RAG知识库如何用问答对替代文档切片来提升准确率?

This article presents an innovative RAG (Retrieval Augmented Generation) knowledge base solution that replaces traditional document chunking with storing "question-answer pairs," significantly improving answer accuracy from 60% to 95%. It details the technical architecture, deployment strategies, and practical solutions to common pitfalls like version management and cross-page knowledge fragmentation.
原文翻译: 本文介绍了一种创新的RAG(检索增强生成)知识库解决方案,用存储“问答对”取代传统的文档切片方法,将回答准确率从60%显著提升至95%。文章详细阐述了技术架构、部署策略,并提供了针对版本管理和跨页知识点割裂等常见问题的实用解决方案。
Farewell to Document Chunking: A Q&A Pair Approach to Boost RAG Knowledge Base Accuracy to 95%
引言:RAG 知识库的机遇与核心挑战
Introduction: The Opportunity and Core Challenge of RAG Knowledge Bases
AI 浪潮正席卷全球,各行各业都在积极探索其落地应用。无论是为了提升工作效率,还是展现技术前瞻性,技术先行者们都在寻找有效的切入点。在众多 AI 应用场景中,检索增强生成(Retrieval Augmented Generation, RAG)知识库因其技术相对成熟且能快速体现 AI 价值,已成为企业优先考虑的方案之一。
The wave of AI is sweeping across the globe, with industries actively exploring its practical applications. Whether aiming to enhance work efficiency or demonstrate technological foresight, technical pioneers are seeking effective entry points. Among the various AI application scenarios, Retrieval Augmented Generation (RAG) knowledge bases have become a priority for many enterprises due to their relative technical maturity and ability to quickly demonstrate AI value.
RAG 知识库的核心目标是让 AI 能够针对用户提出的、基于特定知识领域的问题,给出精准的回答。其应用场景非常广泛,例如:
The core objective of a RAG knowledge base is to enable AI to provide accurate answers to user questions based on a specific domain of knowledge. Its application scenarios are broad, including:
- 内部员工问答:解答企业规章制度、工作流程等问题。
- Internal Employee Q&A: Answering questions about company policies, work procedures, etc.
- 智能客服:为客户提供产品或服务的专业咨询。
- Intelligent Customer Service: Providing professional consultation on products or services for customers.
- 产品文档助手:帮助用户快速查找产品使用说明、常见问题解答(FAQ)等。
- Product Documentation Assistant: Helping users quickly find product manuals, FAQs, etc.
市面上已有大量关于搭建 RAG 系统的技术方案。本文将不赘述基础实现细节,而是聚焦于 RAG 实践中的一个关键痛点:如何设计数据预处理方案,才能最大限度地提升最终问答的准确率? 本文将分享我们团队在实践中总结的一套高效技术方案。
There are numerous technical solutions available for building RAG systems. This article will not elaborate on basic implementation details but will focus on a key pain point in RAG practice: How to design a data preprocessing scheme to maximize the accuracy of final Q&A? This article shares an efficient technical approach summarized by our team through practical experience.
传统文档切片方案的局限性
Limitations of Traditional Document Chunking Schemes
目前主流的 RAG 知识库构建流程是:将文档(如帮助手册)切分成多个较小的文本块(切片),将这些切片转换为向量并存入数据库。当用户提问时,系统检索出最相关的几个切片,将其作为上下文提供给大语言模型(LLM)以生成答案。
The mainstream RAG knowledge base construction process is: splitting documents (e.g., help manuals) into multiple smaller text blocks (chunks), converting these chunks into vectors and storing them in a database. When a user asks a question, the system retrieves the most relevant chunks and provides them as context to the Large Language Model (LLM) to generate an answer.
这种方式虽然直观,但存在固有缺陷,严重影响回答的准确性:
Although intuitive, this approach has inherent flaws that significantly impact answer accuracy:
1. 版本管理难题
1. The Challenge of Version Management
企业文档往往存在多个版本。不同用户可能期望 AI 基于特定版本的文档进行回答。如果将所有版本的文档内容混合切片并存储,不仅大幅增加存储和计算成本,更容易导致 AI 混淆上下文,给出包含过时或冲突信息的答案。
Enterprise documents often have multiple versions. Different users may expect AI to answer based on a specific version of the document. If content from all versions is mixed, chunked, and stored, it not only significantly increases storage and computational costs but also更容易 causes AI to confuse context, providing answers containing outdated or conflicting information.
2. 跨页/跨段知识点割裂
2. Fragmentation of Cross-Page/Cross-Section Knowledge Points
当一个完整的知识点恰好位于切片边界时(例如,概念解释始于第 10 页末尾,终于第 11 页开头),它会被强行分割到两个独立的切片中。这种割裂导致 AI 在单次检索中无法获得该知识点的完整信息,从而可能生成不完整或错误的答案。
When a complete knowledge point happens to fall on a chunk boundary (e.g., a concept explanation starts at the end of page 10 and ends at the beginning of page 11), it is forcibly split into two independent chunks. This fragmentation prevents AI from obtaining complete information about that knowledge point in a single retrieval, potentially leading to incomplete or incorrect answers.
为了更清晰地对比传统方案与我们提出的方案,其核心差异如下表所示:
To more clearly compare the traditional scheme with our proposed scheme, their core differences are shown in the following table:
| 对比维度 | 传统文档切片方案 | 本文提出的问答对方案 |
|---|---|---|
| 存储单元 | 文档片段 (Chunk) | 结构化问答对 (Q&A Pair) |
| 数据来源 | 原始文档直接分割 | LLM 从文档提炼生成 |
| 版本管理 | 困难,易混淆 | 容易,可为每个问答对标注版本 |
| 知识点完整性 | 可能被割裂 | 保持完整 |
| 检索匹配度 | 依赖片段与问题的语义相似度 | 直接匹配“问题”,精准度更高 |
| 回答生成 | LLM 需综合多个片段生成 | LLM 可直接优化预设“答案” |
核心解决方案:转向问答对存储
Core Solution: Shifting to Q&A Pair Storage
我们的方案颠覆了主流做法:摒弃直接对原始文档进行切片,转而将知识库内容构建并存储为结构化的“问答对(Q&A Pairs)”。
Our solution颠覆es the mainstream approach: Abandon direct chunking of raw documents, and instead construct and store knowledge base content as structured "Q&A Pairs."
其基本思想是:用户使用知识库的最终形式是提问。因此,如果我们向量数据库中存储的本身就是从文档中提炼出的、预期用户会询问的“问题”及其对应的“标准答案”,那么在进行语义检索时,系统能更精准地匹配到用户意图。
The basic idea is: the ultimate form of user interaction with a knowledge base is asking questions. Therefore, if what we store in the vector database are "questions" anticipated from users and their corresponding "standard answers" distilled from the documents, the system can more accurately match user intent during semantic retrieval.
方案优势
Advantages of the Scheme
- 更高的检索匹配度:直接使用“问题”进行向量化存储和匹配,更贴近用户的真实查询方式,显著提升召回率和相关性。
- Higher Retrieval Match Rate: Using "questions" directly for vectorized storage and matching aligns more closely with users' actual query methods, significantly improving recall and relevance.
- 彻底避免内容割裂:每个问答对都是一个语义完整的独立单元,天然解决了传统切片导致的上下文断裂问题。
- Completely Avoids Content Fragmentation: Each Q&A pair is a semantically complete independent unit, naturally solving the context breakage issue caused by traditional chunking.
- 实现完美的版本管理:可以为每个问答对附加明确的版本号属性。当用户指定或系统识别出版本上下文时,可精准过滤并检索对应版本的答案,确保回答的时效性和准确性。
- Achieves Perfect Version Management: Each Q&A pair can be attached with a clear version number attribute. When a user specifies or the system identifies a version context, it can precisely filter and retrieve answers from the corresponding version, ensuring timeliness and accuracy.
落地实践:关键挑战与应对策略
Practical Implementation: Key Challenges and Countermeasures
尽管问答对方案在理论上优势明显,但在实际落地中仍需解决一系列具体问题。
Although the Q&A pair scheme has obvious theoretical advantages, a series of specific problems still need to be solved in practical implementation.
1. 如何处理非文本内容(图片、附件)?
1. How to Handle Non-Text Content (Images, Attachments)?
在传统方案中,图片和附件随文档一起被切片和处理。在问答对方案中,我们建议采用“元数据关联”策略:在存储问答对时,利用其元数据字段(如 metadata)来保存相关图片、附件的存储路径、链接或唯一标识符。
In the traditional scheme, images and attachments are chunked and processed along with the document. In the Q&A pair scheme, we recommend a "metadata association" strategy: when storing a Q&A pair, use its metadata field (e.g.,
metadata) to save the storage path, link, or unique identifier of related images and attachments.
为何不直接存入答案文本?
Why Not Embed Directly into the Answer Text?
- 保证答案纯度与质量:问答对是生成准确回答的核心。保持答案文本的简洁与独立,避免被冗长的 Base64 编码或描述污染,有利于 LLM 理解和生成。
- Ensure Answer Purity and Quality: Q&A pairs are the core for generating accurate answers. Keeping the answer text concise and independent, avoiding pollution by lengthy Base64 codes or descriptions, facilitates LLM understanding and generation.
- 便于后期维护:当图片需要更新时,只需更新元数据中的链接,无需触动或重新向量化核心的问答对内容,维护性更佳。
- Facilitates Later Maintenance: When an image needs updating, only the link in the metadata needs to be updated, without touching or re-vectorizing the core Q&A pair content, offering better maintainability.
2. 如何利用大语言模型生成高质量的问答对?
2. How to Use Large Language Models to Generate High-Quality Q&A Pairs?
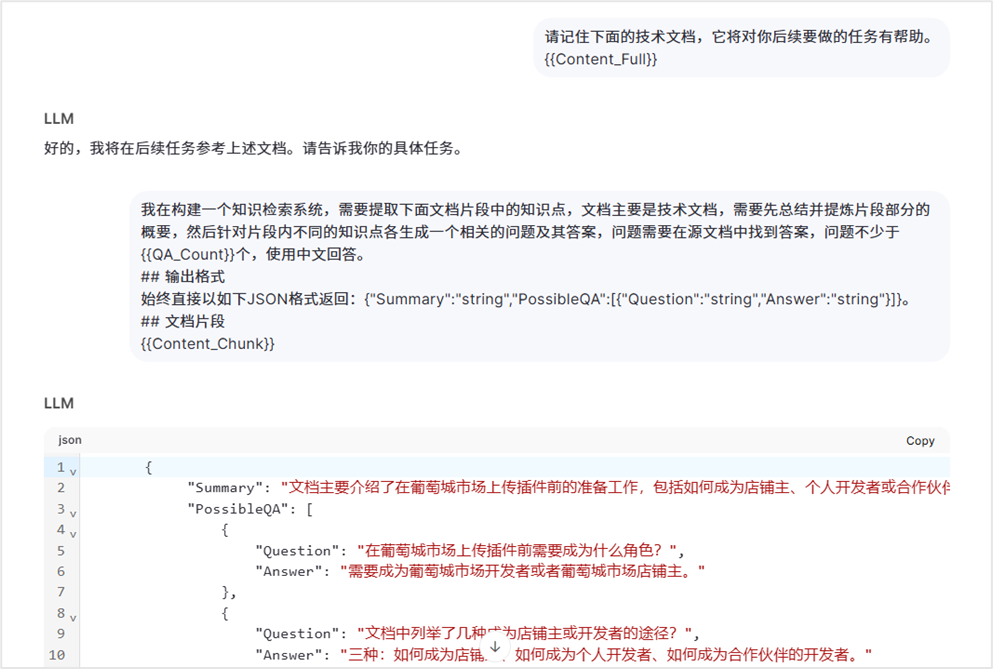
这是本方案成功的关键步骤。我们的流程是:将文档提供给 LLM,并通过精心设计的提示词(Prompt)指导其基于文档内容生成一系列问答对。
This is a crucial step for the success of this scheme. Our process is: provide the document to the LLM and guide it through carefully designed prompts to generate a series of Q&A pairs based on the document content.
提示词优化技巧:节省上下文成本
Prompt Optimization Technique: Saving Context Cost
在实际操作中,为了生成符合要求的问答对,可能需要与 LLM 进行多轮对话,这会产生额外的上下文 Token 成本。我们采用一个技巧来优化:在单次对话中,通过模拟对话历史的方式,将复杂的指令“包装”起来,让 LLM 在单轮交互中完成原本需要多轮交互的任务,从而有效降低 API 调用成本。
In practice, generating Q&A pairs that meet requirements may require multiple rounds of dialogue with the LLM, incurring additional context token costs. We employ a technique for optimization: within a single conversation, by simulating conversation history, complex instructions are "packaged" to allow the LLM to complete tasks that originally required multiple rounds of interaction in a single round, effectively reducing API call costs.
生成内容摘要(Summary):在提示词中,可以要求 LLM 为生成的问答对同时创建一个简短的摘要。这个摘要可以存入元数据,在后续检索时提供额外的语义信息,有助于提升检索精度和回答生成速度。
Generate Content Summary: In the prompt, you can ask the LLM to also create a brief summary for the generated Q&A pairs. This summary can be stored in metadata, providing additional semantic information during subsequent retrieval, helping to improve retrieval precision and answer generation speed.
3. 问答对的存储结构设计
3. Q&A Pair Storage Structure Design
一个完整的问答对存储单元应包含核心内容与丰富的元数据,以支持高效检索和精准回答。其结构示例如下:
A complete Q&A pair storage unit should include core content and rich metadata to support efficient retrieval and precise answering. An example of its structure is as follows:
| 字段名 (Field) | 说明 (Description) | 用途 (Purpose) |
|---|---|---|
| id | 唯一标识符 | 主键,用于管理 |
| question | 问题文本 | 核心向量化字段,用于语义检索 |
| answer | 答案文本 | 核心内容,用于生成最终回复 |
| version | 文档版本号 | 实现精准的版本控制 |
| summary | 内容摘要 | 辅助检索与理解 |
| metadata | 元数据 (JSON) | 存储来源、图片链接、标签等 |
| embedding | 问题文本的向量 | 向量检索使用 |
Field Name Description Purpose id Unique Identifier Primary key, for management question Question Text Core vectorization field, for semantic retrieval answer Answer Text Core content, for generating final response version Document Version Number Enables precise version control summary Content Summary Assists retrieval and understanding metadata Metadata (JSON) Stores source, image links, tags, etc. embedding Vector of Question Text Used for vector retrieval

技术架构与部署方案
Technical Architecture and Deployment Plan
系统架构
System Architecture
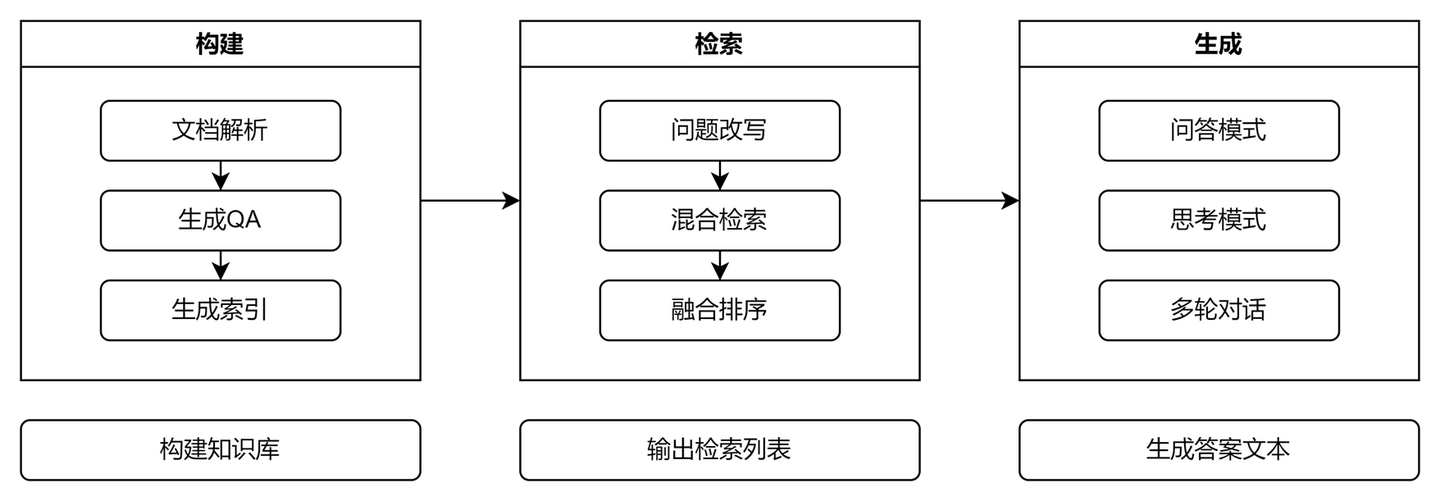
我们的 RAG 系统围绕以下三个核心环节构建:
Our RAG system is built around the following three core stages:
- 构建 (Build) - ETL 管道:负责从原始文档中提取、转换、加载数据。核心是将文档通过 LLM 转化为结构化的问答对,并进行向量化。
- Build - ETL Pipeline: Responsible for extracting, transforming, and loading data from source documents. The core is converting documents into structured Q&A pairs via LLM and performing vectorization.
- 检索 (Retrieve) - 混合检索器:结合向量检索(基于
question字段)和关键词检索(可选),并使用如 RRF(Reciprocal Rank Fusion)等算法对结果进行重排序,以提升召回质量。- Retrieve - Hybrid Retriever: Combines vector retrieval (based on the
questionfield) and keyword retrieval (optional), and uses algorithms like RRF (Reciprocal Rank Fusion) to re-rank results, improving recall quality.
- Retrieve - Hybrid Retriever: Combines vector retrieval (based on the
- 生成 (Generate) - 智能生成器:将检索到的最优问答对(包括其答案、元数据等)作为上下文,输入给 LLM。我们采用“问答模式”让 LLM 直接优化输出答案,并可引入“思考链(Chain-of-Thought)”模式处理复杂问题。
- Generate - Intelligent Generator: Feeds the retrieved optimal Q&A pairs (including their answers, metadata, etc.) as context to the LLM. We use a "Q&A mode" to let the LLM directly optimize the output answer, and can introduce a "Chain-of-Thought" mode to handle complex problems.
部署方案
Deployment Plan
在数据存储层,我们采用混合数据库策略以发挥各自优势:
At the data storage layer, we adopt a hybrid database strategy to leverage their respective advantages:
| 数据库 | 类型 | 在本方案中的职责 | 优点 |
|---|---|---|---|
| Qdrant / Pinecone / Weaviate | 向量数据库 | 存储和高效检索问答对中 question 字段的向量。 | 专为向量相似性搜索优化,性能高。 |
MySQL
常见问题(FAQ)RAG知识库用问答对存储比文档切片好在哪?问答对存储将回答准确率从60%提升至95%,解决了传统切片导致的跨页知识点割裂和版本管理混乱问题,让AI能基于完整、版本明确的知识点生成答案。 RAG问答对方案如何处理图片附件等非文本内容?方案在落地实践中专门考虑了非文本内容的处理策略,确保知识库能全面覆盖各类资料,这是传统文档切片方案难以系统解决的技术挑战之一。 转向问答对存储后,部署时要注意什么?文章详细阐述了技术架构和部署策略,并提供了针对版本管理、跨页知识割裂等常见问题的实用解决方案,确保方案能平稳高效落地。 版权与免责声明:本文仅用于信息分享与交流,不构成任何形式的法律、投资、医疗或其他专业建议,也不构成对任何结果的承诺或保证。 文中提及的商标、品牌、Logo、产品名称及相关图片/素材,其权利归各自合法权利人所有。本站内容可能基于公开资料整理,亦可能使用 AI 辅助生成或润色;我们尽力确保准确与合规,但不保证完整性、时效性与适用性,请读者自行甄别并以官方信息为准。 若本文内容或素材涉嫌侵权、隐私不当或存在错误,请相关权利人/当事人联系本站,我们将及时核实并采取删除、修正或下架等处理措施。 也请勿在评论或联系信息中提交身份证号、手机号、住址等个人敏感信息。 |