RAG检索增强生成如何解决AI大模型知识过时问题?

Retrieval Augmented Generation (RAG) is an AI architecture that enhances large language models by connecting them to external knowledge sources, enabling accurate, up-to-date, and auditable responses without costly retraining. It addresses LLM limitations like outdated knowledge and hallucinations through real-time information retrieval.
原文翻译: 检索增强生成(RAG)是一种AI架构,通过将大型语言模型连接到外部知识源来增强其能力,无需昂贵的重新训练即可生成准确、最新且可审计的响应。它通过实时信息检索解决了LLM知识过时和幻觉等局限性。
What exactly is RAG? An overview of its popularity, types, uses, and benefits
“检索增强生成(RAG)是一种实用的方法,通过使企业数据和信息可用于大语言模型(LLM)处理,来克服通用大语言模型的局限性。” – Gartner 关于 RAG 的论述
“Retrieval augmented generation (RAG) is a practical way to overcome the limitations of general large language models (LLMs) by making enterprise data and information available for LLM processing.” – Gartner on RAG
尽管大语言模型(LLM)功能强大,但其知识在训练完成时便已固化。它们无法访问企业专有数据、最新发展动态或驱动现实世界决策所需的、具有细微差别的特定领域上下文。
While LLMs are powerful, their knowledge is frozen at the point of training. They can’t access proprietary enterprise data, recent developments, or the nuanced domain-specific context that drive real-world decisions.
RAG 通过将知识存储与模型本身分离来解决这一问题。它在生成响应前的关键时刻获取正确的信息,并将其注入模型的上下文窗口。其结果是构建出一个有据可依、与时俱进且可审计的 AI 系统。
RAG solves this by separating the knowledge store from the model itself. It gets the right information at the right moment and injects it into the model’s context window before generating a response. The result is an AI system that is grounded, current, and auditable.
“RAG 允许 LLM 访问和引用其自身训练数据之外的信息。这使得 LLM 无需大量微调或训练即可产生高度具体的输出,以远低于定制 LLM 的成本获得其部分优势。” – 麦肯锡关于 RAG 功能的解释
“RAG allows LLMs to access and reference information outside the LLMs own training data. This enables LLMs to produce highly specific outputs without extensive fine-tuning or training, delivering some of the benefits of a custom LLM at considerably less expense.” – McKinsey on what RAG does
RAG 概念由 Patrick Lewis 等人在 2020 年的一篇研究论文中提出,现已成为企业软件中增长最快的 AI 架构模式之一。该论文将 RAG 称为“通用微调配方”,因为它可以将 LLM 连接到任何外部知识库,以产生更相关、可验证的响应。
Coined in 2020 by a research paper from Patrick Lewis, RAG has become one of the fastest-growing AI architectural patterns in enterprise software. The paper calls RAG a “general-purpose fine-tuning recipe” as it can connect LLMs to any external knowledge repository for producing more relevant, verified responses.

图注:基础 RAG 的构成。来源:Forrester
Caption: The anatomy of basic RAG. Source: Forrester
九种 RAG 技术类型是什么?
What are the nine types of RAG techniques?
随着 RAG 技术的成熟,一系列不同的模式已经出现,每种模式适用于不同复杂程度和用例需求:
As RAG has matured, a family of distinct patterns has emerged, each suited to different levels of complexity and use case requirements:
- 朴素或标准 RAG:基础模式,文档被分块、嵌入、存储在向量数据库中,并通过相似性搜索进行检索。实现简单,但推理能力有限,在大规模应用时易受上下文腐化和幻觉影响。
Naive or standard RAG: The foundational pattern where documents are chunked, embedded, stored in a vector database, and retrieved by similarity search. Simple to implement but limited in reasoning capability and vulnerable to context rot and hallucinations at scale.

图注:朴素 RAG 的构成。来源:Markovate
Caption: The anatomy of Naive RAG. Source: Markovate - 高级 RAG:在朴素 RAG 基础上构建,增加了检索前优化(查询重写、路由)和检索后步骤(重排序、压缩、过滤),以提高相关性和输出质量。目前大多数生产级 RAG 系统属于此类。
Advanced RAG: Builds on naive RAG with pre-retrieval optimization (query rewriting, routing) and post-retrieval steps (reranking, compression, filtering) to improve relevance and output quality. Most production RAG systems today fall into this category.
- 模块化 RAG:一种灵活、可组合的流水线,其中检索器、重排序器、生成器、验证器等独立组件可以独立交换或扩展。这种方法适用于构建大规模、多领域的 AI 系统的团队。
Modular RAG: A flexible, composable pipeline where individual components such as retrievers, re-rankers, generators, and validators can be swapped or extended independently. This approach works for teams building large-scale, multi-domain AI systems.
- GraphRAG:使用知识图谱或上下文图作为主要检索层,而非扁平的向量存储。GraphRAG 支持跨实体和关系的多跳推理,在处理复杂分析性问题时表现显著更优。微软的 GraphRAG 研究是该模式大规模应用的突出例子。
GraphRAG: Uses knowledge graphs or context graphs as the primary retrieval layer instead of flat vector stores. GraphRAG enables multi-hop reasoning across entities and relationships, delivering significantly better performance on complex analytical questions. Microsoft’s GraphRAG research is a prominent example of this pattern applied at scale.
- 上下文图与本体驱动 RAG:在 GraphRAG 基础上扩展,将操作元数据、血缘关系、质量指标、时间上下文和治理策略叠加到知识图谱上。这使得检索到的上下文在关系上更丰富,在操作上更可信。
Context-graph and ontology-driven RAG: Extends GraphRAG by layering operational metadata, lineage, quality metrics, temporal context, and governance policies onto the knowledge graph. This makes retrieved context relationally rich and operationally trustworthy.
- 上下文工程化 RAG:将焦点从检索算法转移到上下文在检索上游如何准备及在何处准备。关键技术包括多阶段检索流水线(在主 LLM 调用前进行查询理解、图过滤、向量搜索和摘要),以及尊重语义边界、标题、表格和决策点的丰富分块策略,而非应用统一的固定大小窗口。
Context-engineered RAG: Shifts focus from retrieval algorithms to how and where context is prepared upstream of retrieval. Key techniques include multi-stage retrieval pipelines (query understanding, graph filters, vector search, and summarization before the main LLM call), and rich chunking strategies that respect semantic boundaries, headers, tables, and decision points rather than applying uniform fixed-size windows.
- RAFT:一种混合模式,将微调与 RAG 结合,训练模型以特定领域的方式对检索到的文档进行推理。RAFT 既获得了微调在风格和行为上的优势,又保留了检索的知识新鲜度和可审计性。
RAFT (retrieval-augmented fine-tuning): A hybrid pattern that combines fine-tuning with RAG, training the model to reason over retrieved documents in a domain-specific way. RAFT captures the style and behavioral benefits of fine-tuning while retaining the knowledge freshness and auditability of retrieval.
- 自反思 RAG 与纠正性 RAG:在这些模式中,模型评估自身的检索结果和输出,当证据薄弱或答案缺乏置信度时重新查询,从而在高风险领域中大幅减少幻觉。
Self-reflective RAG and corrective RAG: Patterns where the model evaluates its own retrievals and outputs, re-querying when evidence is weak or answers lack confidence, substantially reducing hallucinations in high-stakes domains.
- 智能体化 RAG:RAG 嵌入在多智能体系统中,由专门的智能体并行处理查询分解、检索、验证和合成。这是为 2026 年企业 AI 智能体出现的主导模式。
Agentic RAG: RAG embedded inside multi-agent systems, where specialized agents handle query decomposition, retrieval, validation, and synthesis in parallel. This is the dominant pattern emerging for enterprise AI agents in 2026.

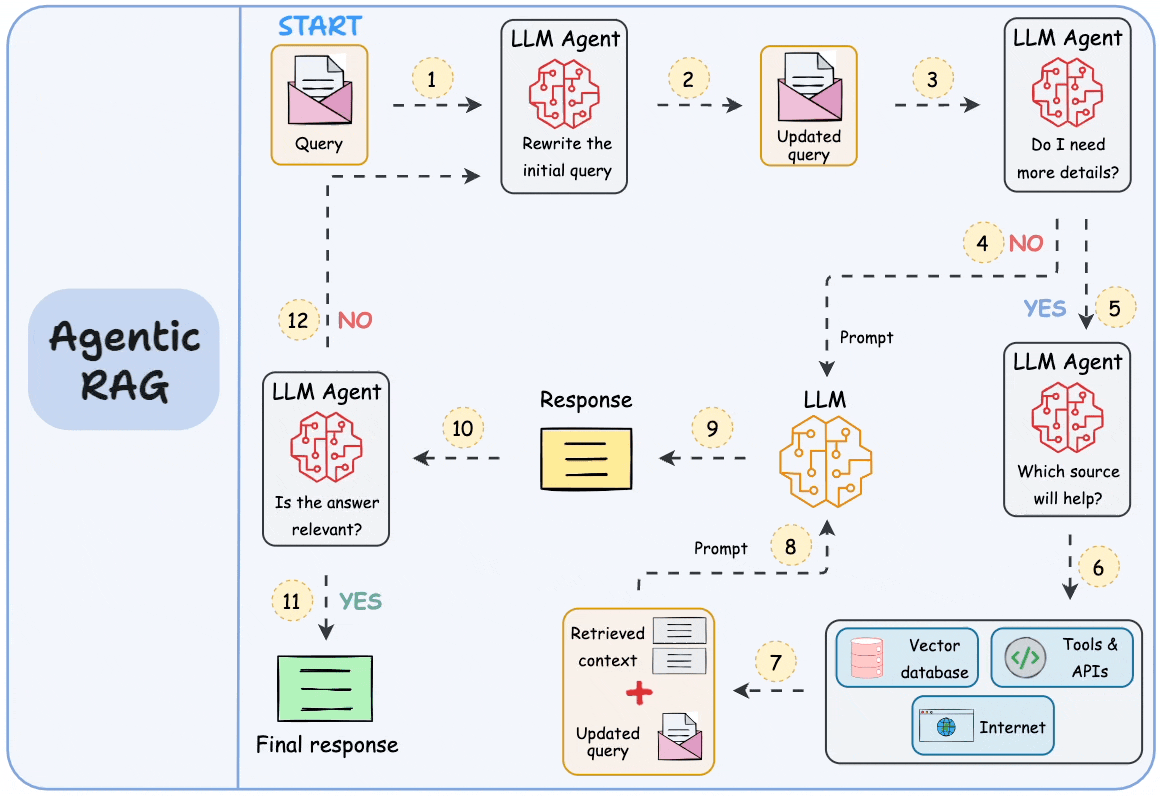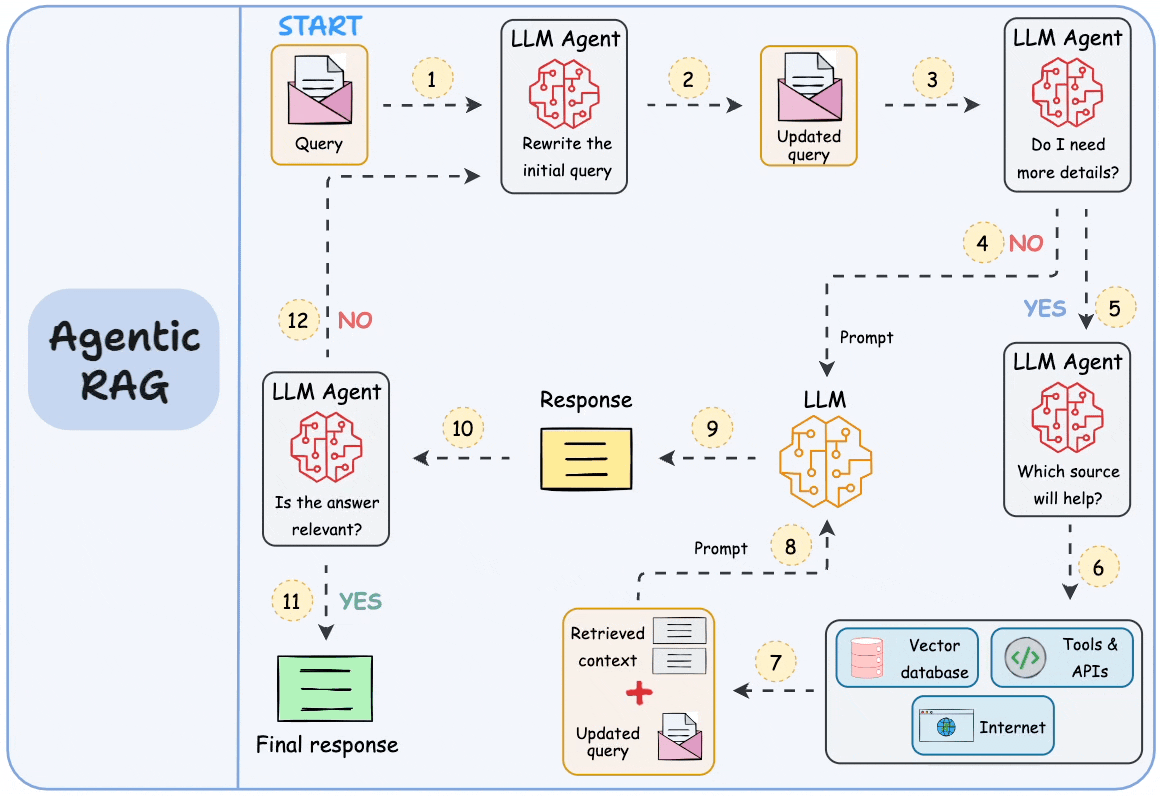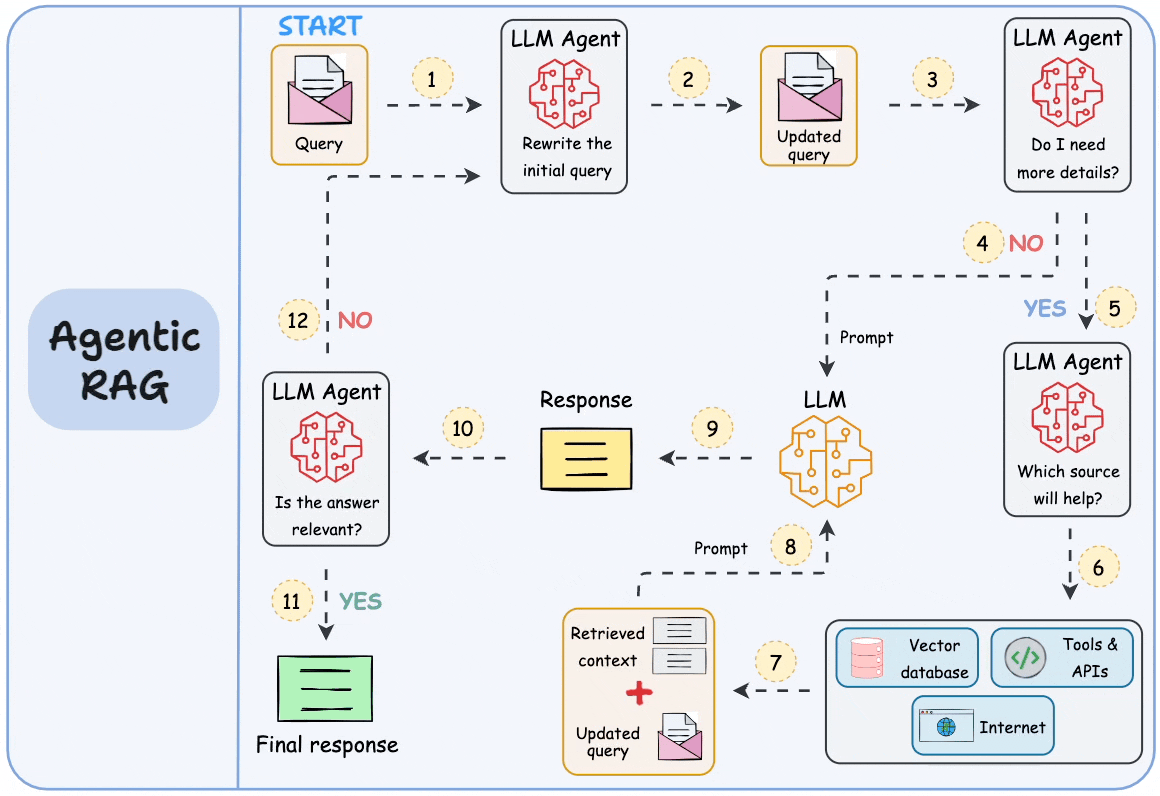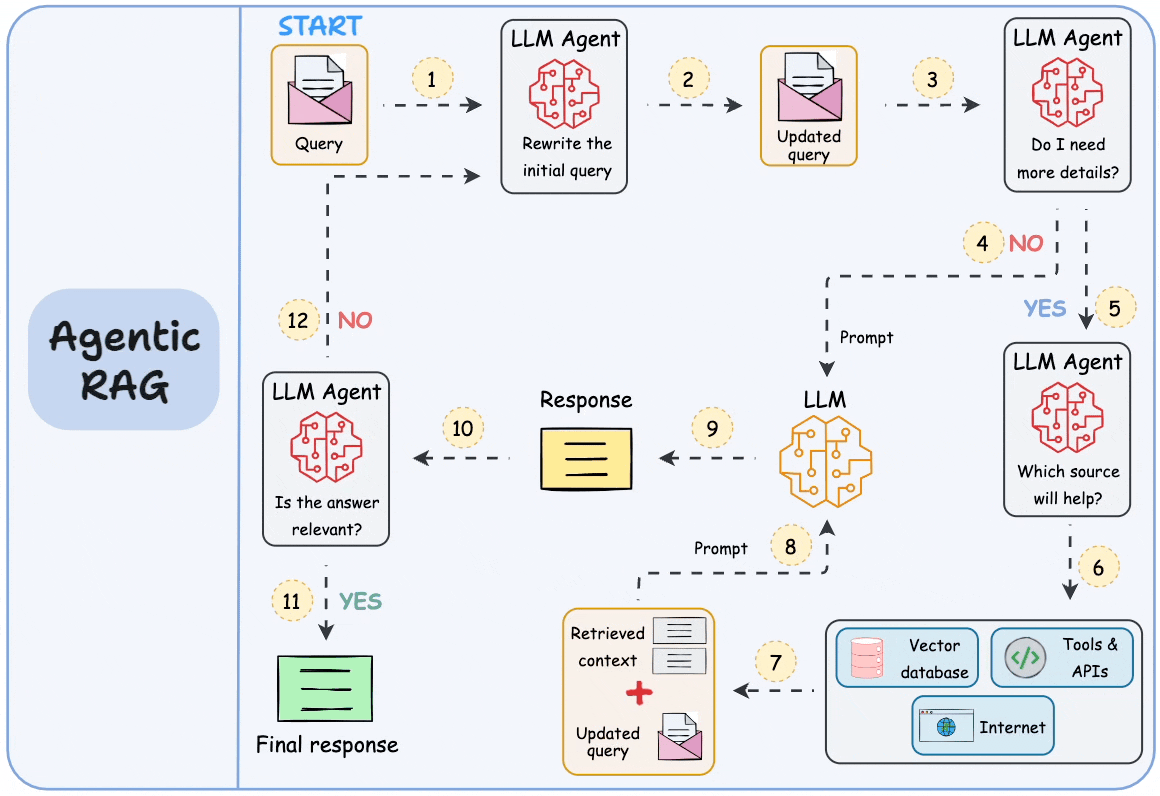
图注:智能体化 RAG 的构成。来源:Daily Dose of Data Science
Caption: The anatomy of agentic RAG. Source: Daily Dose of Data Science
{kind=link}
RAG 的主要用例有哪些?
What are the top use cases of RAG?
RAG 几乎适用于所有需要 LLM 基于特定、最新或专有信息回答问题的领域:
RAG is applicable across virtually every domain where an LLM needs to answer questions grounded in specific, up-to-date, or proprietary information:
- 企业知识管理:从政策文件、HR 手册、操作手册和内部维基中回答员工问题。
Enterprise knowledge management: Answering employee questions from policy documents, HR handbooks, runbooks, and internal wikis.
- 客户支持:为聊天机器人和虚拟助手提供动力,从产品文档、常见问题解答和案例历史中获取信息。
Customer support: Powering chatbots and virtual agents that draw from product documentation, FAQs, and case history.
- 数据与分析问答:通过从数据目录或语义层检索上下文,帮助分析师查询指标、定义和仪表板。
Data and analytics Q&A: Helping analysts query metrics, definitions, and dashboards by retrieving context from a data catalog or semantic layer.
- 法律与合规:从法规文件、合同和政策框架中综合答案,并提供完整引用。
Legal and compliance: Synthesizing answers from regulatory documents, contracts, and policy frameworks with full citations.
- 金融研究:从财报电话会议、分析师报告和市场数据中提取见解,并提供可追溯的来源。
Financial research: Surfacing insights from earnings calls, analyst reports, and market data with traceable sourcing.
- 医疗保健与生命科学:检索临床指南、试验数据和医学文献,以支持护理团队的决策。
Healthcare and life sciences: Retrieving clinical guidelines, trial data, and medical literature to support care team decisions.
RAG 的最大优势是什么?
What are the biggest benefits of RAG?
与单独使用 LLM 或仅依赖微调进行领域适应相比,RAG 带来了可衡量的业务和技术优势:
RAG delivers measurable business and technical advantages over using LLMs alone or relying solely on fine-tuning for domain adaptation:
- 减少幻觉:通过将生成过程锚定在检索到的证据上,RAG 显著降低了捏造输出的比率。
Reduced hallucinations: By anchoring generation in retrieved evidence, RAG significantly lowers the rate of fabricated outputs.
- 成本低于微调:微调大型模型需要大量计算资源,并且每次知识更新都需要重新训练周期。RAG 将知识与模型权重分离,这意味着知识库的更新不需要重新训练。
Lower cost than fine-tuning: Fine-tuning large models requires significant compute and retraining cycles every time knowledge changes. RAG separates knowledge from model weights, meaning updates to the knowledge base do not require retraining.
- 输出始终最新:因为 RAG 在推理时从实时知识源(如企业上下文层)检索,所以响应能反映当前的政策、指标和文档。
Always-current outputs: Because RAG retrieves from a live knowledge source (like an enterprise context layer) at inference time, responses reflect current policies, metrics, and documentation.
- 可审计性与可信度:每个 RAG 响应都可以追溯到特定的源文档或数据资产,为合规、法律和治理团队提供了可验证的证据链。
Auditability and trust: Every RAG response can be traced back to specific source documents or data assets, giving compliance, legal, and governance teams a verifiable chain of evidence.
- 更快实现价值:团队可以通过整理知识库来构建特定领域的 AI 应用,而无需数月的微调基础设施或大量的机器学习开销。
Faster time to value: Teams can build domain-specific AI applications by curating a knowledge base, without months of fine-tuning infrastructure or significant ML overhead.
RAG 的核心组件是什么?
What are the core components of RAG?
一个生产级的 RAG 系统由多个相互连接的组件组成,每个组件在端到端流水线中承担不同的功能。
A production RAG system is composed of several interconnected components, each contributing a distinct function to the end-to-end pipeline.
知识索引
Knowledge index
知识索引是任何 RAG 系统的基础。它是检索器在查询时从中提取相关内容的结构化存储库。索引的质量直接决定了模型能够检索到什么,进而决定了它能够生成什么。
The knowledge index is the foundation of any RAG system. It is the structured repository from which the retriever draws relevant content at query time. The quality of the index directly determines the quality of what the model can retrieve and therefore the quality of what it generates.
一个设计良好的知识索引包括:
A well-designed knowledge index includes:
- 文档语料库:原始源材料,包括 PDF、Confluence 页面、数据库记录、API 响应和结构化表格。
Document corpus: Raw source material including PDFs, Confluence pages, database records, API responses, and structured tables.
- 分块策略:将长文档分割成可检索片段的方法,需要在粒度和连贯性之间取得平衡。
Chunking strategy: The method by which long documents are split into retrievable segments, balancing granularity against coherence.
- 嵌入向量:每个分块的向量表示,由嵌入模型生成,用于捕获语义含义以进行相似性搜索。
Embeddings: Vector representations of each chunk, generated by an embedding model, capturing semantic meaning for similarity search.
- 元数据:附加到每个分块的所有权、数据域、敏感度分类、创建日期和血缘信息,支持过滤和受控的检索。
Metadata: Ownership, data domain, sensitivity classification, creation date, and lineage information attached to each chunk, enabling filtered and governed retrieval.
对于企业部署,当知识索引由提供语义丰富、访问控制的元数据(而不仅仅是原始文档)的治理上下文层支持时,其功能最为强大。
For enterprise deployments, the knowledge index is most powerful when backed by a governed context layer that provides semantically enriched, access-controlled metadata rather than raw documents alone.
生成器
Generator (LLM)
生成器是产生最终响应的大语言模型。它接收一个提示,该提示包含原始用户查询加上经过筛选的检索上下文,并将其综合成一个连贯、可引用的答案。
The generator is the large language model that produces the final response. It receives a prompt consisting of the original user query plus the curated, retrieved context and synthesizes this into a coherent, citable answer.
现代 RAG 架构使用生成器进行查询重写、自我评估和纠正性重新检索。
Modern RAG architectures use the generator for query rewriting, self-evaluation, and corrective re-retrieval.
RAG 如何工作?架构与工作流概述
How does RAG work? Architecture and workflow overview
高层架构概览
High-level architecture at a glance
从高层来看,RAG 系统在两个不同的阶段运行:离线索引阶段(准备知识库)和在线推理阶段(实时回答查询)。
At a high level, a RAG system operates in two distinct phases: an offline indexing phase where the knowledge base is prepared, and an online inference phase where queries are answered in real time.
索引阶段是文档被摄取、分块、嵌入并与丰富的元数据一起存储在向量或混合索引中的阶段。此阶段的质量决定了一切后续步骤。像 Atlan 的元数据湖仓这样的平台,可以作为上下文丰富的知识存储,供索引流水线从中提取数据,它不仅提供原始文档,还提供经过丰富、治理、语义链接的元数据,这使得检索的精确度显著提高。
The indexing phase is where documents are ingested, chunked, embedded, and stored alongside rich metadata in a vector or hybrid index. The quality of this phase determines everything that follows. Platforms like Atlan’s metadata lakehouse serve as the context-rich knowledge store that the indexing pipeline draws from, providing not just raw documents but enriched, governed, semantically linked metadata that makes retrieval significantly more precise.
推理阶段是用户查询触发检索、重排序和生成依次进行的阶段。每个步骤都依赖于前一步骤的质量,这就是为什么在索引阶段进行上下文工程已成为 2026 年 RAG 优化的主要焦点。
The inference phase is where a user query triggers retrieval, reranking, and generation in sequence. Each step depends on the quality of the previous one, which is why context engineering at the indexing stage has become the dominant focus of RAG optimization in 2026.
逐步工作流
Step-by-step workflow
以下是完整的 RAG 请求在系统中流动的过程:
Here is how
常见问题(FAQ)
RAG的主要优势是什么?
RAG的主要优势在于无需昂贵地重新训练大语言模型,即可通过连接外部知识源,生成准确、最新且可审计的响应,有效解决LLM知识过时和幻觉问题。
RAG的核心组件有哪些?
RAG的核心组件包括知识索引(用于存储和检索外部信息)和生成器(即大语言模型),两者协同工作,在生成响应前将检索到的信息注入模型上下文。
RAG有哪些主要的技术类型?
主要技术类型包括朴素RAG(基础模式)、高级RAG(增加检索前后优化步骤)和模块化RAG(灵活可组合的流水线),适用于不同复杂度的用例需求。
版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。
文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。
若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。