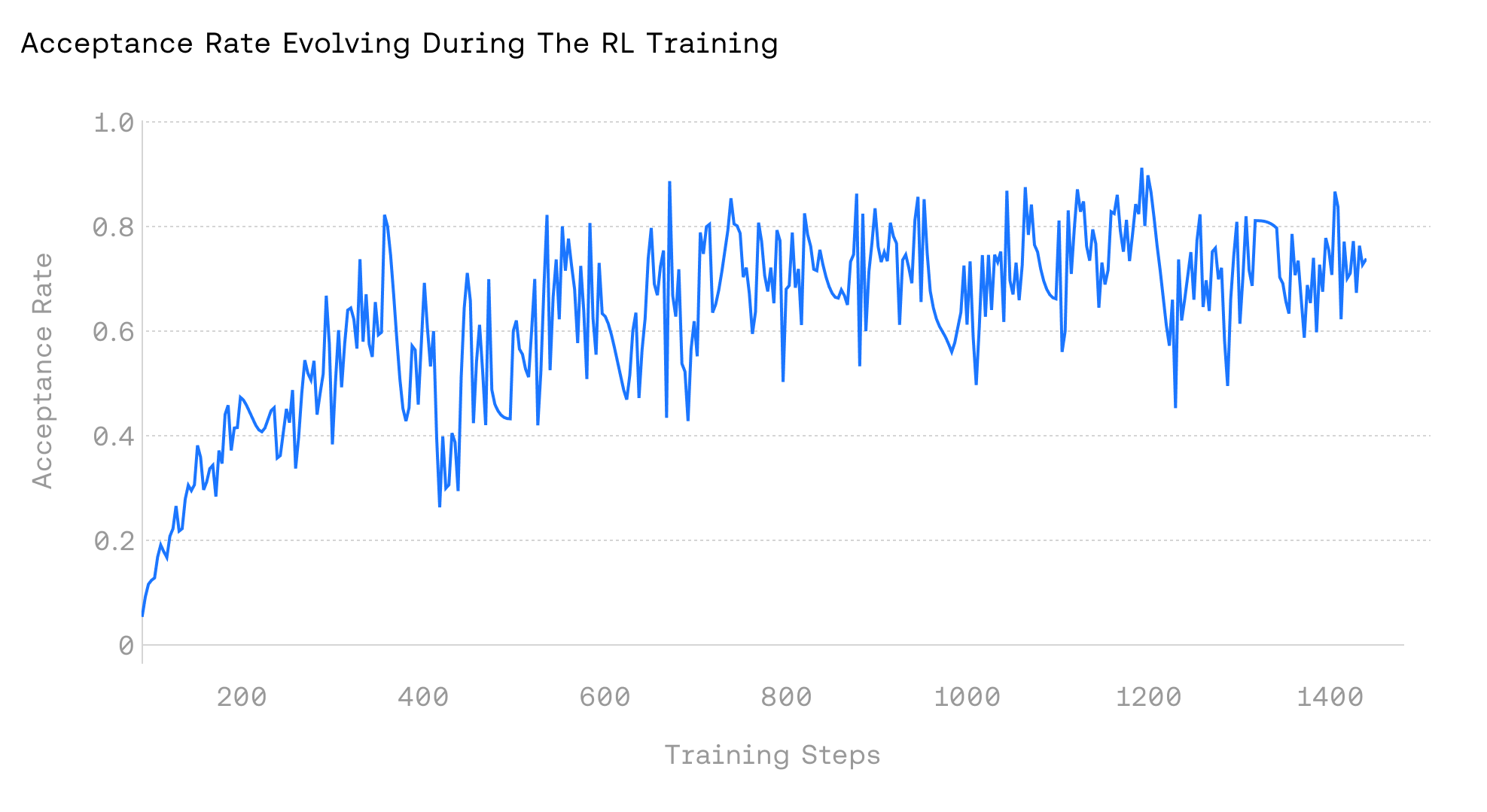
加速强化学习训练。强化学习 (RL) 在两个阶段之间交替:(1) 策略执行阶段,当前策略生成轨迹并获得奖励;(2) 更新阶段,使用奖励更新策略。在实践中,策略执行通常是瓶颈,约占总体挂钟时间的 70%。通常,由于策略分布在训练过程中会发生变化,静态推测器会很快与目标策略失准,导致次优的吞吐量。ATLAS 通过在线适应不断演变的策略和特定的 RL 领域来解决这个问题,保持对齐并减少总体策略执行时间。RL 领域特定、迭代的性质进一步实现了快速适应,产生持续且不断增长的速度提升。如图 4 所示,将 ATLAS 应用于 RL-MATH 流水线,随着训练的进行,速度提升不断增加。
作为 Turbo 优化套件的一部分构建。自适应学习推测系统是更广泛的 Turbo 优化套件的核心组成部分,其中每一层优化都会与其他层产生复合效益。如图 5 所示,通过近乎无损的量化(经过校准以保持质量)、Turbo 推测器,最后是自适应学习推测系统,性能逐步提升。套件中的其他优化还包括用于减少首令牌延迟的 TurboBoost-TTFT(未显示),进一步促进了端到端加速
常见问题(FAQ)
ATLAS自适应学习推测系统是什么?
ATLAS是Together AI推出的自适应学习推测系统,能在运行时动态提升大语言模型推理性能,无需手动调优即可实现高达4倍的解码加速。
ATLAS相比传统推测解码有什么优势?
传统推测器可能因工作负载演变而落后,ATLAS能自动从历史模式和实时流量中学习,持续与目标模型行为对齐,使用越多性能越好。
ATLAS在实际应用中能达到什么效果?
在完全适应场景下,ATLAS在DeepSeek-V3.1上可达500 TPS,在Kimi-K2上可达460 TPS,比标准解码快2.65倍,甚至超越专用硬件。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。



