RAG检索增强生成如何解决AI大模型知识过时问题?

AIAI Summary (BLUF)
检索增强生成(RAG)是一种AI架构,通过连接外部知识源增强大语言模型,无需昂贵重训即可生成准确、实时且可追溯的响应。该技术利用实时信息检索,有效解决模型知识过时与幻觉问题。
“检索增强生成(RAG)是一种实用的方法,通过使企业数据和信息可用于大语言模型(LLM)处理,来克服通用大语言模型的局限性。” – Gartner 关于 RAG 的论述
尽管大语言模型(LLM)功能强大,但其知识在训练完成时便已固化。它们无法访问企业专有数据、最新发展动态或驱动现实世界决策所需的、具有细微差别的特定领域上下文。
RAG 通过将知识存储与模型本身分离来解决这一问题。它在生成响应前的关键时刻获取正确的信息,并将其注入模型的上下文窗口。其结果是构建出一个有据可依、与时俱进且可审计的 AI 系统。
“RAG 允许 LLM 访问和引用其自身训练数据之外的信息。这使得 LLM 无需大量微调或训练即可产生高度具体的输出,以远低于定制 LLM 的成本获得其部分优势。” – 麦肯锡关于 RAG 功能的解释
RAG 概念由 Patrick Lewis 等人在 2020 年的一篇研究论文中提出,现已成为企业软件中增长最快的 AI 架构模式之一。该论文将 RAG 称为“通用微调配方”,因为它可以将 LLM 连接到任何外部知识库,以产生更相关、可验证的响应。

图注:基础 RAG 的构成。来源:Forrester
九种 RAG 技术类型是什么?
随着 RAG 技术的成熟,一系列不同的模式已经出现,每种模式适用于不同复杂程度和用例需求:
- 朴素或标准 RAG:基础模式,文档被分块、嵌入、存储在向量数据库中,并通过相似性搜索进行检索。实现简单,但推理能力有限,在大规模应用时易受上下文腐化和幻觉影响。

图注:朴素 RAG 的构成。来源:Markovate - 高级 RAG:在朴素 RAG 基础上构建,增加了检索前优化(查询重写、路由)和检索后步骤(重排序、压缩、过滤),以提高相关性和输出质量。目前大多数生产级 RAG 系统属于此类。
- 模块化 RAG:一种灵活、可组合的流水线,其中检索器、重排序器、生成器、验证器等独立组件可以独立交换或扩展。这种方法适用于构建大规模、多领域的 AI 系统的团队。
- GraphRAG:使用知识图谱或上下文图作为主要检索层,而非扁平的向量存储。GraphRAG 支持跨实体和关系的多跳推理,在处理复杂分析性问题时表现显著更优。微软的 GraphRAG 研究是该模式大规模应用的突出例子。
- 上下文图与本体驱动 RAG:在 GraphRAG 基础上扩展,将操作元数据、血缘关系、质量指标、时间上下文和治理策略叠加到知识图谱上。这使得检索到的上下文在关系上更丰富,在操作上更可信。
- 上下文工程化 RAG:将焦点从检索算法转移到上下文在检索上游如何准备及在何处准备。关键技术包括多阶段检索流水线(在主 LLM 调用前进行查询理解、图过滤、向量搜索和摘要),以及尊重语义边界、标题、表格和决策点的丰富分块策略,而非应用统一的固定大小窗口。
- RAFT:一种混合模式,将微调与 RAG 结合,训练模型以特定领域的方式对检索到的文档进行推理。RAFT 既获得了微调在风格和行为上的优势,又保留了检索的知识新鲜度和可审计性。
- 自反思 RAG 与纠正性 RAG:在这些模式中,模型评估自身的检索结果和输出,当证据薄弱或答案缺乏置信度时重新查询,从而在高风险领域中大幅减少幻觉。
- 智能体化 RAG:RAG 嵌入在多智能体系统中,由专门的智能体并行处理查询分解、检索、验证和合成。这是为 2026 年企业 AI 智能体出现的主导模式。

图注:智能体化 RAG 的构成。来源:Daily Dose of Data Science
RAG 的主要用例有哪些?
RAG 几乎适用于所有需要 LLM 基于特定、最新或专有信息回答问题的领域:
- 企业知识管理:从政策文件、HR 手册、操作手册和内部维基中回答员工问题。
- 客户支持:为聊天机器人和虚拟助手提供动力,从产品文档、常见问题解答和案例历史中获取信息。
- 数据与分析问答:通过从数据目录或语义层检索上下文,帮助分析师查询指标、定义和仪表板。
- 法律与合规:从法规文件、合同和政策框架中综合答案,并提供完整引用。
- 金融研究:从财报电话会议、分析师报告和市场数据中提取见解,并提供可追溯的来源。
- 医疗保健与生命科学:检索临床指南、试验数据和医学文献,以支持护理团队的决策。
RAG 的最大优势是什么?
与单独使用 LLM 或仅依赖微调进行领域适应相比,RAG 带来了可衡量的业务和技术优势:
- 减少幻觉:通过将生成过程锚定在检索到的证据上,RAG 显著降低了捏造输出的比率。
- 成本低于微调:微调大型模型需要大量计算资源,并且每次知识更新都需要重新训练周期。RAG 将知识与模型权重分离,这意味着知识库的更新不需要重新训练。
- 输出始终最新:因为 RAG 在推理时从实时知识源(如企业上下文层)检索,所以响应能反映当前的政策、指标和文档。
- 可审计性与可信度:每个 RAG 响应都可以追溯到特定的源文档或数据资产,为合规、法律和治理团队提供了可验证的证据链。
- 更快实现价值:团队可以通过整理知识库来构建特定领域的 AI 应用,而无需数月的微调基础设施或大量的机器学习开销。
RAG 的核心组件是什么?
一个生产级的 RAG 系统由多个相互连接的组件组成,每个组件在端到端流水线中承担不同的功能。
知识索引
知识索引是任何 RAG 系统的基础。它是检索器在查询时从中提取相关内容的结构化存储库。索引的质量直接决定了模型能够检索到什么,进而决定了它能够生成什么。
一个设计良好的知识索引包括:
- 文档语料库:原始源材料,包括 PDF、Confluence 页面、数据库记录、API 响应和结构化表格。
- 分块策略:将长文档分割成可检索片段的方法,需要在粒度和连贯性之间取得平衡。
- 嵌入向量:每个分块的向量表示,由嵌入模型生成,用于捕获语义含义以进行相似性搜索。
- 元数据:附加到每个分块的所有权、数据域、敏感度分类、创建日期和血缘信息,支持过滤和受控的检索。
对于企业部署,当知识索引由提供语义丰富、访问控制的元数据(而不仅仅是原始文档)的治理上下文层支持时,其功能最为强大。
生成器
生成器是产生最终响应的大语言模型。它接收一个提示,该提示包含原始用户查询加上经过筛选的检索上下文,并将其综合成一个连贯、可引用的答案。
现代 RAG 架构使用生成器进行查询重写、自我评估和纠正性重新检索。
RAG 如何工作?架构与工作流概述
高层架构概览
从高层来看,RAG 系统在两个不同的阶段运行:离线索引阶段(准备知识库)和在线推理阶段(实时回答查询)。
索引阶段是文档被摄取、分块、嵌入并与丰富的元数据一起存储在向量或混合索引中的阶段。此阶段的质量决定了一切后续步骤。像 Atlan 的元数据湖仓这样的平台,可以作为上下文丰富的知识存储,供索引流水线从中提取数据,它不仅提供原始文档,还提供经过丰富、治理、语义链接的元数据,这使得检索的精确度显著提高。
推理阶段是用户查询触发检索、重排序和生成依次进行的阶段。每个步骤都依赖于前一步骤的质量,这就是为什么在索引阶段进行上下文工程已成为 2026 年 RAG 优化的主要焦点。
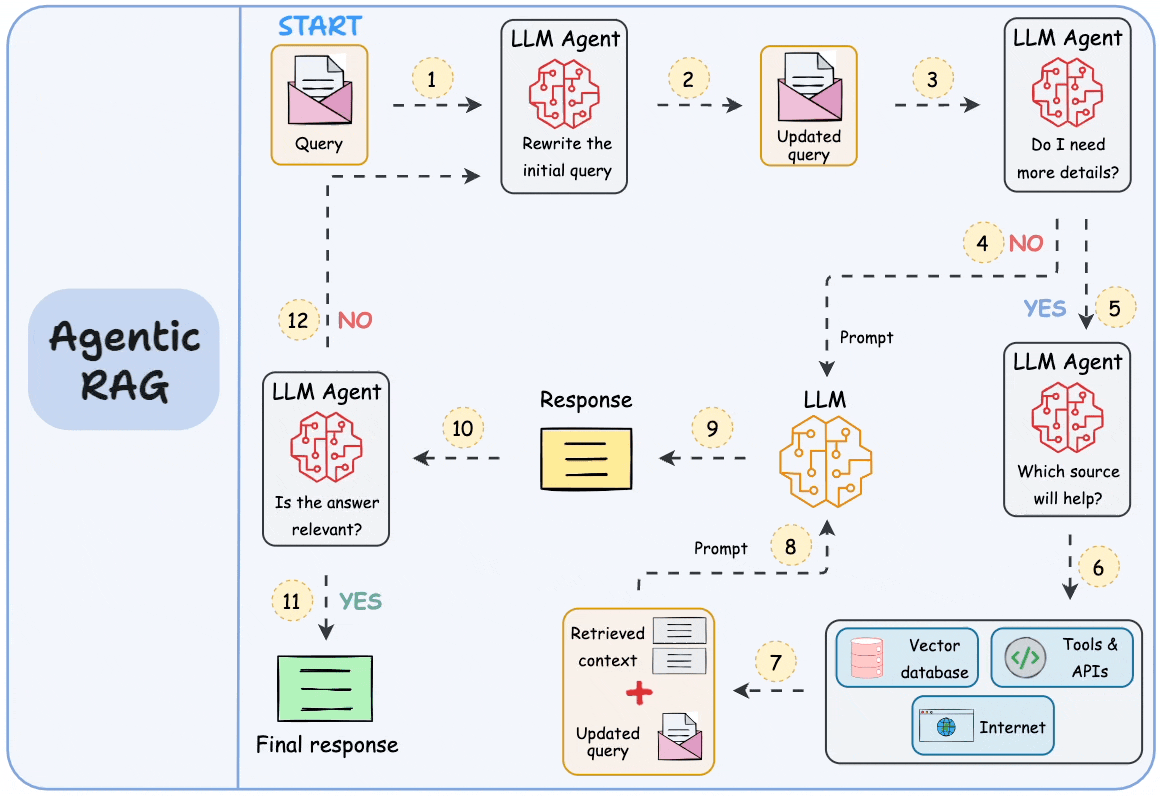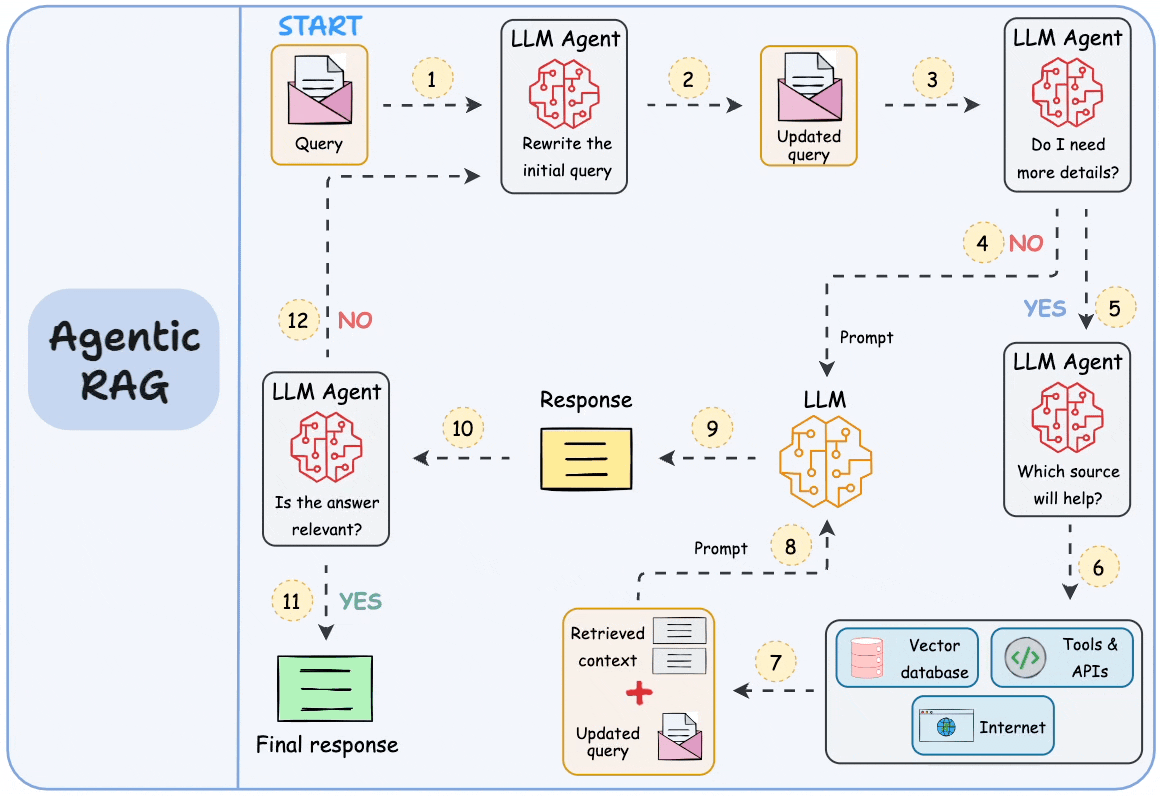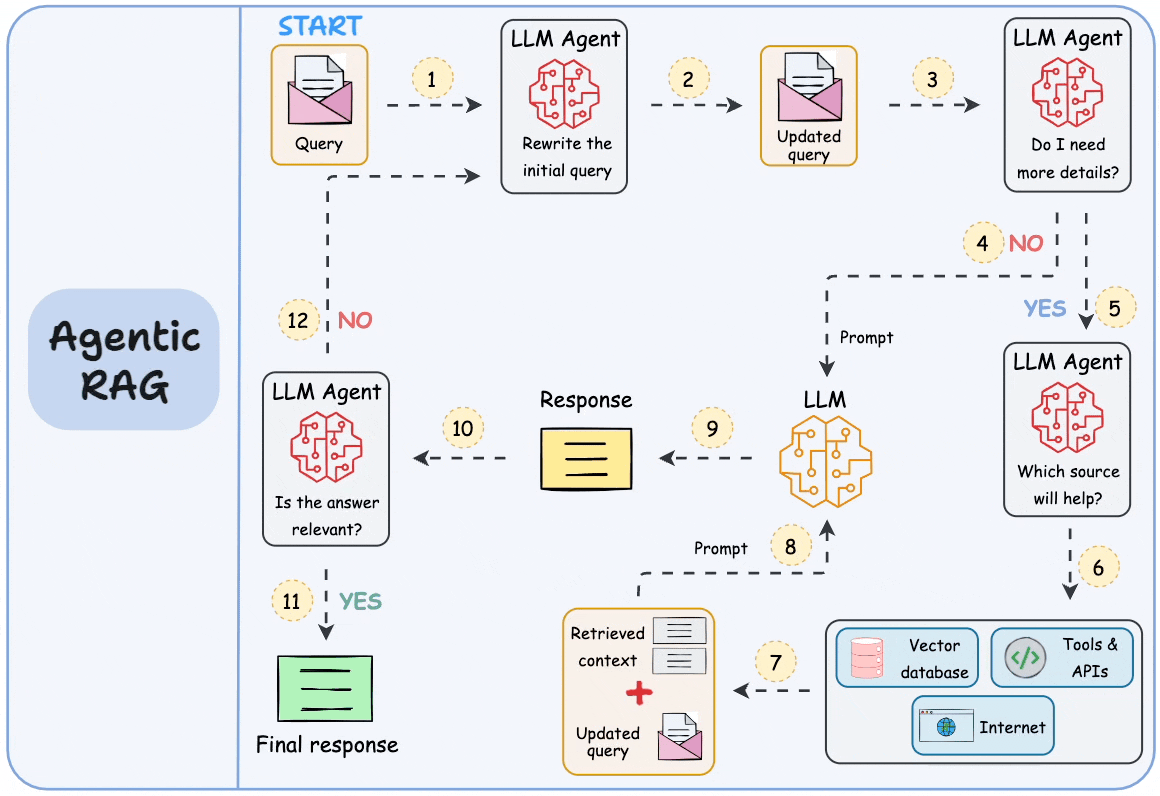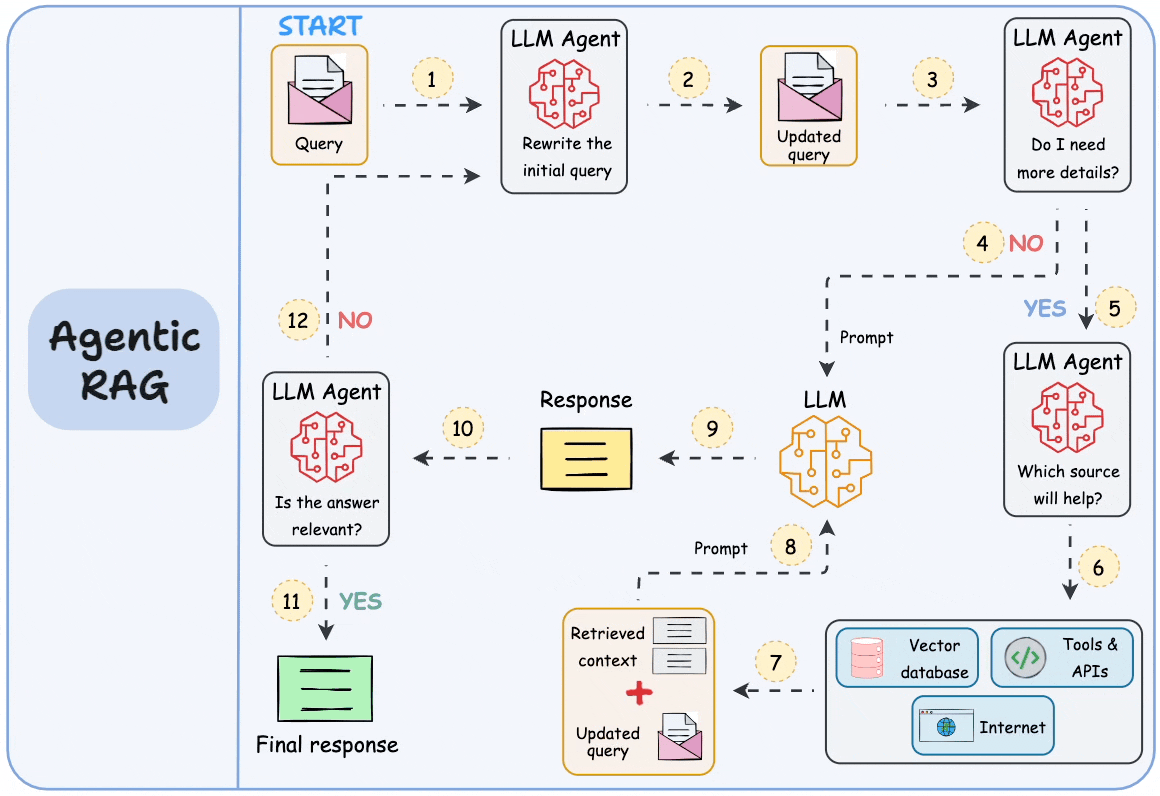
逐步工作流
以下是完整的 RAG 请求在系统中流动的过程:
常见问题(FAQ)
RAG的主要优势是什么?
RAG的主要优势在于无需昂贵地重新训练大语言模型,即可通过连接外部知识源,生成准确、最新且可审计的响应,有效解决LLM知识过时和幻觉问题。
RAG的核心组件有哪些?
RAG的核心组件包括知识索引(用于存储和检索外部信息)和生成器(即大语言模型),两者协同工作,在生成响应前将检索到的信息注入模型上下文。
RAG有哪些主要的技术类型?
主要技术类型包括朴素RAG(基础模式)、高级RAG(增加检索前后优化步骤)和模块化RAG(灵活可组合的流水线),适用于不同复杂度的用例需求。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。




{kind=link}