如何提升LLM数学推理?2026年RFT拒绝采样微调深度解析

AIAI Summary (BLUF)
本文解析拒绝采样微调(RFT)方法,用于提升大语言模型数学推理能力。流程为:小模型生成多样推理路径,经质量与多样性筛选后,微调大模型(如Llama2-70B)。关键发现:RFT通过增加训练数据中独特推理路径的多样性,显著优于标准监督微调(SFT),尤其对弱模型提升明显。
扩展大语言模型的数学推理能力:深入解析拒绝采样微调 (RFT)
Introduction
引言
大语言模型(LLMs)已在多个领域展现出卓越的能力,但数学推理仍然是一个重大挑战。传统方法如监督微调(SFT)和上下文学习(ICL)已显示出潜力,但常常遇到性能瓶颈。本文深入探讨了论文《Scaling Relationship on Learning Mathematical Reasoning with Large Language Models》中详述的一种新颖方法,该方法引入了拒绝采样微调(RFT),以显著提升大语言模型的数学问题解决能力。
RFT 的核心思想是利用模型自身生成多样化且正确的推理路径,然后将其用作增强数据集进行进一步的微调。事实证明,这种方法对于改进性能较弱的模型特别有效,并且与大规模预训练相比,提供了一条计算效率更高的性能提升路径。
Key Concepts: RFT vs. SFT
核心概念:RFT 与 SFT
在深入探讨方法之前,理解 RFT 与传统 SFT 方法之间的区别至关重要。
What is SFT (Supervised Fine-Tuning)?
什么是监督微调 (SFT)?
监督微调是一种标准的微调方法,其中预训练模型在针对特定任务(例如,带有思维链步骤的数学推理)的高质量人工标注数据集上进行进一步训练。
Main Steps:
主要步骤:
- 数据收集:收集大量标注示例
(问题, 推理路径, 答案)。 - 模型训练:在此数据集上对预训练模型进行微调。
- 评估与优化:在验证集上评估性能并进行迭代。
优点: 简单直接。
局限性: 严重依赖昂贵的人工标注的质量和数量;随着基础模型的改进,性能提升可能会减弱。
What is RFT (Rejection Sampling Fine-Tuning)?
什么是拒绝采样微调 (RFT)?
RFT 是一种更复杂、自我改进的微调方法。 它使用一个初始经过 SFT 训练的模型为自身生成新的训练数据,侧重于多样性和正确性。
Main Steps:
主要步骤:
- 数据生成:使用 SFT 模型为每个训练问题生成多个候选推理路径。
- 筛选过程:过滤这些候选路径,仅保留能推导出正确答案的路径。
- 多样性控制:从正确的路径中进一步选择,以确保多样化的推理策略(例如,不同的方程式、计算顺序)。
- 模型训练:使用这个新的增强数据集
D'对原始模型(或更大的模型)进行微调。
关键区别: 筛选和多样化步骤是 RFT 的核心。它能够从模型自身的输出中自动创建高质量、多样化的训练数据。
Core Methodology: Enhancing Models with RFT
核心方法:使用 RFT 增强模型
该论文的主要贡献是一个可扩展的 RFT 框架,它能有效地结合多个较小模型的输出来训练一个更大的模型。整体工作流程如下图所示:
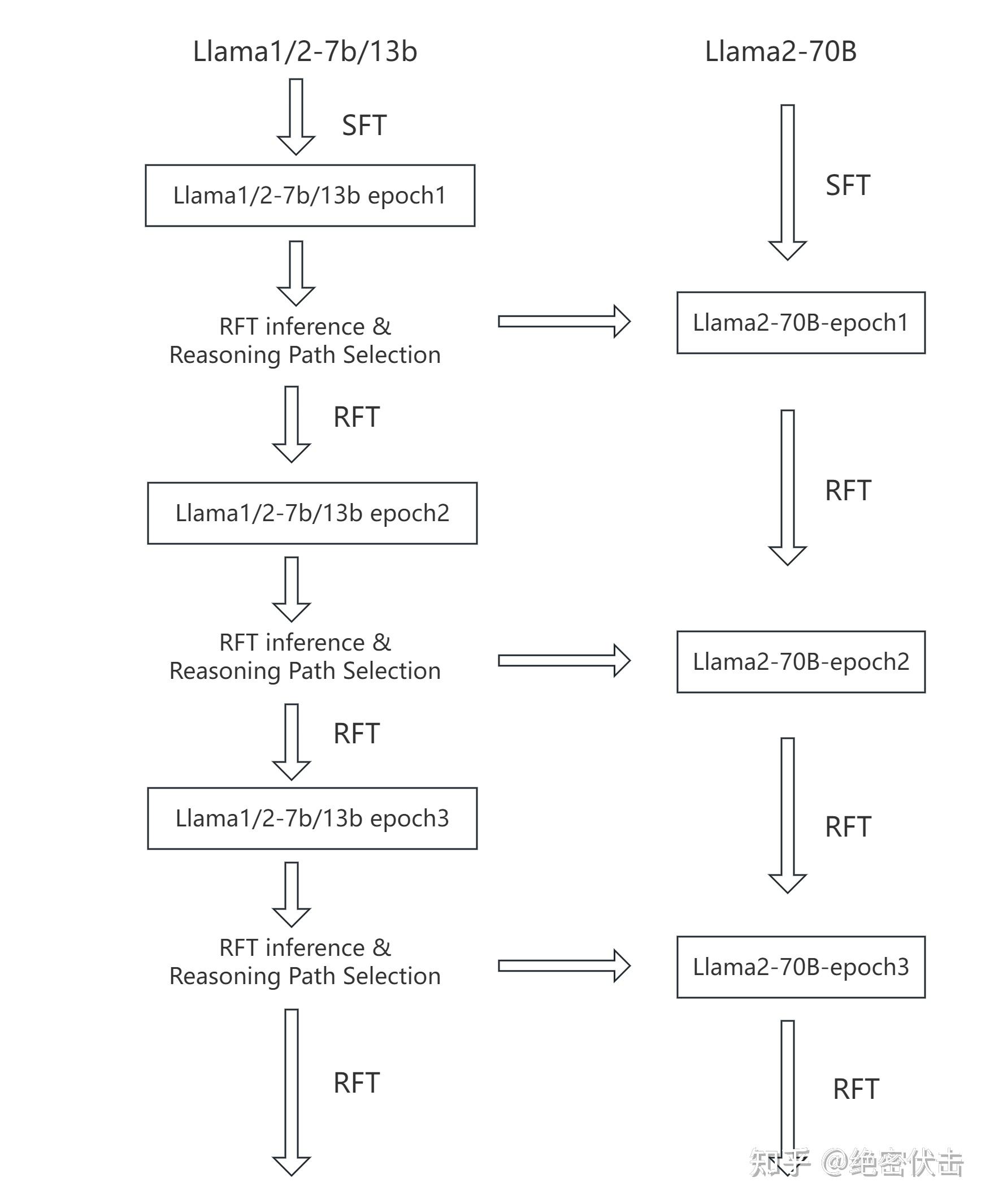
整体策略: 使用多个较小模型(例如 Llama1/2-7B/13B)生成推理路径。经过严格的质量和多样性筛选后,这些路径用于对更大模型(Llama2-70B)进行监督微调 (SFT)。
Detailed Steps:
详细步骤:
- 初始 SFT 轮次:使用原始数据集
(q_i, a_i)(例如 GSM8K)对小型和大型基础模型进行一轮训练。 - 推理路径选择(RFT 的核心):使用较小模型为每个问题
q_i生成多个推理路径r_ij。应用两阶段筛选:- 质量筛选:仅保留能得出正确答案的路径。
- 多样性控制:选择展现不同计算过程或方程序列的路径,以最大化多样性。由此创建一个新的、丰富的数据集
R^s。
- 使用新数据微调:使用新数据集
R^s对小模型进行另一轮微调,随后用它来微调大型 Llama2-70B 模型。 - 迭代:重复步骤 2 和 3 进行多轮,以持续改进数据集和模型性能。
The Crucial Step: Diversity-Driven Path Selection
关键步骤:基于多样性的路径选择
路径选择的目的是从给定的一组推理路径中选择具有不同计算过程的路径,从而增强模型在训练期间的泛化能力。该算法优先考虑方程式的多样性。

Process Summary:
流程摘要:
- 对于每个问题
q,维护一个列表R_q^s用于存放选中的路径,以及一个集合E_q^s用于存放来自选中路径的唯一方程式。 - 遍历问题
q的所有候选路径r。 - 从路径
r中提取方程式集合e。 - 如果
e是新的(不在E_q^s中),则将r添加到R_q^s,并将e添加到E_q^s。 - 如果
e已存在,算法可能会用r替换现有路径,前提是r比它要替换的路径更能增加整体多样性(基于相似性度量l)。
Example (from Figure 2):
示例(来自图2):
- 已选路径:
R_q^s = [r_1, r_2, r_3, r_4] - 现有方程式集合:
E_q^s = {2x+y=5, 3x+2y=6} - 当前候选路径
r的方程式为{3x+2y=6}(与路径r_2, r_3, r_4相同)。 - 如果
r与r_2和r_3的差异度大于r_4与它们的差异度(即l(r, r_2) + l(r, r_3) > l(r_4, r_2) + l(r_4, r_3)),则用r替换r_4。
Key Findings and Results
主要发现与结果
该论文提出了令人信服的证据,证明了所提出的 RFT 框架的有效性。
1. Superior Diversity Generation from Model Ensembles
1. 模型集成能产生更优的多样性
- 较小模型的组合集成(Llama1/2-7B/13B)在每个模型采样 100 条路径 (
k=100) 时,每个问题能生成 12.84 条独特的推理路径(经过筛选后)。 - 相比之下,单个 7B 模型仅生成 5.25 条独特路径,而 33B 模型仅生成 2.78 条。
结论: 结合多个较小模型是生成多样化推理路径集的一种非常有效的策略。有趣的是,对于此任务,较小模型通常能比大模型产生更多样化的输出。
2. Significant Performance Improvements
2. 显著的性能提升
使用 RFT 生成的数据进行微调,在 GSM8K 基准测试中带来了显著的准确率提升:
- Llama-7B:准确率从 35.9%(SFT 基线)提升至 49.1%(+13.2%)。
- Llama-33B:准确率从 54.6% 提升至 57.9%(+3.3%)。
备注: 对于较弱的基础模型(如 7B),改进更为明显。更强的 33B 模型已经具备相当的推理能力,在像 GSM8K 这样的数据集上改进空间较小。在更具挑战性的数据集上,提升可能会更大。
3. Scaling Relationships: The Drivers of Performance
3. 扩展关系:性能的驱动因素
该论文确定了支配大语言模型在数学推理中性能的基本扩展定律:
预训练损失是关键预测指标:在不同的模型架构和规模中,较低的预训练损失与较高的 SFT 和 ICL 准确率密切相关。改进基础预训练模型是根本。
SFT 随数据量呈对数线性扩展:模型准确率随监督数据量的增加呈对数增长。然而,对于更好的预训练模型,增加更多数据带来的益处会减弱。
RFT 随独特推理路径数量扩展:RFT 的性能直接与其增强数据集中独特推理路径的数量相关。这可以通过采样更多路径 (
k) 或结合多个模型的输出来有效增加。
Conclusion and Implications
结论与启示
RFT 框架为推进大语言模型的数学推理能力提供了一个强大而高效的范式。通过将模型转变为自身高质量、多样化训练数据的生成器,它绕过了人工标注的瓶颈。利用较小、运行成本较低的模型集成来为更大模型创建数据的策略尤其具有洞察力,在计算成本和最终性能之间提供了有利的权衡。
Key Takeaways:
关键要点:
- 多样性至关重要:对于推理任务,让模型接触多种有效的解决策略与向它展示正确答案同样重要
常见问题(FAQ)
RFT方法相比传统的SFT微调,主要优势是什么?
RFT的核心优势在于能自动生成多样化且正确的推理路径作为训练数据,显著提升模型准确率,尤其对较弱模型效果更明显,且计算效率高于大规模预训练。
RFT方法中的关键筛选步骤是如何操作的?
RFT首先用SFT模型生成多个候选推理路径,然后筛选出能得出正确答案的路径,并进一步控制多样性,确保选择不同推理策略的路径用于微调。
为什么RFT能有效提升大语言模型的数学推理能力?
RFT通过增加训练数据中独特推理路径的多样性,使模型学习到更丰富的解题思路,从而突破传统SFT的性能瓶颈,实现数学推理能力的显著提升。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。



