Databricks收购Lilac后,如何用文本分析工具加速生成式AI开发?

AI Summary (BLUF)
Databricks has acquired Lilac, a scalable tool for exploring and analyzing text datasets, to enhance generative AI application development by simplifying data evaluation and preparation for LLMs.
原文翻译: Databricks收购了Lilac,这是一个用于探索和分析文本数据集的可扩展工具,通过简化LLM的数据评估和准备,增强生成式AI应用程序的开发。
Introduction
Today, we are thrilled to announce that Lilac is joining Databricks. Lilac is a scalable, user-friendly tool for data scientists to search, cluster, and analyze any kind of text dataset with a focus on generative AI. Lilac can be used for a range of use cases — from evaluating the output from large language models (LLMs) to understanding and preparing unstructured datasets for model training. The integration of Lilac's tooling into Databricks will help customers accelerate the development of production-quality generative AI applications using their own enterprise data.
今天,我们非常激动地宣布,Lilac 正式加入 Databricks。Lilac 是一个可扩展、用户友好的工具,旨在帮助数据科学家搜索、聚类和分析任何类型的文本数据集,尤其专注于生成式人工智能。Lilac 可用于多种场景——从评估大型语言模型(LLM)的输出,到理解和准备用于模型训练的非结构化数据集。将 Lilac 的工具集成到 Databricks 平台,将帮助客户利用其自身的企业数据,加速开发生产级的生成式 AI 应用。
Data Exploration and Understanding in the Age of GenAI
Data is at the core of any LLM-based system — whether preparing datasets for training models, evaluating model outputs, or filtering Retrieval-Augmented Generation (RAG) data. Exploring and understanding these datasets is critical for building quality GenAI apps. However, analyzing unstructured text data can become highly cumbersome and extremely difficult in the age of GenAI. Historically, this process has been marred by manual, labor-intensive methods that lack scalability. Not only are these traditional methods time-consuming, but also so daunting that they deter many from attempting them.
数据是任何基于 LLM 的系统的核心——无论是为训练模型准备数据集、评估模型输出,还是筛选用于检索增强生成(RAG)的数据。探索和理解这些数据集对于构建高质量的 GenAI 应用至关重要。然而,在 GenAI 时代,分析非结构化文本数据可能变得非常繁琐且极其困难。从历史上看,这一过程一直受到缺乏可扩展性的、手动且劳动密集型方法的困扰。这些传统方法不仅耗时,而且令人望而生畏,以至于让许多人望而却步。
Introducing Lilac
Core Value Proposition
Lilac, at its essence, makes exploration of unstructured data easy: it is a delightful tool for data scientists and AI researchers to explore, understand, and modify text datasets in a tractable way.
Lilac 的核心价值在于让非结构化数据的探索变得简单:它是一个出色的工具,能让数据科学家和 AI 研究人员以一种易于处理的方式探索、理解和修改文本数据集。
Key Innovations and Capabilities
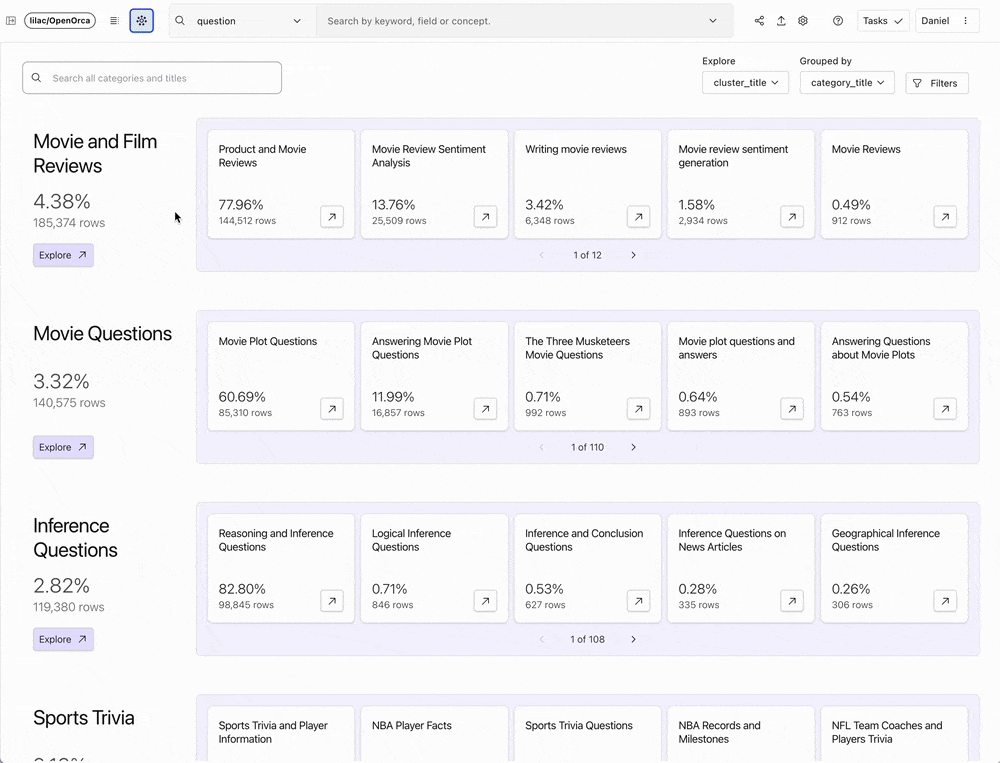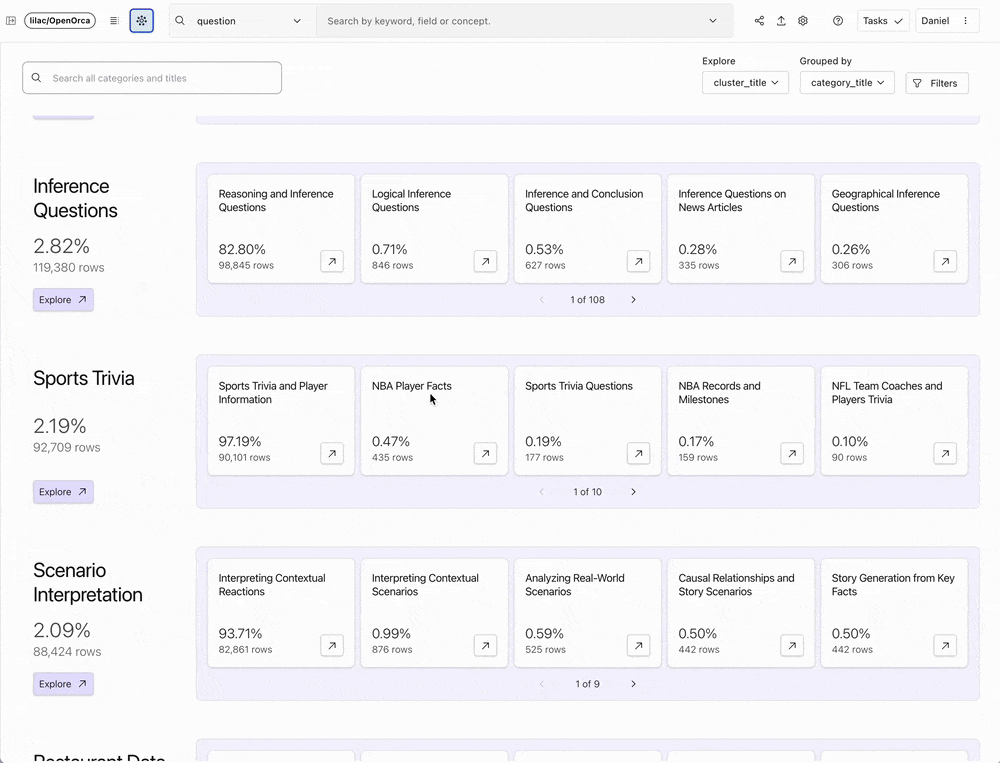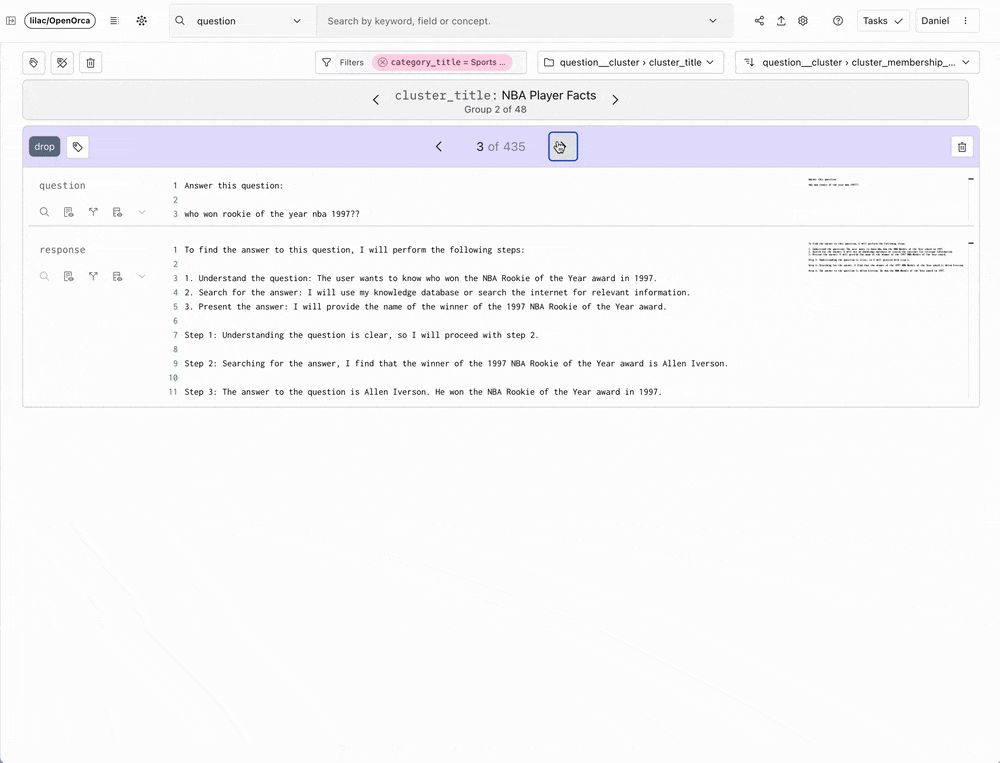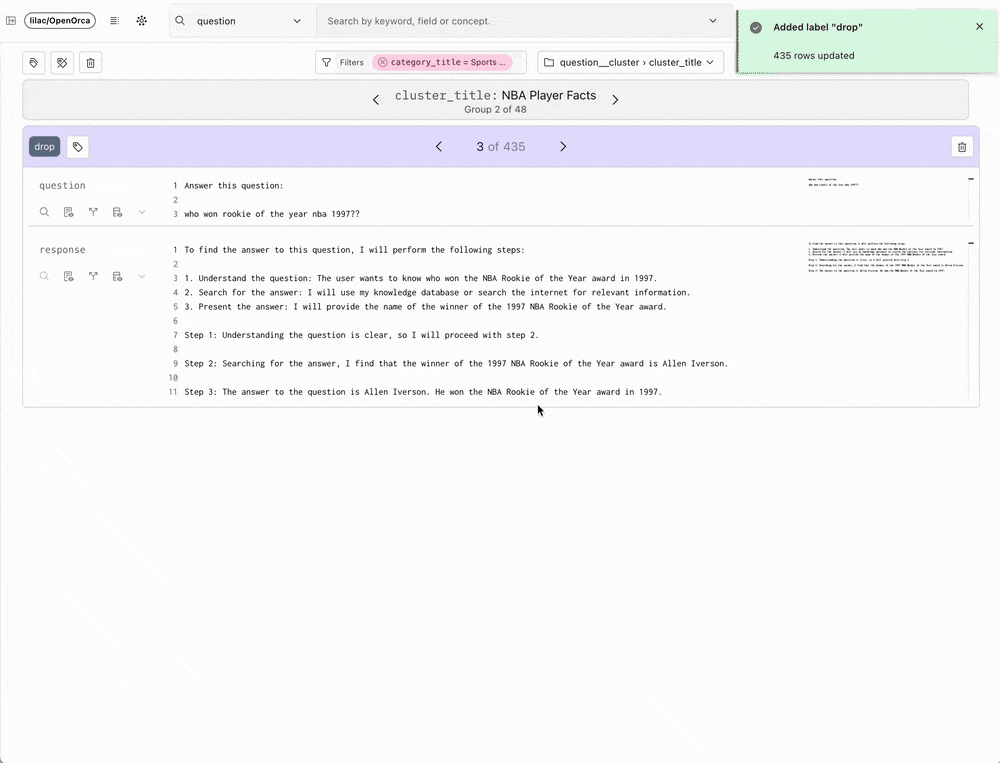
Lilac has innovated in this space by offering a scalable solution that encourages and facilitates interaction with data. With an incredibly intuitive user interface and AI-augmented features, Lilac empowers data scientists and researchers to explore data clusters, derive new data categories using human feedback and classifiers, and tailor datasets based on these insights. The team behind Lilac specifically built their product to enable analysis of model outputs for bias or toxicity, and preparation of data for RAG and fine-tuning or pre-training LLMs.
Lilac 在这一领域进行了创新,提供了一个可扩展的解决方案,鼓励并促进与数据的交互。凭借极其直观的用户界面和 AI 增强功能,Lilac 使数据科学家和研究人员能够探索数据聚类、利用人工反馈和分类器推导新的数据类别,并根据这些洞察定制数据集。Lilac 背后的团队专门构建了他们的产品,以实现对模型输出的偏见或毒性分析,并为 RAG、LLM 微调或预训练准备数据。
Strategic Alignment and Team Expertise
Lilac's core mission aligns with Databricks' commitment to provide customers with end-to-end GenAI capabilities. Their open source project has already captivated a wide audience within the data science and AI research communities — including our own Mosaic AI team, which has been leveraging Lilac to curate data over the past year. Lilac's founders, Daniel Smilkov and Nikhil Thorat, each spent a decade at Google honing their expertise in developing enterprise-scale data quality solutions. We are thrilled to bring their experience, team, and technology to Databricks.
Lilac 的核心使命与 Databricks 为客户提供端到端 GenAI 能力的承诺高度契合。他们的开源项目已经吸引了数据科学和 AI 研究社区的广泛关注——包括我们自己的 Mosaic AI 团队,该团队在过去一年中一直在利用 Lilac 来管理数据。Lilac 的联合创始人 Daniel Smilkov 和 Nikhil Thorat 均在 Google 工作了十年,磨练了他们在开发企业级数据质量解决方案方面的专业知识。我们非常高兴能将他们的经验、团队和技术引入 Databricks。
Looking Ahead: Lilac and Databricks
With Databricks Mosaic AI, our goal is to provide customers with end-to-end tooling to develop high-quality GenAI apps using their own data. Lilac’s technology will make it easier to evaluate and monitor the outputs of their LLMs in a unified platform, as well as prepare datasets for RAG, fine-tuning, and pre-training. We look forward to sharing more as we integrate Lilac’s technology into Databricks. Stay tuned!
通过 Databricks Mosaic AI,我们的目标是为客户提供端到端的工具链,让他们能够利用自己的数据开发高质量的 GenAI 应用。Lilac 的技术将使其更容易在统一平台上评估和监控其 LLM 的输出,并为 RAG、微调和预训练准备数据集。我们期待在将 Lilac 技术集成到 Databricks 的过程中分享更多信息。敬请关注!
Explore more about building GenAI apps with Databricks by viewing our on-demand webinar The GenAI Payoff in 2024.
通过观看我们的点播网络研讨会 2024 年 GenAI 的回报,了解更多关于使用 Databricks 构建 GenAI 应用的信息。
常见问题(FAQ)
Databricks收购Lilac对生成式AI开发有什么帮助?
Lilac是一个用于探索和分析文本数据集的可扩展工具,集成到Databricks后能简化LLM的数据评估和准备,帮助客户利用企业数据加速开发生产级生成式AI应用。
Lilac在数据探索方面有哪些核心功能?
Lilac提供直观界面和AI增强功能,支持搜索、聚类、分析文本数据,能评估模型输出的偏见/毒性,并为RAG、LLM微调或预训练准备数据,让非结构化数据探索变得简单高效。
为什么Lilac适合集成到Databricks平台?
Lilac的使命与Databricks提供端到端GenAI能力的承诺高度契合,其创始团队拥有十年企业级数据质量解决方案经验,开源项目已被Mosaic AI团队用于数据管理,技术互补性强。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。