DeepSeek-V3真的能以1/11算力成本媲美GPT-4吗?(附技术解析)

引言
中国AI初创公司深度求索(DeepSeek)近日宣布,其训练的DeepSeek-V3混合专家(Mixture-of-Experts, MoE)大语言模型,在性能上可媲美OpenAI、Meta和Anthropic等巨头的领先模型,但训练所需的GPU算力成本仅为后者的1/11。这一声明虽有待全面验证,但其揭示的趋势令人瞩目:在美国制裁限制中国获取先进AI硬件的背景下,中国的研究人员正通过算法与工程优化,从有限的硬件资源中榨取极致性能,以应对芯片供应受限的挑战。该公司已开源模型及权重,预计相关测试结果将很快涌现。
Chinese AI startup DeepSeek recently announced that its trained DeepSeek-V3 Mixture-of-Experts (MoE) large language model can rival the performance of leading models from giants like OpenAI, Meta, and Anthropic, while requiring only 1/11th of the GPU computing power and cost for training. Although this claim awaits full validation, the trend it reveals is remarkable: against the backdrop of U.S. sanctions limiting China's access to advanced AI hardware, Chinese researchers are extracting maximum performance from limited hardware resources through algorithmic and engineering optimizations to cope with the challenge of restricted chip supply. The company has open-sourced the model and weights, and relevant test results are expected to emerge soon.
核心训练数据与效率对比
根据深度求索发布的技术论文,DeepSeek-V3是一个拥有6710亿参数的MoE模型。其训练仅耗时两个月,使用了一个包含2048颗英伟达H800 GPU的集群,总计消耗约280万GPU小时。
According to the technical paper released by DeepSeek, DeepSeek-V3 is a MoE model with 671 billion parameters. Its training took only two months, utilizing a cluster containing 2,048 Nvidia H800 GPUs, totaling approximately 2.8 million GPU hours.
作为对比,Meta训练其4050亿参数的Llama 3模型,动用了包含16,384颗H100 GPU的集群,历时54天,总计消耗了约3080万GPU小时(根据Andrej Karpathy的推文数据计算)。这意味着,在参数量更大的情况下,DeepSeek-V3的训练算力消耗仅为Llama 3的约1/11。
For comparison, Meta trained its 405-billion-parameter Llama 3 model using a cluster of 16,384 H100 GPUs over 54 days, consuming approximately 30.8 million GPU hours (calculated based on data from Andrej Karpathy's tweet). This indicates that, despite having more parameters, the computational cost for training DeepSeek-V3 was only about 1/11th that of Llama 3.
为了更清晰地展示效率差异,我们将关键训练指标对比如下:
| 指标 | DeepSeek-V3 | Meta Llama 3 405B | 效率比 (V3 / Llama 3) |
|---|---|---|---|
| 参数量 | 671B | 405B | ~1.66倍 |
| 核心GPU型号 | Nvidia H800 | Nvidia H100 | - |
| GPU数量 | 2,048 | 16,384 | 1/8 |
| 训练时长 | ~2个月 | ~54天 | 相近 |
| 总GPU小时 | ~2.8M | ~30.8M | ~1/11 |
性能表现
根据深度求索公布的基准测试结果,DeepSeek-V3在多项标准评测中表现优异。下图展示了DeepSeek-V3与其他代表性聊天模型的对比(所有模型评估均限制输出长度为8K。样本数少于1000的基准测试通过多次不同温度设置运行以获得稳健结果)。
According to the benchmark results released by DeepSeek, DeepSeek-V3 performs excellently in multiple standard evaluations. The figure below shows a comparison between DeepSeek-V3 and other representative chat models (all models are evaluated with output length limited to 8K. Benchmarks with fewer than 1000 samples are run multiple times with varying temperature settings to obtain robust results).
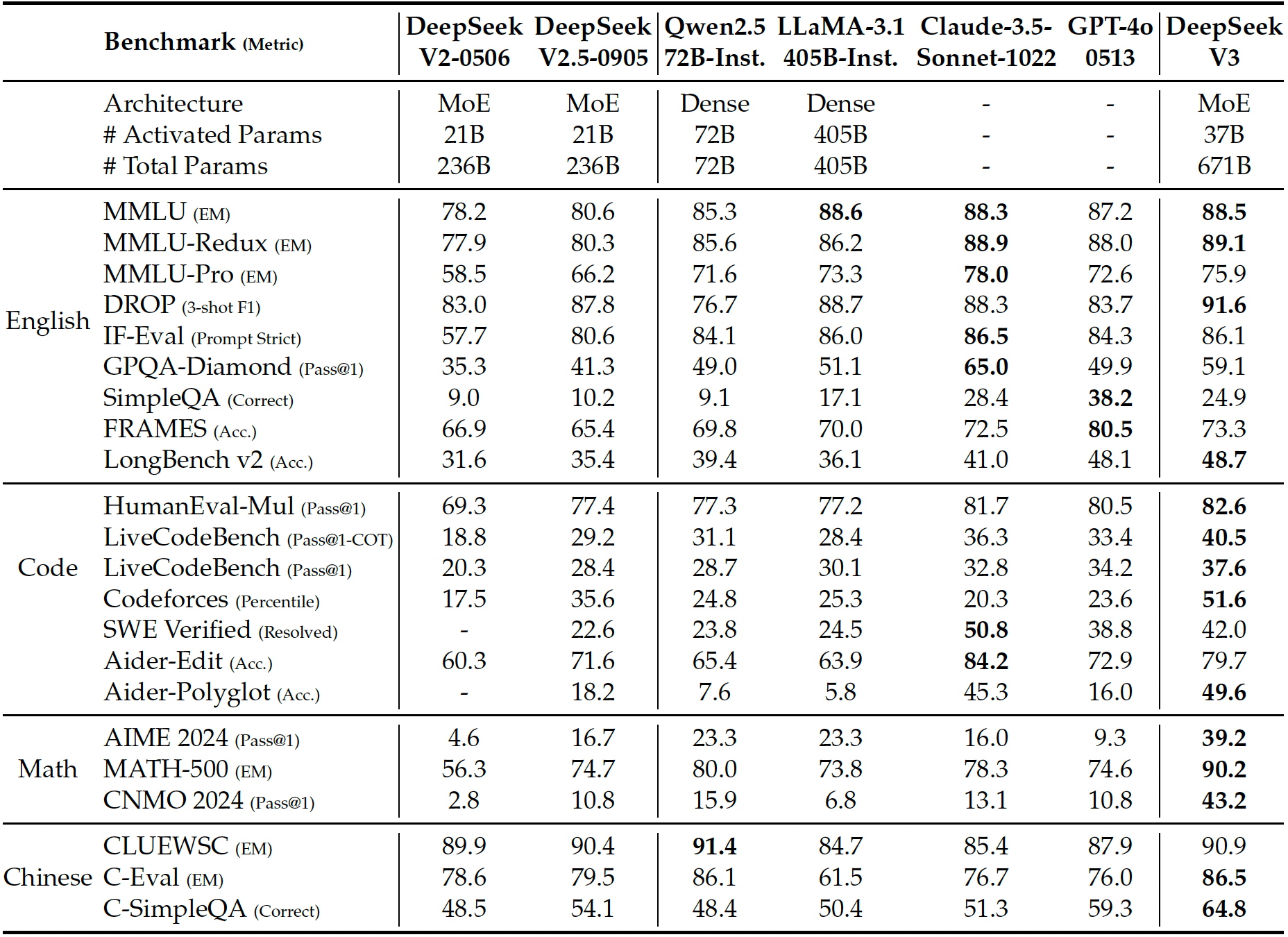
(图片来源: DeepSeek)
报告指出,DeepSeek-V3是目前性能最佳的开源模型,同时在与前沿闭源模型的竞争中展现了强大的竞争力。
The report indicates that DeepSeek-V3 is currently the best-performing open-source model and also demonstrates strong competitiveness against frontier closed-source models.
技术意义与局限性
尽管在参数量或复杂推理能力上,DeepSeek-V3可能仍稍逊于GPT-4o或o3等最前沿模型,但其成就表明,利用相对有限的资源训练出先进的MoE大语言模型是可行的。这背后必然需要大量的系统优化、底层编程和算法创新。
Although DeepSeek-V3 may still slightly lag behind the most frontier models like GPT-4o or o3 in terms of parameter count or complex reasoning capabilities, its achievement demonstrates that it is feasible to train an advanced MoE large language model with relatively limited resources. This undoubtedly requires extensive system optimization, low-level programming, and algorithmic innovation.
深度求索团队也坦诚地指出了DeepSeek-V3在部署层面的挑战。部署该模型需要先进的硬件支持,以及将预填充(prefilling)和解码(decoding)阶段分离的部署策略,这对于资源有限的小型团队而言可能难以实现。
The DeepSeek team also candidly pointed out the deployment challenges of DeepSeek-V3. Deploying this model requires advanced hardware support and a deployment strategy that separates the prefilling and decoding stages, which may be difficult for small teams with limited resources.
“在肯定其强大性能和成本效益的同时,我们也认识到DeepSeek-V3存在一些局限性,尤其是在部署方面,” 公司的论文中写道。“首先,为确保推理效率,DeepSeek-V3推荐的部署单元相对较大,这可能给小型团队带来负担。其次,尽管我们为DeepSeek-V3设计的部署策略已实现端到端生成速度超过DeepSeek-V2的两倍,但仍有进一步提升的潜力。幸运的是,随着更先进硬件的发展,这些局限性有望得到自然解决。”
"While acknowledging its strong performance and cost-effectiveness, we also recognize that DeepSeek-V3 has some limitations, especially in deployment," the company's paper states. "Firstly, to ensure inference efficiency, the recommended deployment unit for DeepSeek-V3 is relatively large, which might pose a burden for small-sized teams. Secondly, although our deployment strategy for DeepSeek-V3 has achieved an end-to-end generation speed more than twice that of DeepSeek-V2, there remains potential for further enhancement. Fortunately, these limitations are expected to be naturally addressed with the development of more advanced hardware."
结论
DeepSeek-V3的出现,不仅展示了一款具有竞争力的开源大模型,更重要的是,它为大模型训练的“效率竞赛”树立了一个新的标杆。在算力日益成为AI发展核心瓶颈的当下,通过软件和算法优化来大幅降低训练成本,具有重要的战略和商业价值。其开源策略也将加速社区验证与技术扩散。尽管面临部署挑战,但DeepSeek-V3所代表的“高效训练”路径,无疑为全球AI研发,特别是在算力受限环境下的创新,提供了新的思路与可能性。
The emergence of DeepSeek-V3 not only showcases a competitive open-source large model but, more importantly, sets a new benchmark for the "efficiency race" in large model training. At a time when computing power is increasingly becoming a core bottleneck in AI development, significantly reducing training costs through software and algorithmic optimizations holds significant strategic and commercial value. Its open-source strategy will also accelerate community validation and technology diffusion. Despite facing deployment challenges, the "efficient training" path represented by DeepSeek-V3 undoubtedly provides new ideas and possibilities for global AI R&D, especially for innovation in computing-power-constrained environments.
常见问题(FAQ)
DeepSeek-V3相比其他大模型在训练成本上有多大优势?
根据技术论文对比,DeepSeek-V3训练仅消耗约280万GPU小时,而Meta Llama 3 405B模型消耗约3080万GPU小时,前者训练算力成本仅为后者的约1/11。
DeepSeek-V3在硬件受限背景下如何实现高效训练?
在美国制裁限制先进AI硬件的背景下,中国研究人员通过算法与工程优化,从2048颗H800 GPU的有限资源中榨取极致性能,仅用两个月完成6710亿参数模型的训练。
DeepSeek-V3的实际性能表现如何?
基准测试显示,DeepSeek-V3是目前性能最佳的开源模型,在多项标准评测中表现优异,与前沿闭源模型相比也展现出强大的竞争力。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。