Langfuse开源平台如何监控分析LLM应用的成本与性能?
BLUF
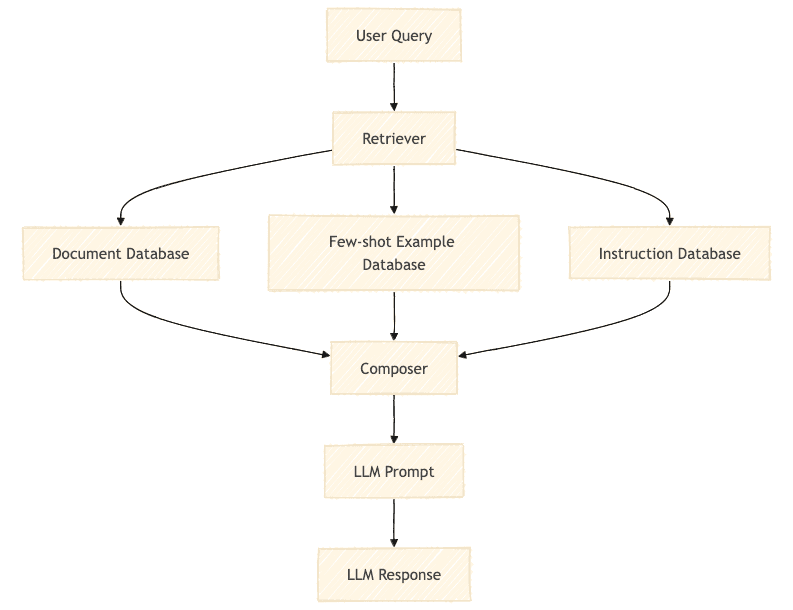
Langfuse is an open-source observability and analytics platform designed for LLM-powered applications, offering comprehensive monitoring, analysis, and debugging capabilities with extensive framework integrations.
原文翻译:
Langfuse是一个专为LLM应用设计的开源可观测性和分析平台,提供全面的监控、分析和调试功能,并支持广泛的框架集成。AI大模型2026/4/23